Speculative Speech Recognition by Audio-Prefixed Low-Rank Adaptation of Language Models

0

Sign in to get full access
Overview
- Introduces a new method for improving automatic speech recognition (ASR) using audio-prefixed low-rank adaptation of language models.
- Explores speculative speech recognition, where the system predicts likely text outputs before audio input is complete.
- Focuses on enhancing the language model component of ASR systems.
Plain English Explanation
The paper discusses a new technique to improve automatic speech recognition (ASR). ASR systems convert audio recordings of speech into written text. The key innovation is using "audio-prefixed low-rank adaptation" to enhance the language model, which is responsible for predicting likely text outputs.
Typically, ASR systems process audio input and then use a language model to predict the most probable text output. This paper explores "speculative speech recognition", where the system tries to predict likely text before the full audio input is available. By adapting the language model using a small amount of audio data, the system can make more accurate predictions about the text, improving overall ASR performance.
The low-rank adaptation technique modifies the language model parameters in a targeted way, requiring less data and computation compared to retraining the entire model. This makes the approach efficient and practical for real-world ASR applications.
Technical Explanation
The paper introduces a novel method for audio-prefixed low-rank adaptation of language models to enable speculative speech recognition. The key elements are:
-
Speculative Speech Recognition: The system predicts likely text outputs before the complete audio input is available, allowing faster and more accurate transcription.
-
Audio-Prefixed Adaptation: The language model is adapted using a small amount of audio data, capturing acoustic information to improve text predictions.
-
Low-Rank Adaptation: The language model parameters are updated in a targeted, low-dimensional subspace, requiring less data and computation compared to full retraining.
The authors demonstrate the effectiveness of their approach through experiments on benchmark ASR datasets, showing significant improvements in transcription accuracy and latency compared to standard techniques.
Critical Analysis
The paper presents a compelling approach to enhancing ASR systems by leveraging audio information to adapt language models. The authors acknowledge several limitations and areas for future work:
- The low-rank adaptation technique may not capture all relevant acoustic information, suggesting further research into more sophisticated adaptation methods.
- The experiments focus on English, and the approach may require further validation for other languages with different linguistic characteristics.
- The impact of speculative recognition on downstream applications, such as real-time captioning or voice-based user interfaces, is not thoroughly explored.
Additionally, one could question the scalability of the approach, particularly for large-scale, multi-domain language models that are increasingly common in modern ASR systems. The computational and memory overhead of the low-rank adaptation process may pose challenges in such scenarios.
Conclusion
This paper introduces a novel technique for improving automatic speech recognition by using audio-prefixed low-rank adaptation of language models. By incorporating acoustic information into the language model, the system can make more accurate text predictions, enabling faster and more reliable transcription. The low-rank adaptation approach is efficient and practical, making it a promising direction for enhancing ASR performance in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Speculative Speech Recognition by Audio-Prefixed Low-Rank Adaptation of Language Models
Bolaji Yusuf, Murali Karthick Baskar, Andrew Rosenberg, Bhuvana Ramabhadran
This paper explores speculative speech recognition (SSR), where we empower conventional automatic speech recognition (ASR) with speculation capabilities, allowing the recognizer to run ahead of audio. We introduce a metric for measuring SSR performance and we propose a model which does SSR by combining a RNN-Transducer-based ASR system with an audio-prefixed language model (LM). The ASR system transcribes ongoing audio and feeds the resulting transcripts, along with an audio-dependent prefix, to the LM, which speculates likely completions for the transcriptions. We experiment with a variety of ASR datasets on which show the efficacy our method and the feasibility of SSR as a method of reducing ASR latency.
Read more7/8/2024
0
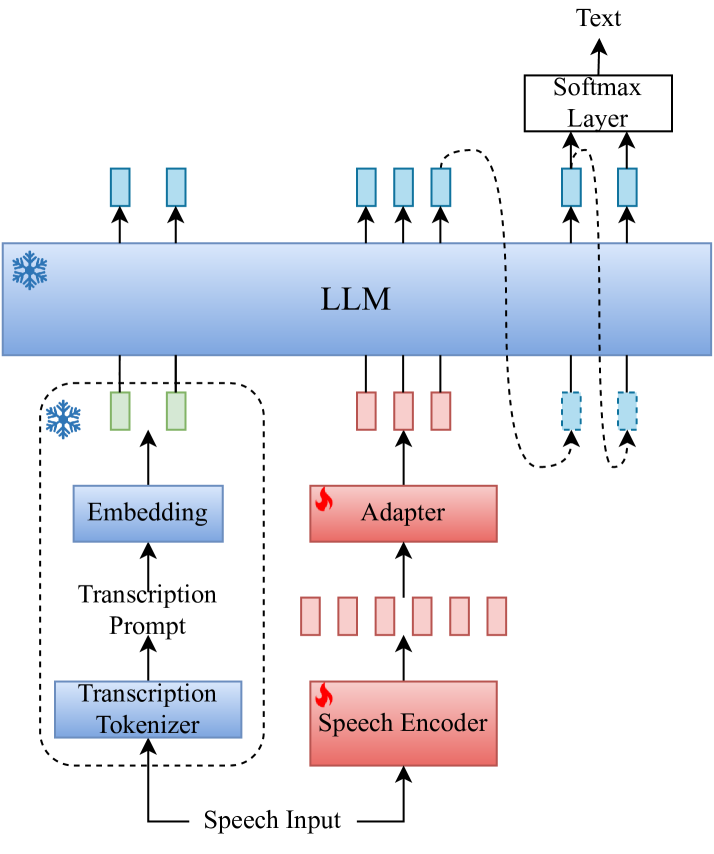
A Transcription Prompt-based Efficient Audio Large Language Model for Robust Speech Recognition
Yangze Li, Xiong Wang, Songjun Cao, Yike Zhang, Long Ma, Lei Xie
Audio-LLM introduces audio modality into a large language model (LLM) to enable a powerful LLM to recognize, understand, and generate audio. However, during speech recognition in noisy environments, we observed the presence of illusions and repetition issues in audio-LLM, leading to substitution and insertion errors. This paper proposes a transcription prompt-based audio-LLM by introducing an ASR expert as a transcription tokenizer and a hybrid Autoregressive (AR) Non-autoregressive (NAR) decoding approach to solve the above problems. Experiments on 10k-hour WenetSpeech Mandarin corpus show that our approach decreases 12.2% and 9.6% CER relatively on Test_Net and Test_Meeting evaluation sets compared with baseline. Notably, we reduce the decoding repetition rate on the evaluation set to zero, showing that the decoding repetition problem has been solved fundamentally.
Read more8/20/2024
🗣️
0
Speech Recognition Rescoring with Large Speech-Text Foundation Models
Prashanth Gurunath Shivakumar, Jari Kolehmainen, Aditya Gourav, Yi Gu, Ankur Gandhe, Ariya Rastrow, Ivan Bulyko
Large language models (LLM) have demonstrated the ability to understand human language by leveraging large amount of text data. Automatic speech recognition (ASR) systems are often limited by available transcribed speech data and benefit from a second pass rescoring using LLM. Recently multi-modal large language models, particularly speech and text foundational models have demonstrated strong spoken language understanding. Speech-Text foundational models leverage large amounts of unlabelled and labelled data both in speech and text modalities to model human language. In this work, we propose novel techniques to use multi-modal LLM for ASR rescoring. We also explore discriminative training to further improve the foundational model rescoring performance. We demonstrate cross-modal knowledge transfer in speech-text LLM can benefit rescoring. Our experiments demonstrate up-to 20% relative improvements over Whisper large ASR and up-to 15% relative improvements over text-only LLM.
Read more9/26/2024
0
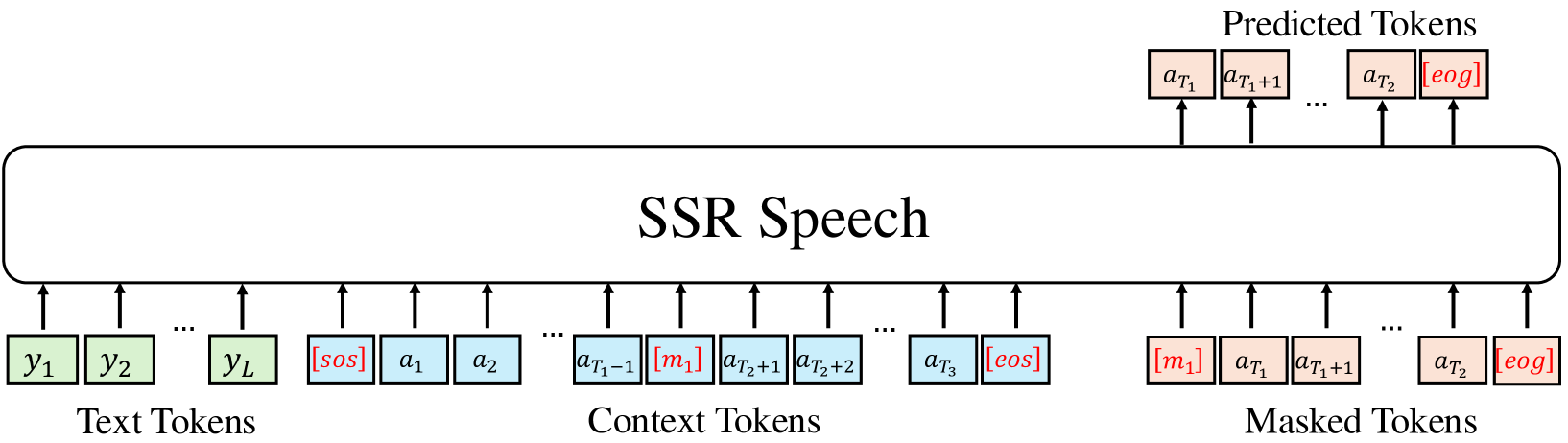
SSR-Speech: Towards Stable, Safe and Robust Zero-shot Text-based Speech Editing and Synthesis
Helin Wang, Meng Yu, Jiarui Hai, Chen Chen, Yuchen Hu, Rilin Chen, Najim Dehak, Dong Yu
In this paper, we introduce SSR-Speech, a neural codec autoregressive model designed for stable, safe, and robust zero-shot text-based speech editing and text-to-speech synthesis. SSR-Speech is built on a Transformer decoder and incorporates classifier-free guidance to enhance the stability of the generation process. A watermark Encodec is proposed to embed frame-level watermarks into the edited regions of the speech so that which parts were edited can be detected. In addition, the waveform reconstruction leverages the original unedited speech segments, providing superior recovery compared to the Encodec model. Our approach achieves the state-of-the-art performance in the RealEdit speech editing task and the LibriTTS text-to-speech task, surpassing previous methods. Furthermore, SSR-Speech excels in multi-span speech editing and also demonstrates remarkable robustness to background sounds. Source code and demos are released.
Read more9/14/2024