SSR-Speech: Towards Stable, Safe and Robust Zero-shot Text-based Speech Editing and Synthesis

0
Sign in to get full access
Overview
- Proposes a new neural speech editing and synthesis system called SSR-Speech that can perform stable, safe, and robust zero-shot text-based speech editing and synthesis
- Aims to address issues with existing text-to-speech and speech editing systems, such as lack of control, instability, and potential for generating harmful or inappropriate content
- Leverages a watermark-based approach to ensure safe and stable speech editing and synthesis
Plain English Explanation
The paper introduces a new system called SSR-Speech that can edit and generate speech based on text input. This is a challenging task, as existing text-to-speech and speech editing systems often lack control, stability, and the ability to avoid generating harmful or inappropriate content.
SSR-Speech aims to address these issues by using a watermark-based approach. This means the system embeds a special code or "watermark" into the generated speech, which helps ensure the output is stable, safe, and robust. The watermark acts as a safeguard, allowing the system to detect and prevent the generation of potentially problematic content.
The key innovation is that SSR-Speech can perform zero-shot text-based speech editing and synthesis. This means the system can manipulate and generate speech without requiring any audio samples from the target speaker. It can take text as input and produce edited or synthesized speech, all while maintaining the stability and safety controls provided by the watermark.
Technical Explanation
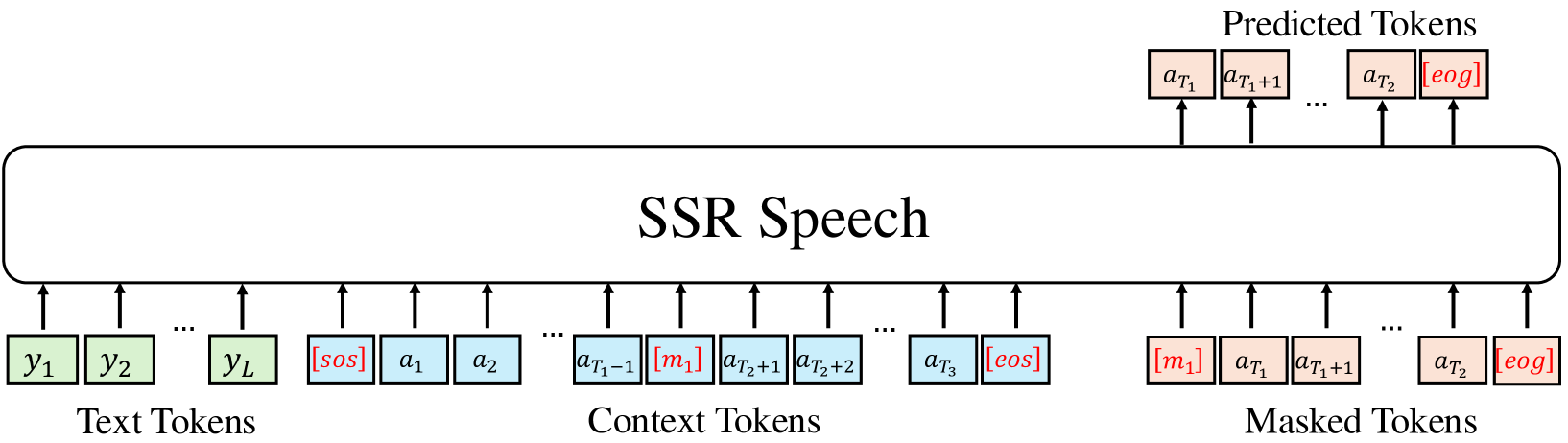
The paper presents the SSR-Speech system, which is built on a neural codec model trained in an autoregressive manner. This allows the system to leverage the powerful language modeling capabilities of large language models while also generating high-quality audio.
The core of the system is a watermark-based approach that embeds a special code into the generated speech. This watermark serves as a safeguard, enabling the system to detect and prevent the generation of potentially harmful or inappropriate content. The watermark is designed to be stable and robust, ensuring the system's outputs remain safe and controlled.
The researchers evaluate SSR-Speech's performance on a range of text-to-speech and speech editing tasks, including zero-shot voice conversion and text-based speech manipulation. The results show that the system can achieve state-of-the-art performance while maintaining strong stability and safety guarantees, a significant improvement over existing approaches.
Critical Analysis
The paper presents a compelling solution to the challenges of text-based speech editing and synthesis, particularly the need for stable, safe, and robust systems. The watermark-based approach is a novel and promising idea that could help address issues like the potential for generating harmful content.
However, the paper does not delve into the technical details of how the watermark is implemented or how it is used to detect and prevent problematic outputs. More information on the watermark's design and the specific mechanisms for ensuring safety and stability would be valuable.
Additionally, the paper does not discuss the potential limitations or drawbacks of the watermark-based approach. It would be helpful to understand any potential trade-offs or edge cases where the system might still struggle to maintain the desired level of control and safety.
Further research could explore the scalability of the SSR-Speech system, its robustness to adversarial attacks, and its applicability to a broader range of speech-related tasks beyond text-to-speech and speech editing.
Conclusion
The SSR-Speech system presented in this paper represents an important step towards stable, safe, and robust text-based speech editing and synthesis. By leveraging a watermark-based approach, the system can generate high-quality speech while maintaining strong control and safety guarantees, a significant improvement over existing methods.
This work has the potential to enable more reliable and trustworthy speech-related applications, such as voice assistants, text-to-speech systems, and speech editing tools. The principles and techniques introduced in this paper could also inspire further innovations in the field of speech technology, ultimately leading to more powerful and responsible systems that can benefit society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SSR-Speech: Towards Stable, Safe and Robust Zero-shot Text-based Speech Editing and Synthesis
Helin Wang, Meng Yu, Jiarui Hai, Chen Chen, Yuchen Hu, Rilin Chen, Najim Dehak, Dong Yu
In this paper, we introduce SSR-Speech, a neural codec autoregressive model designed for stable, safe, and robust zero-shot text-based speech editing and text-to-speech synthesis. SSR-Speech is built on a Transformer decoder and incorporates classifier-free guidance to enhance the stability of the generation process. A watermark Encodec is proposed to embed frame-level watermarks into the edited regions of the speech so that which parts were edited can be detected. In addition, the waveform reconstruction leverages the original unedited speech segments, providing superior recovery compared to the Encodec model. Our approach achieves the state-of-the-art performance in the RealEdit speech editing task and the LibriTTS text-to-speech task, surpassing previous methods. Furthermore, SSR-Speech excels in multi-span speech editing and also demonstrates remarkable robustness to background sounds. Source code and demos are released.
Read more9/14/2024
0
LiveSpeech: Low-Latency Zero-shot Text-to-Speech via Autoregressive Modeling of Audio Discrete Codes
Trung Dang, David Aponte, Dung Tran, Kazuhito Koishida
Prior works have demonstrated zero-shot text-to-speech by using a generative language model on audio tokens obtained via a neural audio codec. It is still challenging, however, to adapt them to low-latency scenarios. In this paper, we present LiveSpeech - a fully autoregressive language model-based approach for zero-shot text-to-speech, enabling low-latency streaming of the output audio. To allow multiple token prediction within a single decoding step, we propose (1) using adaptive codebook loss weights that consider codebook contribution in each frame and focus on hard instances, and (2) grouping codebooks and processing groups in parallel. Experiments show our proposed models achieve competitive results to state-of-the-art baselines in terms of content accuracy, speaker similarity, audio quality, and inference speed while being suitable for low-latency streaming applications.
Read more6/11/2024
🧠
0
SpeechX: Neural Codec Language Model as a Versatile Speech Transformer
Xiaofei Wang, Manthan Thakker, Zhuo Chen, Naoyuki Kanda, Sefik Emre Eskimez, Sanyuan Chen, Min Tang, Shujie Liu, Jinyu Li, Takuya Yoshioka
Recent advancements in generative speech models based on audio-text prompts have enabled remarkable innovations like high-quality zero-shot text-to-speech. However, existing models still face limitations in handling diverse audio-text speech generation tasks involving transforming input speech and processing audio captured in adverse acoustic conditions. This paper introduces SpeechX, a versatile speech generation model capable of zero-shot TTS and various speech transformation tasks, dealing with both clean and noisy signals. SpeechX combines neural codec language modeling with multi-task learning using task-dependent prompting, enabling unified and extensible modeling and providing a consistent way for leveraging textual input in speech enhancement and transformation tasks. Experimental results show SpeechX's efficacy in various tasks, including zero-shot TTS, noise suppression, target speaker extraction, speech removal, and speech editing with or without background noise, achieving comparable or superior performance to specialized models across tasks. See https://aka.ms/speechx for demo samples.
Read more6/27/2024

0
Speculative Speech Recognition by Audio-Prefixed Low-Rank Adaptation of Language Models
Bolaji Yusuf, Murali Karthick Baskar, Andrew Rosenberg, Bhuvana Ramabhadran
This paper explores speculative speech recognition (SSR), where we empower conventional automatic speech recognition (ASR) with speculation capabilities, allowing the recognizer to run ahead of audio. We introduce a metric for measuring SSR performance and we propose a model which does SSR by combining a RNN-Transducer-based ASR system with an audio-prefixed language model (LM). The ASR system transcribes ongoing audio and feeds the resulting transcripts, along with an audio-dependent prefix, to the LM, which speculates likely completions for the transcriptions. We experiment with a variety of ASR datasets on which show the efficacy our method and the feasibility of SSR as a method of reducing ASR latency.
Read more7/8/2024