Speech After Gender: A Trans-Feminine Perspective on Next Steps for Speech Science and Technology

0

Sign in to get full access
Overview
- This paper discusses the challenges and considerations around speech technology and science from a trans-feminine perspective.
- It argues for the need to move beyond a binary view of gender in speech research and technology development.
- The paper highlights areas where current practices and assumptions in speech science and technology can be harmful or exclusionary to transgender and non-binary individuals.
- It proposes several next steps and recommendations to make speech technology and science more inclusive and responsive to the needs of the transgender community.
Plain English Explanation
Speech technology and the scientific research behind it have historically been developed with a binary view of gender - the assumption that people's voices can be neatly categorized as either male or female. However, this fails to account for the experiences and needs of transgender and non-binary individuals, whose voices may not fit into this simplistic male-female dichotomy.
This paper provides a trans-feminine perspective on the limitations of current speech science and technology, and offers suggestions for how the field can evolve to become more inclusive and affirming. For example, the authors argue that voice training and voice modification tools should move beyond a focus on conforming to traditional gender norms, and instead empower individuals to express their true vocal identity.
The paper also highlights the potential harms that can arise when speech AI and biometric technologies are developed without considering the nuances of gender identity. Voice-based gender prediction models, for instance, may misgender transgender individuals and deny them access to certain services or technologies.
Overall, the key message is that the speech science and technology community needs to adopt a more expansive, gender-inclusive approach that centers the lived experiences of transgender and non-binary people. This will require rethinking fundamental assumptions, research practices, and design priorities in order to create speech technologies that are truly accessible and empowering for all.
Technical Explanation
The paper begins by providing an overview of the current state of speech science and technology, highlighting how the field has historically been dominated by a binary view of gender. The authors argue that this narrow perspective fails to account for the diverse experiences and needs of transgender and non-binary individuals.
The paper then reviews relevant prior work, including research on voice disorder analysis using transformer-based approaches, efforts to develop unified speech-to-speech frameworks that preserve speaker identity, and studies examining semantic gender bias in speech systems. While these works begin to grapple with some of the complexities around gender and speech, the authors argue that a more fundamental shift in perspective is needed.
The core of the paper outlines several key recommendations for the speech science and technology community:
- Adopt a more expansive, gender-inclusive model that moves beyond the male-female binary. This could involve incorporating articulatory phonetics to enable more controllable and expressive speech synthesis.
- Center the voices and lived experiences of transgender and non-binary individuals in research and development.
- Rethink the goals and design priorities of speech technologies, shifting away from a focus on gender conformity and toward empowering individuals to express their authentic vocal identity.
- Carefully consider the potential harms and unintended consequences of speech technologies, especially when they involve biometric analysis or gender classification.
Throughout the paper, the authors ground their arguments in real-world examples and personal narratives to illustrate the challenges faced by transgender and non-binary individuals in the context of speech science and technology.
Critical Analysis
The paper raises important and well-justified concerns about the limitations of current speech science and technology, particularly around the field's reliance on a binary view of gender. The authors present a compelling case for the need to adopt a more expansive, gender-inclusive approach that centers the experiences of transgender and non-binary individuals.
One potential limitation of the paper is that it does not provide detailed technical solutions or a roadmap for how the speech science and technology community can practically implement the recommended changes. While the authors outline the key principles and priorities that should guide future research and development, more specificity on implementation strategies and evaluation methods would strengthen the paper's impact.
Additionally, the paper could have further explored the potential tensions or trade-offs that may arise when attempting to balance the needs and preferences of different stakeholders (e.g., transgender/non-binary individuals, cisgender individuals, commercial interests, regulatory bodies, etc.) in the design of speech technologies. A more nuanced discussion of these challenges could help readers better understand the complexities involved in realizing the authors' vision.
Overall, the paper offers a valuable and much-needed perspective that should spur important discussions and concrete actions within the speech science and technology community. By heeding the authors' call for a more inclusive and gender-affirming approach, the field can work towards developing speech technologies that better serve the diverse needs of all individuals.
Conclusion
This paper provides a trans-feminine perspective on the shortcomings of current speech science and technology, and outlines key steps the community should take to make the field more inclusive and responsive to the needs of transgender and non-binary individuals.
The authors argue that the field's historical reliance on a binary view of gender has resulted in speech technologies that can be harmful or exclusionary to those outside the male-female dichotomy. To address this, the paper recommends adopting a more expansive, gender-inclusive model, centering the voices and experiences of transgender and non-binary individuals, rethinking the goals and design priorities of speech technologies, and carefully considering the potential harms of biometric and gender classification tools.
By heeding these recommendations, the speech science and technology community can work towards developing voice-based systems and solutions that empower all individuals to express their authentic vocal identity, regardless of their gender identity or expression. This shift in perspective and practice has the potential to make speech technologies more accessible, inclusive, and affirming for people of all backgrounds.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Speech After Gender: A Trans-Feminine Perspective on Next Steps for Speech Science and Technology
Robin Netzorg, Alyssa Cote, Sumi Koshin, Klo Vivienne Garoute, Gopala Krishna Anumanchipalli
As experts in voice modification, trans-feminine gender-affirming voice teachers have unique perspectives on voice that confound current understandings of speaker identity. To demonstrate this, we present the Versatile Voice Dataset (VVD), a collection of three speakers modifying their voices along gendered axes. The VVD illustrates that current approaches in speaker modeling, based on categorical notions of gender and a static understanding of vocal texture, fail to account for the flexibility of the vocal tract. Utilizing publicly-available speaker embeddings, we demonstrate that gender classification systems are highly sensitive to voice modification, and speaker verification systems fail to identify voices as coming from the same speaker as voice modification becomes more drastic. As one path towards moving beyond categorical and static notions of speaker identity, we propose modeling individual qualities of vocal texture such as pitch, resonance, and weight.
Read more7/11/2024
🔮
0
Voice Passing : a Non-Binary Voice Gender Prediction System for evaluating Transgender voice transition
David Doukhan, Simon Devauchelle, Lucile Girard-Monneron, M'ia Ch'avez Ruz, V. Chaddouk, Isabelle Wagner, Albert Rilliard
This paper presents a software allowing to describe voices using a continuous Voice Femininity Percentage (VFP). This system is intended for transgender speakers during their voice transition and for voice therapists supporting them in this process. A corpus of 41 French cis- and transgender speakers was recorded. A perceptual evaluation allowed 57 participants to estimate the VFP for each voice. Binary gender classification models were trained on external gender-balanced data and used on overlapping windows to obtain average gender prediction estimates, which were calibrated to predict VFP and obtained higher accuracy than $F_0$ or vocal track length-based models. Training data speaking style and DNN architecture were shown to impact VFP estimation. Accuracy of the models was affected by speakers' age. This highlights the importance of style, age, and the conception of gender as binary or not, to build adequate statistical representations of cultural concepts.
Read more4/24/2024

0
Voice Disorder Analysis: a Transformer-based Approach
Alkis Koudounas, Gabriele Ciravegna, Marco Fantini, Giovanni Succo, Erika Crosetti, Tania Cerquitelli, Elena Baralis
Voice disorders are pathologies significantly affecting patient quality of life. However, non-invasive automated diagnosis of these pathologies is still under-explored, due to both a shortage of pathological voice data, and diversity of the recording types used for the diagnosis. This paper proposes a novel solution that adopts transformers directly working on raw voice signals and addresses data shortage through synthetic data generation and data augmentation. Further, we consider many recording types at the same time, such as sentence reading and sustained vowel emission, by employing a Mixture of Expert ensemble to align the predictions on different data types. The experimental results, obtained on both public and private datasets, show the effectiveness of our solution in the disorder detection and classification tasks and largely improve over existing approaches.
Read more6/24/2024
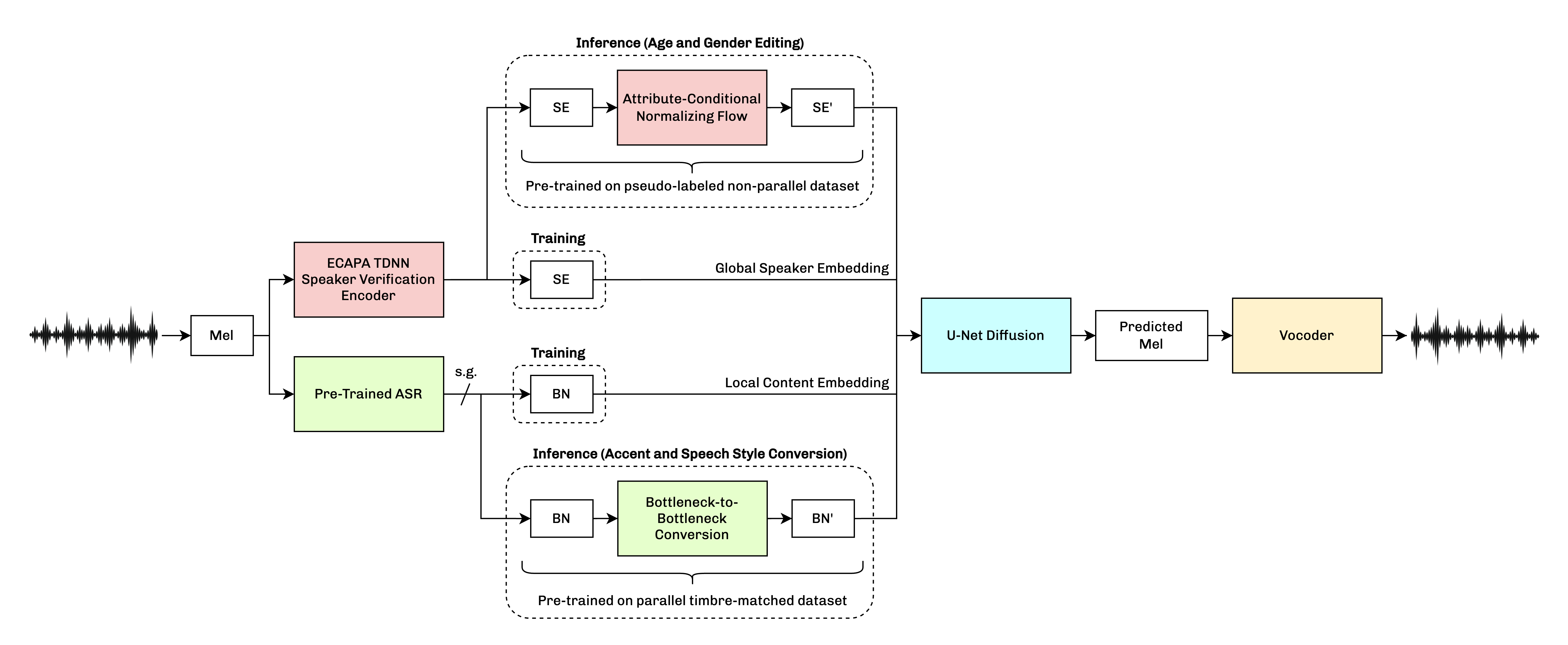
0
VoiceShop: A Unified Speech-to-Speech Framework for Identity-Preserving Zero-Shot Voice Editing
Philip Anastassiou, Zhenyu Tang, Kainan Peng, Dongya Jia, Jiaxin Li, Ming Tu, Yuping Wang, Yuxuan Wang, Mingbo Ma
We present VoiceShop, a novel speech-to-speech framework that can modify multiple attributes of speech, such as age, gender, accent, and speech style, in a single forward pass while preserving the input speaker's timbre. Previous works have been constrained to specialized models that can only edit these attributes individually and suffer from the following pitfalls: the magnitude of the conversion effect is weak, there is no zero-shot capability for out-of-distribution speakers, or the synthesized outputs exhibit undesirable timbre leakage. Our work proposes solutions for each of these issues in a simple modular framework based on a conditional diffusion backbone model with optional normalizing flow-based and sequence-to-sequence speaker attribute-editing modules, whose components can be combined or removed during inference to meet a wide array of tasks without additional model finetuning. Audio samples are available at url{https://voiceshopai.github.io}.
Read more4/12/2024