Articulatory Phonetics Informed Controllable Expressive Speech Synthesis

0
Sign in to get full access
Overview
- This paper introduces GTR-Voice, a dataset and model for controlling expressive speech synthesis using articulatory phonetics.
- The model aims to enable more expressive and controllable text-to-speech by incorporating information about how speech sounds are produced in the human vocal tract.
- The authors demonstrate the effectiveness of their approach through perceptual evaluations and comparisons to other state-of-the-art text-to-speech models.
Plain English Explanation
The researchers behind this paper have developed a new text-to-speech (TTS) system called GTR-Voice that can generate more expressive and controllable speech. Unlike traditional TTS models that focus solely on the acoustic properties of speech, GTR-Voice also incorporates information about how speech sounds are physically produced in the human vocal tract.
By modeling the complex movements and configurations of the lips, tongue, and other articulators involved in speech, the researchers are able to create more natural and expressive synthetic voices. This allows for fine-grained control over factors like emotion, emphasis, and speaking style, going beyond the limitations of past TTS approaches.
The key innovation here is the use of "articulatory phonetics" - the study of how speech sounds are formed by the articulatory organs. Instead of just looking at the acoustic output, GTR-Voice models the underlying physical processes that give rise to different speech sounds. This provides a more holistic and physiologically-grounded representation of speech production.
The researchers have also compiled a new dataset, called the GTR-Voice dataset, which contains high-quality recordings of expressive speech paired with detailed articulatory measurements. This allows the model to be trained on real-world examples of how the vocal tract movements relate to expressive speech.
Through perceptual evaluations, the authors demonstrate that their GTR-Voice model outperforms other state-of-the-art TTS systems in terms of naturalness, expressiveness, and controllability. This represents an important step forward in making synthetic speech more human-like and customizable to users' needs.
Technical Explanation
The core of the GTR-Voice system is a deep learning architecture that jointly models the acoustic and articulatory aspects of speech production. The model takes in text input and generates not only the corresponding audio waveform, but also a predicted trajectory of articulatory feature values over time.
These articulatory features, such as lip rounding, tongue position, and vocal tract constriction, are derived from a physiologically-based parametric representation of the vocal tract. By explicitly modeling these low-level articulatory dynamics, the GTR-Voice system is able to generate speech with more nuanced expressive capabilities compared to typical sequence-to-sequence TTS models.
To enable this articulatory control, the authors leveraged the GTR-Voice dataset, a new multi-speaker corpus of expressive speech recordings paired with electromagnetic articulography (EMA) data. The EMA sensors track the real-time movements of the articulators during speech production, providing a rich source of training data for the model.
The GTR-Voice architecture builds upon prior work in phonetic-enhanced language modeling for text-to-speech and emphatic and expressive text-to-speech. It incorporates a hierarchical encoder-decoder structure, where the high-level linguistic input is first processed through phoneme and prosody prediction modules before being passed to the articulatory and acoustic generation components.
Through extensive perceptual evaluations, the authors demonstrate that GTR-Voice outperforms other state-of-the-art TTS systems, including StoryTTS, in terms of naturalness, expressiveness, and controllability. This suggests that the articulatory-aware modeling approach is a promising direction for creating more human-like and customizable synthetic speech.
Critical Analysis
The key strength of the GTR-Voice system is its ability to generate expressive speech through the explicit modeling of articulatory dynamics. By incorporating physiological information about how speech sounds are produced, the model can create more nuanced and controllable synthetic voices compared to traditional TTS approaches.
However, one potential limitation is the reliance on the GTR-Voice dataset, which was collected specifically for this work. While the dataset contains high-quality recordings and articulatory measurements, it may not fully capture the full range of expressive speech found in natural human communication. Expanding the dataset with more diverse speakers, emotional states, and speaking styles could further improve the model's performance.
Additionally, the authors mention that the current GTR-Voice system requires relatively large computational resources, which could limit its deployment in resource-constrained environments. Exploring more efficient model architectures or compression techniques may be necessary to enable widespread adoption.
Finally, while the perceptual evaluations demonstrate the advantages of the articulatory-informed approach, it would be valuable to see more objective metrics of speech quality, such as intelligibility and speaker similarity, to provide a more comprehensive assessment of the system's capabilities.
Overall, the GTR-Voice work represents an exciting development in the field of expressive text-to-speech synthesis, and the authors' focus on articulatory modeling is a promising direction for creating more human-like and customizable synthetic voices.
Conclusion
The GTR-Voice paper introduces a novel text-to-speech system that leverages articulatory phonetics to generate more expressive and controllable synthetic speech. By modeling the underlying physical processes of speech production, the researchers have developed a TTS approach that can create more nuanced and customizable voices compared to traditional acoustic-only models.
The key innovations include the development of the GTR-Voice dataset, which provides a rich source of articulatory data for training the model, and the incorporation of a hierarchical encoder-decoder architecture that jointly predicts acoustic and articulatory outputs. Through perceptual evaluations, the authors demonstrate the superiority of their approach over other state-of-the-art TTS systems.
While the current GTR-Voice system shows promising results, there are opportunities for further refinement and expansion, such as incorporating a broader range of expressive speech data and improving the model's efficiency. Nonetheless, this work represents an important step forward in the quest to make synthetic speech more human-like and responsive to user needs, with potential applications in areas like assistive technology, entertainment, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Articulatory Phonetics Informed Controllable Expressive Speech Synthesis
Zehua Kcriss Li, Meiying Melissa Chen, Yi Zhong, Pinxin Liu, Zhiyao Duan
Expressive speech synthesis aims to generate speech that captures a wide range of para-linguistic features, including emotion and articulation, though current research primarily emphasizes emotional aspects over the nuanced articulatory features mastered by professional voice actors. Inspired by this, we explore expressive speech synthesis through the lens of articulatory phonetics. Specifically, we define a framework with three dimensions: Glottalization, Tenseness, and Resonance (GTR), to guide the synthesis at the voice production level. With this framework, we record a high-quality speech dataset named GTR-Voice, featuring 20 Chinese sentences articulated by a professional voice actor across 125 distinct GTR combinations. We verify the framework and GTR annotations through automatic classification and listening tests, and demonstrate precise controllability along the GTR dimensions on two fine-tuned expressive TTS models. We open-source the dataset and TTS models.
Read more6/18/2024

0
Articulatory Encodec: Vocal Tract Kinematics as a Codec for Speech
Cheol Jun Cho, Peter Wu, Tejas S. Prabhune, Dhruv Agarwal, Gopala K. Anumanchipalli
Vocal tract articulation is a natural, grounded control space of speech production. The spatiotemporal coordination of articulators combined with the vocal source shapes intelligible speech sounds to enable effective spoken communication. Based on this physiological grounding of speech, we propose a new framework of neural encoding-decoding of speech -- Articulatory Encodec. Articulatory Encodec comprises an articulatory analysis model that infers articulatory features from speech audio, and an articulatory synthesis model that synthesizes speech audio from articulatory features. The articulatory features are kinematic traces of vocal tract articulators and source features, which are intuitively interpretable and controllable, being the actual physical interface of speech production. An additional speaker identity encoder is jointly trained with the articulatory synthesizer to inform the voice texture of individual speakers. By training on large-scale speech data, we achieve a fully intelligible, high-quality articulatory synthesizer that generalizes to unseen speakers. Furthermore, the speaker embedding is effectively disentangled from articulations, which enables accent-perserving zero-shot voice conversion. To the best of our knowledge, this is the first demonstration of universal, high-performance articulatory inference and synthesis, suggesting the proposed framework as a powerful coding system of speech.
Read more8/22/2024
0
Expressivity and Speech Synthesis
Andreas Triantafyllopoulos, Bjorn W. Schuller
Imbuing machines with the ability to talk has been a longtime pursuit of artificial intelligence (AI) research. From the very beginning, the community has not only aimed to synthesise high-fidelity speech that accurately conveys the semantic meaning of an utterance, but also to colour it with inflections that cover the same range of affective expressions that humans are capable of. After many years of research, it appears that we are on the cusp of achieving this when it comes to single, isolated utterances. This unveils an abundance of potential avenues to explore when it comes to combining these single utterances with the aim of synthesising more complex, longer-term behaviours. In the present chapter, we outline the methodological advances that brought us so far and sketch out the ongoing efforts to reach that coveted next level of artificial expressivity. We also discuss the societal implications coupled with rapidly advancing expressive speech synthesis (ESS) technology and highlight ways to mitigate those risks and ensure the alignment of ESS capabilities with ethical norms.
Read more5/1/2024
0
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
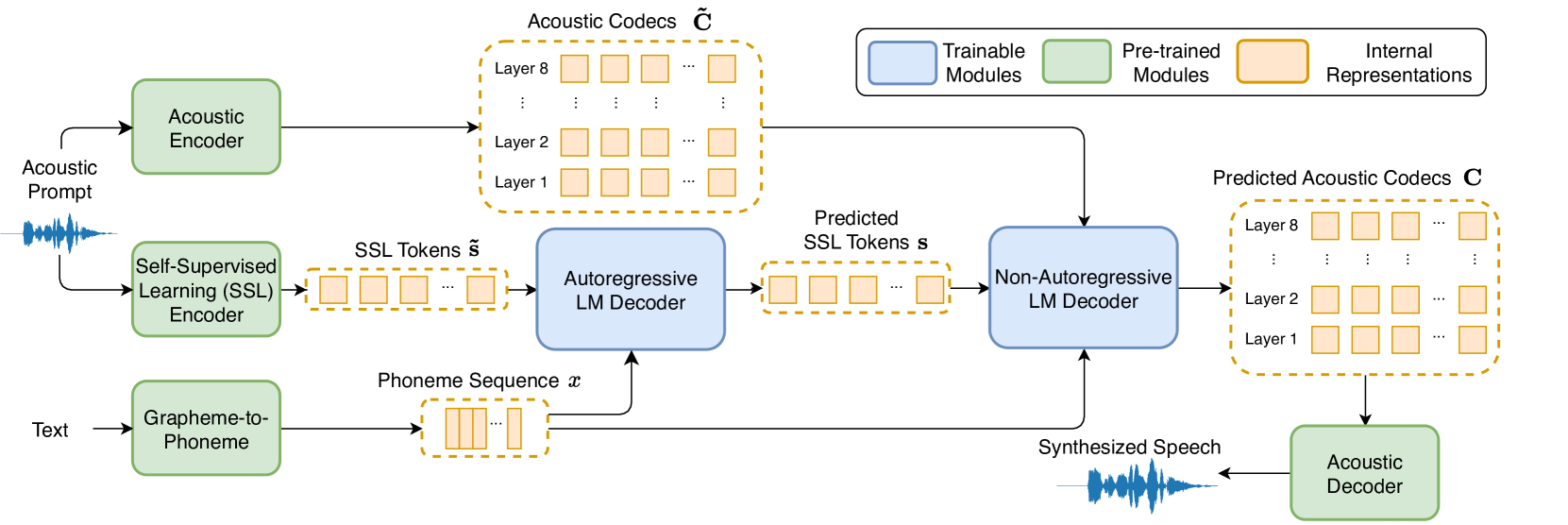
Kun Zhou, Shengkui Zhao, Yukun Ma, Chong Zhang, Hao Wang, Dianwen Ng, Chongjia Ni, Nguyen Trung Hieu, Jia Qi Yip, Bin Ma
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
Read more6/13/2024