SpeechAlign: Aligning Speech Generation to Human Preferences
2404.05600
0
0
Abstract
Speech language models have significantly advanced in generating realistic speech, with neural codec language models standing out. However, the integration of human feedback to align speech outputs to human preferences is often neglected. This paper addresses this gap by first analyzing the distribution gap in codec language models, highlighting how it leads to discrepancies between the training and inference phases, which negatively affects performance. Then we explore leveraging learning from human feedback to bridge the distribution gap. We introduce SpeechAlign, an iterative self-improvement strategy that aligns speech language models to human preferences. SpeechAlign involves constructing a preference codec dataset contrasting golden codec tokens against synthetic tokens, followed by preference optimization to improve the codec language model. This cycle of improvement is carried out iteratively to steadily convert weak models to strong ones. Through both subjective and objective evaluations, we show that SpeechAlign can bridge the distribution gap and facilitating continuous self-improvement of the speech language model. Moreover, SpeechAlign exhibits robust generalization capabilities and works for smaller models. Code and models will be available at https://github.com/0nutation/SpeechGPT.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The provided research paper discusses SpeechAlign, a method for aligning speech generation models to human preferences.
- The paper analyzes the distribution gap between machine-generated speech and human-preferred speech, and proposes techniques to bridge this gap.
- Key contributions include a preliminary analysis of the distribution gap, a fine-tuning approach to align speech generation with human preferences, and empirical evaluations of the proposed method.
Plain English Explanation
The paper focuses on the challenge of making speech generated by AI sound more natural and aligned with human preferences. There can be a noticeable difference between how AI models generate speech and how humans would prefer it to sound. The researchers wanted to understand this "distribution gap" and find ways to bridge it.
They started by analyzing the differences between machine-generated speech and human-preferred speech. This gave them insights into the key areas where the AI-generated speech was falling short. [Link to
The researchers then developed a technique called SpeechAlign to fine-tune the speech generation model and bring it closer to the human-preferred speech distribution. This involved exposing the model to examples of high-quality human speech during training, so it could learn to generate speech that sounds more natural and aligned with user preferences. [Link to
Through experiments, the team showed that SpeechAlign could significantly improve the quality and human-likeness of the generated speech compared to standard speech generation models. This suggests it's a promising approach for creating AI-powered speech that is more pleasing and natural for users to listen to. [Link to
Technical Explanation
The paper begins with a preliminary analysis to understand the distribution gap between machine-generated speech and human-preferred speech. The researchers used objective metrics like spectral distance and subjective human ratings to quantify this gap. Their analysis revealed that machine-generated speech tended to be less natural-sounding, with differences in factors like pitch, rhythm, and voice quality. [Link to
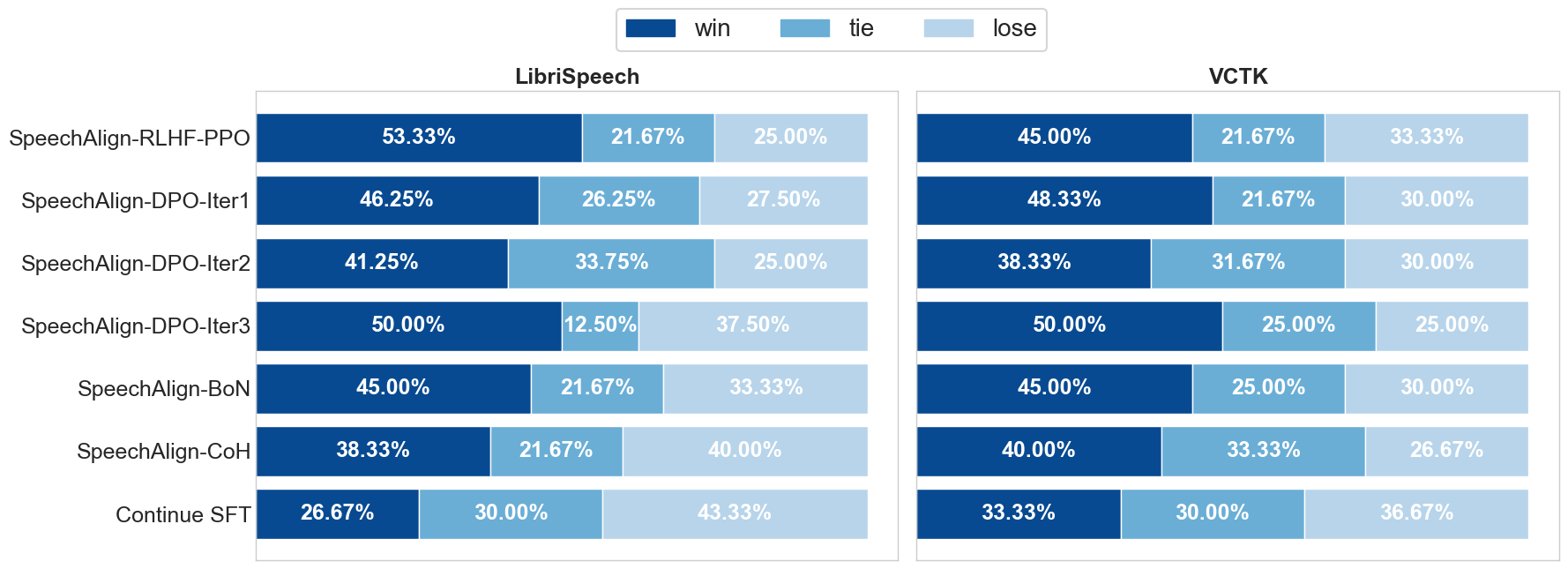
To address this, the researchers developed a fine-tuning approach called SpeechAlign. The core idea is to further train the speech generation model on high-quality human speech samples, in addition to the original training data. This exposure to human-preferred speech helps the model learn to generate output that is more aligned with human preferences.
The SpeechAlign training process involves a contrastive loss function that encourages the model to generate speech closer to the human-preferred distribution, while maintaining the original task performance. The team evaluated SpeechAlign on several benchmark datasets and showed significant improvements in speech quality and human-likeness compared to standard speech generation models. [Link to
Critical Analysis
The paper provides a thorough analysis of the distribution gap and a promising technical solution in SpeechAlign. However, the researchers acknowledge some limitations and areas for future work. For example, the evaluation was focused on objective metrics and subjective human ratings, but real-world deployment may require additional considerations around safety, bias, and ethical alignment. [Link to
Additionally, the paper does not explore how SpeechAlign might scale to larger, more complex speech generation models or handle diverse speaker characteristics and emotional tones. Further research is needed to understand the broader applicability and robustness of the proposed approach. [Link to
Overall, the SpeechAlign method represents an important step towards aligning speech generation with human preferences, but there is still work to be done to fully bridge the distribution gap and ensure the safe and responsible deployment of such technologies. [Link to
Conclusion
The SpeechAlign paper tackles the crucial challenge of making AI-generated speech sound more natural and aligned with human preferences. Through a combination of distribution gap analysis and a fine-tuning approach, the researchers demonstrated significant improvements in speech quality and human-likeness.
While there are still some limitations and areas for further exploration, this work represents an important advancement in the field of speech generation and brings us closer to AI-powered voice assistants and conversational agents that sound more human-like and pleasing to interact with. As the capabilities of speech generation models continue to evolve, continued research into alignment with human preferences will be crucial for ensuring these technologies are developed responsibly and in service of human needs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
SpeechAlign: a Framework for Speech Translation Alignment Evaluation
Belen Alastruey, Aleix Sant, Gerard I. G'allego, David Dale, Marta R. Costa-juss`a
0
0
Speech-to-Speech and Speech-to-Text translation are currently dynamic areas of research. In our commitment to advance these fields, we present SpeechAlign, a framework designed to evaluate the underexplored field of source-target alignment in speech models. The SpeechAlign framework has two core components. First, to tackle the absence of suitable evaluation datasets, we introduce the Speech Gold Alignment dataset, built upon a English-German text translation gold alignment dataset. Secondly, we introduce two novel metrics, Speech Alignment Error Rate (SAER) and Time-weighted Speech Alignment Error Rate (TW-SAER), which enable the evaluation of alignment quality within speech models. While the former gives equal importance to each word, the latter assigns weights based on the length of the words in the speech signal. By publishing SpeechAlign we provide an accessible evaluation framework for model assessment, and we employ it to benchmark open-source Speech Translation models. In doing so, we contribute to the ongoing research progress within the fields of Speech-to-Speech and Speech-to-Text translation.
4/26/2024
💬
Aligning language models with human preferences
Tomasz Korbak
0
0
Language models (LMs) trained on vast quantities of text data can acquire sophisticated skills such as generating summaries, answering questions or generating code. However, they also manifest behaviors that violate human preferences, e.g., they can generate offensive content, falsehoods or perpetuate social biases. In this thesis, I explore several approaches to aligning LMs with human preferences. First, I argue that aligning LMs can be seen as Bayesian inference: conditioning a prior (base, pretrained LM) on evidence about human preferences (Chapter 2). Conditioning on human preferences can be implemented in numerous ways. In Chapter 3, I investigate the relation between two approaches to finetuning pretrained LMs using feedback given by a scoring function: reinforcement learning from human feedback (RLHF) and distribution matching. I show that RLHF can be seen as a special case of distribution matching but distributional matching is strictly more general. In chapter 4, I show how to extend the distribution matching to conditional language models. Finally, in chapter 5 I explore a different root: conditioning an LM on human preferences already during pretraining. I show that involving human feedback from the very start tends to be more effective than using it only during supervised finetuning. Overall, these results highlight the room for alignment techniques different from and complementary to RLHF.
4/19/2024
Linear Alignment: A Closed-form Solution for Aligning Human Preferences without Tuning and Feedback
Songyang Gao, Qiming Ge, Wei Shen, Shihan Dou, Junjie Ye, Xiao Wang, Rui Zheng, Yicheng Zou, Zhi Chen, Hang Yan, Qi Zhang, Dahua Lin
0
0
The success of AI assistants based on Language Models (LLMs) hinges on Reinforcement Learning from Human Feedback (RLHF) to comprehend and align with user intentions. However, traditional alignment algorithms, such as PPO, are hampered by complex annotation and training requirements. This reliance limits the applicability of RLHF and hinders the development of professional assistants tailored to diverse human preferences. In this work, we introduce textit{Linear Alignment}, a novel algorithm that aligns language models with human preferences in one single inference step, eliminating the reliance on data annotation and model training. Linear alignment incorporates a new parameterization for policy optimization under divergence constraints, which enables the extraction of optimal policy in a closed-form manner and facilitates the direct estimation of the aligned response. Extensive experiments on both general and personalized preference datasets demonstrate that linear alignment significantly enhances the performance and efficiency of LLM alignment across diverse scenarios. Our code and dataset is published on url{https://github.com/Wizardcoast/Linear_Alignment.git}.
5/7/2024
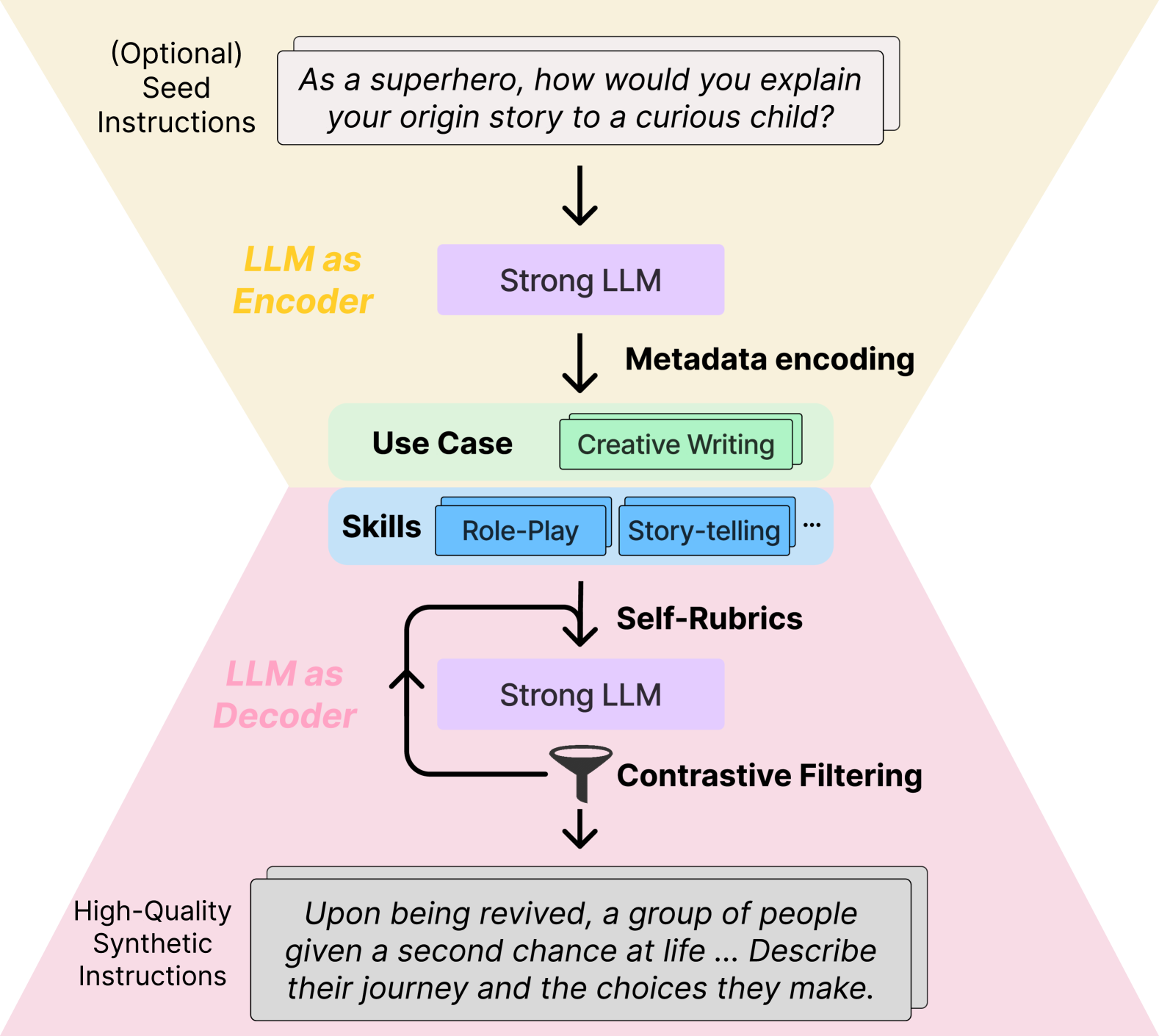
CodecLM: Aligning Language Models with Tailored Synthetic Data
Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T. Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, Tomas Pfister
0
0
Instruction tuning has emerged as the key in aligning large language models (LLMs) with specific task instructions, thereby mitigating the discrepancy between the next-token prediction objective and users' actual goals. To reduce the labor and time cost to collect or annotate data by humans, researchers start to explore the use of LLMs to generate instruction-aligned synthetic data. Recent works focus on generating diverse instructions and applying LLM to increase instruction complexity, often neglecting downstream use cases. It remains unclear how to tailor high-quality data to elicit better instruction-following abilities in different target instruction distributions and LLMs. To this end, we introduce CodecLM, a general framework for adaptively generating high-quality synthetic data for LLM alignment with different downstream instruction distributions and LLMs. Drawing on the Encode-Decode principles, we use LLMs as codecs to guide the data generation process. We first encode seed instructions into metadata, which are concise keywords generated on-the-fly to capture the target instruction distribution, and then decode metadata to create tailored instructions. We also introduce Self-Rubrics and Contrastive Filtering during decoding to tailor data-efficient samples. Extensive experiments on four open-domain instruction following benchmarks validate the effectiveness of CodecLM over the current state-of-the-arts.
4/10/2024