Aligning language models with human preferences
2404.12150
0
0
💬
Abstract
Language models (LMs) trained on vast quantities of text data can acquire sophisticated skills such as generating summaries, answering questions or generating code. However, they also manifest behaviors that violate human preferences, e.g., they can generate offensive content, falsehoods or perpetuate social biases. In this thesis, I explore several approaches to aligning LMs with human preferences. First, I argue that aligning LMs can be seen as Bayesian inference: conditioning a prior (base, pretrained LM) on evidence about human preferences (Chapter 2). Conditioning on human preferences can be implemented in numerous ways. In Chapter 3, I investigate the relation between two approaches to finetuning pretrained LMs using feedback given by a scoring function: reinforcement learning from human feedback (RLHF) and distribution matching. I show that RLHF can be seen as a special case of distribution matching but distributional matching is strictly more general. In chapter 4, I show how to extend the distribution matching to conditional language models. Finally, in chapter 5 I explore a different root: conditioning an LM on human preferences already during pretraining. I show that involving human feedback from the very start tends to be more effective than using it only during supervised finetuning. Overall, these results highlight the room for alignment techniques different from and complementary to RLHF.
Create account to get full access
Overview
- This paper discusses technical challenges in aligning large language models with human preferences and values.
- It covers several approaches to reward modeling, including using language models to model beliefs and preferences, self-alignment techniques, and RLHF practices.
- The paper also discusses the challenge of understanding the influence of the reward margin on the preference model.
Plain English Explanation
This paper looks at some of the challenges in making large language models behave in ways that align with human values and preferences. One approach it covers is using language models themselves to try to capture human beliefs, opinions, and preferences, and then using that to guide the model's behavior. Another approach is called "self-alignment", where the model tries to figure out what humans want without being explicitly told. The paper also discusses a technique called "Reward Modeling", which is about shaping the model's goals and reward functions to match human values.
One key issue the paper explores is understanding how the "reward margin" - the difference between the best and second-best actions according to the model - can impact the preference model and the model's behavior. Getting this balance right is important for ensuring the model behaves in intended ways.
Overall, the paper dives into some of the complex technical challenges involved in building AI systems that reliably do what humans want them to do. It examines different approaches researchers are exploring to try to solve these challenges.
Technical Explanation
The paper first discusses the challenge of using language models to model human beliefs, preferences, and targeted values. It explores how language models could potentially be used to capture rich representations of human preferences, which could then be used to guide the training and behavior of larger AI systems.
The paper then covers self-alignment techniques, where the AI system tries to figure out for itself what humans want, without being explicitly told. This approach aims to make the system's goals more robustly aligned with human values.
Another key focus of the paper is RLHF (Reinforcement Learning from Human Feedback), a technique for training large language models to behave in ways that match human preferences. The paper examines some of the practical challenges and techniques involved in implementing RLHF effectively.
Finally, the paper delves into the influence of the reward margin on the preference model. The reward margin - the difference in value between the best and second-best actions according to the model - can have a significant impact on the learned preference model and the model's eventual behavior. Understanding this relationship is crucial for ensuring the model behaves as intended.
Critical Analysis
The paper does a good job of highlighting some of the key technical challenges involved in aligning large language models with human preferences and values. It covers a range of different approaches, each with their own strengths and limitations.
One potential limitation is that the paper does not go into deep detail on any one approach. It provides a high-level overview of several different techniques, without diving too deeply into the specifics of how they work or their relative strengths and weaknesses. Readers looking for a more comprehensive technical understanding of these methods may need to seek out additional resources.
Additionally, the paper does not address some of the broader ethical and societal concerns around the development of such systems. While it focuses on the technical challenges, it does not explore issues around bias, transparency, or the potential misuse of these technologies. These are important considerations that warrant further discussion.
That said, the paper does a commendable job of outlining some of the key research directions in this important and rapidly evolving field. It provides a useful starting point for those interested in understanding the state of the art in AI alignment techniques.
Conclusion
This paper delves into the technical challenges of aligning large language models with human preferences and values. It examines a range of approaches, including using language models to capture human beliefs and preferences, self-alignment techniques, and reinforcement learning from human feedback.
A key focus of the paper is understanding the influence of the reward margin on the learned preference model, which is crucial for ensuring the model behaves as intended. While the paper provides a high-level overview of these techniques, it does not go into deep technical details or address broader ethical considerations.
Overall, the paper highlights the significant research efforts underway to address the complex challenge of building AI systems that reliably do what humans want them to do. As language models continue to grow more powerful, finding effective ways to align their behavior with human values will be an increasingly important and challenging endeavor.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Understanding the Learning Dynamics of Alignment with Human Feedback
Shawn Im, Yixuan Li
0
0
Aligning large language models (LLMs) with human intentions has become a critical task for safely deploying models in real-world systems. While existing alignment approaches have seen empirical success, theoretically understanding how these methods affect model behavior remains an open question. Our work provides an initial attempt to theoretically analyze the learning dynamics of human preference alignment. We formally show how the distribution of preference datasets influences the rate of model updates and provide rigorous guarantees on the training accuracy. Our theory also reveals an intricate phenomenon where the optimization is prone to prioritizing certain behaviors with higher preference distinguishability. We empirically validate our findings on contemporary LLMs and alignment tasks, reinforcing our theoretical insights and shedding light on considerations for future alignment approaches. Disclaimer: This paper contains potentially offensive text; reader discretion is advised.
4/17/2024

A Survey on Human Preference Learning for Large Language Models
Ruili Jiang, Kehai Chen, Xuefeng Bai, Zhixuan He, Juntao Li, Muyun Yang, Tiejun Zhao, Liqiang Nie, Min Zhang
0
0
The recent surge of versatile large language models (LLMs) largely depends on aligning increasingly capable foundation models with human intentions by preference learning, enhancing LLMs with excellent applicability and effectiveness in a wide range of contexts. Despite the numerous related studies conducted, a perspective on how human preferences are introduced into LLMs remains limited, which may prevent a deeper comprehension of the relationships between human preferences and LLMs as well as the realization of their limitations. In this survey, we review the progress in exploring human preference learning for LLMs from a preference-centered perspective, covering the sources and formats of preference feedback, the modeling and usage of preference signals, as well as the evaluation of the aligned LLMs. We first categorize the human feedback according to data sources and formats. We then summarize techniques for human preferences modeling and compare the advantages and disadvantages of different schools of models. Moreover, we present various preference usage methods sorted by the objectives to utilize human preference signals. Finally, we summarize some prevailing approaches to evaluate LLMs in terms of alignment with human intentions and discuss our outlooks on the human intention alignment for LLMs.
6/19/2024

On the Algorithmic Bias of Aligning Large Language Models with RLHF: Preference Collapse and Matching Regularization
Jiancong Xiao, Ziniu Li, Xingyu Xie, Emily Getzen, Cong Fang, Qi Long, Weijie J. Su
0
0
Accurately aligning large language models (LLMs) with human preferences is crucial for informing fair, economically sound, and statistically efficient decision-making processes. However, we argue that reinforcement learning from human feedback (RLHF) -- the predominant approach for aligning LLMs with human preferences through a reward model -- suffers from an inherent algorithmic bias due to its Kullback--Leibler-based regularization in optimization. In extreme cases, this bias could lead to a phenomenon we term preference collapse, where minority preferences are virtually disregarded. To mitigate this algorithmic bias, we introduce preference matching (PM) RLHF, a novel approach that provably aligns LLMs with the preference distribution of the reward model under the Bradley--Terry--Luce/Plackett--Luce model. Central to our approach is a PM regularizer that takes the form of the negative logarithm of the LLM's policy probability distribution over responses, which helps the LLM balance response diversification and reward maximization. Notably, we obtain this regularizer by solving an ordinary differential equation that is necessary for the PM property. For practical implementation, we introduce a conditional variant of PM RLHF that is tailored to natural language generation. Finally, we empirically validate the effectiveness of conditional PM RLHF through experiments on the OPT-1.3B and Llama-2-7B models, demonstrating a 29% to 41% improvement in alignment with human preferences, as measured by a certain metric, compared to standard RLHF.
5/28/2024
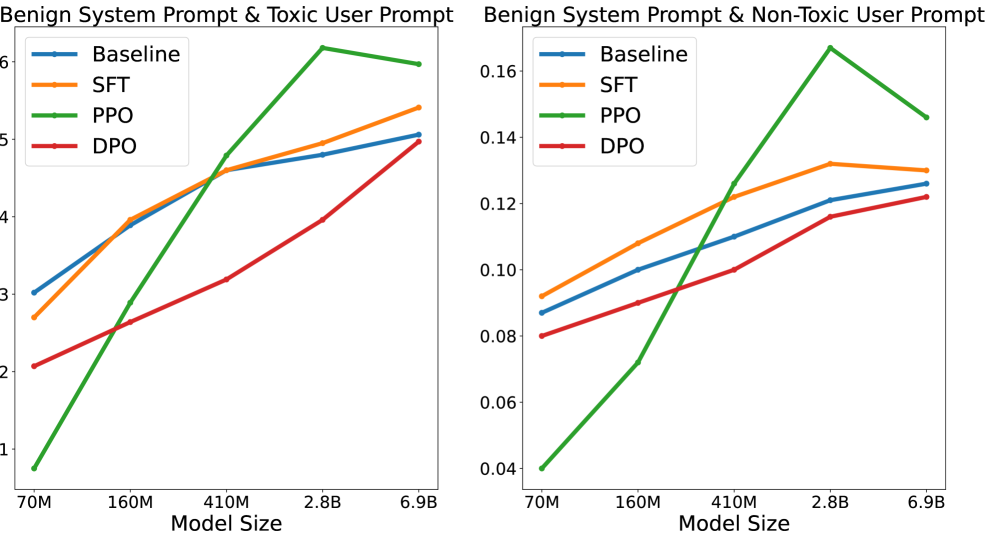
More RLHF, More Trust? On The Impact of Human Preference Alignment On Language Model Trustworthiness
Aaron J. Li, Satyapriya Krishna, Himabindu Lakkaraju
0
0
The surge in Large Language Models (LLMs) development has led to improved performance on cognitive tasks as well as an urgent need to align these models with human values in order to safely exploit their power. Despite the effectiveness of preference learning algorithms like Reinforcement Learning From Human Feedback (RLHF) in aligning human preferences, their assumed improvements on model trustworthiness haven't been thoroughly testified. Toward this end, this study investigates how models that have been aligned with general-purpose preference data on helpfulness and harmlessness perform across five trustworthiness verticals: toxicity, stereotypical bias, machine ethics, truthfulness, and privacy. For model alignment, we focus on three widely used RLHF variants: Supervised Finetuning (SFT), Proximal Policy Optimization (PPO), and Direct Preference Optimization (DPO). Through extensive empirical investigations, we discover that the improvement in trustworthiness by RLHF is far from guaranteed, and there exists a complex interplay between preference data, alignment algorithms, and specific trustworthiness aspects. Together, our results underscore the need for more nuanced approaches for model alignment. By shedding light on the intricate dynamics of these components within model alignment, we hope this research will guide the community towards developing language models that are both capable and trustworthy.
4/30/2024