Linear Alignment: A Closed-form Solution for Aligning Human Preferences without Tuning and Feedback
2401.11458
0
1
Abstract
The success of AI assistants based on Language Models (LLMs) hinges on Reinforcement Learning from Human Feedback (RLHF) to comprehend and align with user intentions. However, traditional alignment algorithms, such as PPO, are hampered by complex annotation and training requirements. This reliance limits the applicability of RLHF and hinders the development of professional assistants tailored to diverse human preferences. In this work, we introduce textit{Linear Alignment}, a novel algorithm that aligns language models with human preferences in one single inference step, eliminating the reliance on data annotation and model training. Linear alignment incorporates a new parameterization for policy optimization under divergence constraints, which enables the extraction of optimal policy in a closed-form manner and facilitates the direct estimation of the aligned response. Extensive experiments on both general and personalized preference datasets demonstrate that linear alignment significantly enhances the performance and efficiency of LLM alignment across diverse scenarios. Our code and dataset is published on url{https://github.com/Wizardcoast/Linear_Alignment.git}.
Create account to get full access
Overview
- This paper presents a novel approach called "Linear Alignment" for aligning large language models with human preferences without the need for tuning or feedback.
- The key idea is to learn a linear transformation that maps the model's outputs to human-preferred outputs, which can be computed in closed-form.
- The method aims to address limitations of existing reinforcement learning from human feedback (RLHF) approaches, such as the need for iterative tuning and the lack of theoretical guarantees.
Plain English Explanation
The paper introduces a new way to align the outputs of large language models with what humans prefer, without requiring a lot of back-and-forth tuning or feedback. The core concept is to find a simple, linear transformation that can map the model's original outputs to outputs that better match human preferences.
Imagine you have a language model that can generate text, but the text doesn't always align with what humans would want it to say. Previous approaches have tried to fix this by having humans provide feedback or corrections, and then iteratively updating the model based on that feedback. This can be seen in papers like "Privately Aligning Language Models with Reinforcement Learning", "Aligning Language Models to Human Preferences", and "Understanding the Learning Dynamics of Alignment from Human Feedback".
The new "Linear Alignment" approach aims to sidestep the need for all that back-and-forth tuning. The key idea is to find a simple, linear mathematical function that can directly transform the model's outputs into outputs that better match human preferences. This linear transformation can be computed efficiently in a single step, without requiring iterative updates or human feedback.
The researchers argue this approach has several advantages over previous methods. It's more efficient, since it avoids the need for repeated tuning cycles. And it comes with stronger theoretical guarantees about the quality of the alignment, since the linear transformation is computed in a principled way.
Technical Explanation
The paper proposes a novel "Linear Alignment" method for aligning large language models with human preferences. The key idea is to learn a linear transformation W that maps the model's original output distribution p(y|x) to a transformed distribution p'(y|x) that better matches human preferences.
The linear transformation W is computed in closed-form by solving a constrained optimization problem. The objective is to minimize the Kullback-Leibler (KL) divergence between p'(y|x) and the desired human-preferred distribution q(y|x), subject to the constraint that W is a valid linear transformation.
Formally, the optimization problem is:
min_W KL(p'(y|x) || q(y|x))
subject to p'(y|x) = W * p(y|x)
The paper shows that this optimization problem has a closed-form solution, allowing the linear transformation W to be computed efficiently without the need for iterative tuning or human feedback.
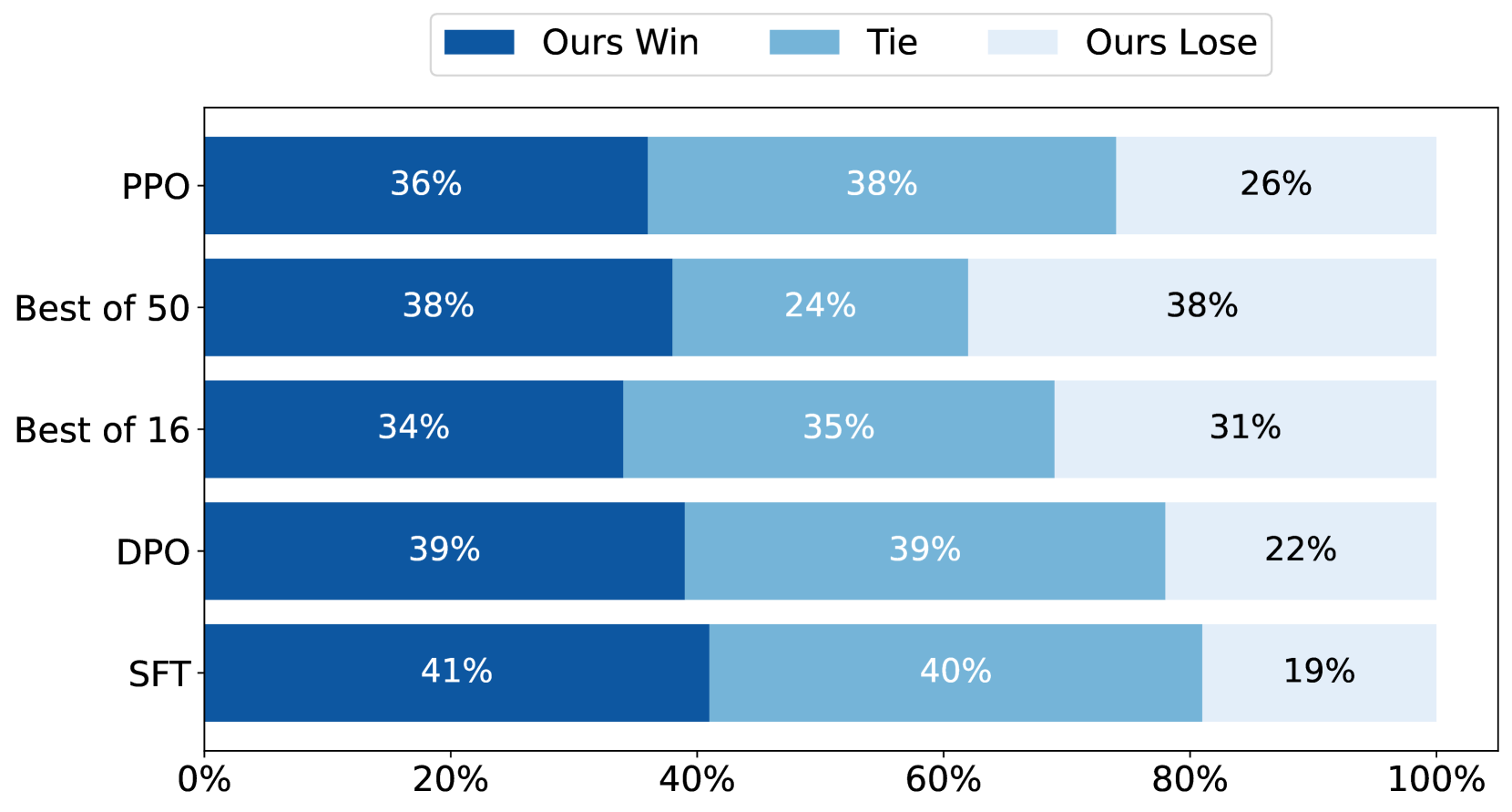
The authors compare their Linear Alignment approach to standard RLHF methods as seen in papers like "Real is Better: Aligning Large Language Models with Online Human Preferences" and "More RLHF, More Trust: The Impact of Human Preference". They demonstrate that Linear Alignment can achieve comparable alignment performance while being more computationally efficient and providing stronger theoretical guarantees.
Critical Analysis
The Linear Alignment approach presented in this paper offers a promising alternative to standard RLHF methods for aligning large language models with human preferences. The key strengths are its computational efficiency and the theoretical guarantees it provides.
However, the paper also acknowledges several important limitations and caveats. First, the method assumes the existence of a well-defined target distribution q(y|x) that accurately represents human preferences. In practice, eliciting such a distribution may be challenging, especially for complex or subjective preferences.
Additionally, the linear transformation W may not be able to capture all the nuances of human preferences, particularly if the relationship between the model's outputs and the desired outputs is highly nonlinear. The authors note that more expressive transformation functions could be explored in future work.
Another potential concern is the paper's focus on alignment in a static setting. In real-world applications, language models are often deployed in dynamic, interactive environments where human preferences may evolve over time. Extending the Linear Alignment approach to handle such non-stationary settings could be an important area for future research.
Despite these limitations, the Linear Alignment method represents an interesting and theoretically-grounded contribution to the ongoing challenge of aligning large language models with human values and preferences. As the field of AI safety and alignment continues to evolve, this work and its successors may provide valuable insights and tools for building more trustworthy and beneficial AI systems.
Conclusion
This paper introduces a novel "Linear Alignment" approach for aligning large language models with human preferences. The key innovation is a closed-form solution for learning a linear transformation that maps the model's outputs to human-preferred outputs, without the need for iterative tuning or feedback.
The authors argue that this method offers several advantages over standard reinforcement learning from human feedback (RLHF) approaches, including greater computational efficiency and stronger theoretical guarantees. While the method has some limitations, it represents an interesting and potentially valuable contribution to the ongoing challenge of building AI systems that reliably align with human values and preferences.
As the field of AI alignment continues to evolve, the techniques and insights presented in this paper may help inform the development of more trustworthy and beneficial language models and other AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Privately Aligning Language Models with Reinforcement Learning
Fan Wu, Huseyin A. Inan, Arturs Backurs, Varun Chandrasekaran, Janardhan Kulkarni, Robert Sim
0
0
Positioned between pre-training and user deployment, aligning large language models (LLMs) through reinforcement learning (RL) has emerged as a prevailing strategy for training instruction following-models such as ChatGPT. In this work, we initiate the study of privacy-preserving alignment of LLMs through Differential Privacy (DP) in conjunction with RL. Following the influential work of Ziegler et al. (2020), we study two dominant paradigms: (i) alignment via RL without human in the loop (e.g., positive review generation) and (ii) alignment via RL from human feedback (RLHF) (e.g., summarization in a human-preferred way). We give a new DP framework to achieve alignment via RL, and prove its correctness. Our experimental results validate the effectiveness of our approach, offering competitive utility while ensuring strong privacy protections.
5/6/2024
💬
Aligning language models with human preferences
Tomasz Korbak
0
0
Language models (LMs) trained on vast quantities of text data can acquire sophisticated skills such as generating summaries, answering questions or generating code. However, they also manifest behaviors that violate human preferences, e.g., they can generate offensive content, falsehoods or perpetuate social biases. In this thesis, I explore several approaches to aligning LMs with human preferences. First, I argue that aligning LMs can be seen as Bayesian inference: conditioning a prior (base, pretrained LM) on evidence about human preferences (Chapter 2). Conditioning on human preferences can be implemented in numerous ways. In Chapter 3, I investigate the relation between two approaches to finetuning pretrained LMs using feedback given by a scoring function: reinforcement learning from human feedback (RLHF) and distribution matching. I show that RLHF can be seen as a special case of distribution matching but distributional matching is strictly more general. In chapter 4, I show how to extend the distribution matching to conditional language models. Finally, in chapter 5 I explore a different root: conditioning an LM on human preferences already during pretraining. I show that involving human feedback from the very start tends to be more effective than using it only during supervised finetuning. Overall, these results highlight the room for alignment techniques different from and complementary to RLHF.
4/19/2024
SAIL: Self-Improving Efficient Online Alignment of Large Language Models
Mucong Ding, Souradip Chakraborty, Vibhu Agrawal, Zora Che, Alec Koppel, Mengdi Wang, Amrit Bedi, Furong Huang
0
0
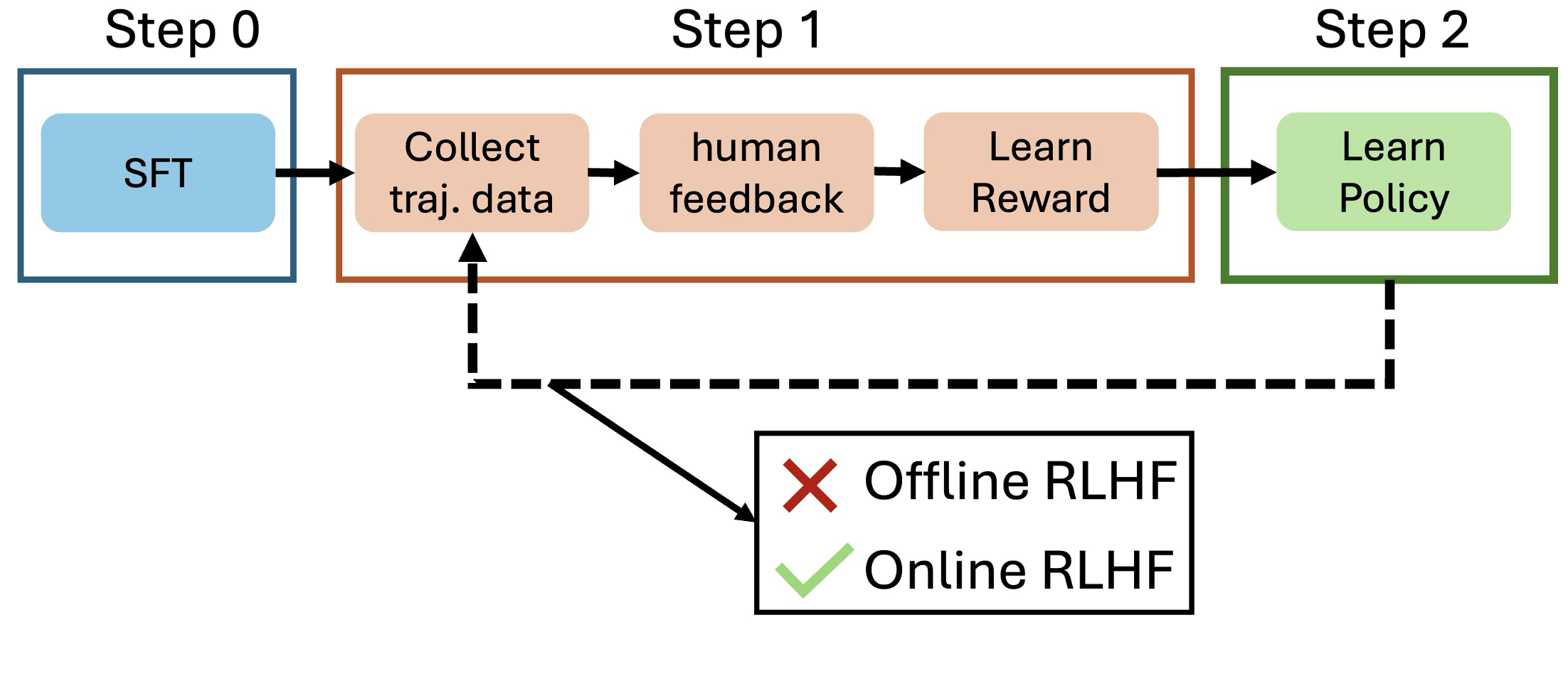
Reinforcement Learning from Human Feedback (RLHF) is a key method for aligning large language models (LLMs) with human preferences. However, current offline alignment approaches like DPO, IPO, and SLiC rely heavily on fixed preference datasets, which can lead to sub-optimal performance. On the other hand, recent literature has focused on designing online RLHF methods but still lacks a unified conceptual formulation and suffers from distribution shift issues. To address this, we establish that online LLM alignment is underpinned by bilevel optimization. By reducing this formulation to an efficient single-level first-order method (using the reward-policy equivalence), our approach generates new samples and iteratively refines model alignment by exploring responses and regulating preference labels. In doing so, we permit alignment methods to operate in an online and self-improving manner, as well as generalize prior online RLHF methods as special cases. Compared to state-of-the-art iterative RLHF methods, our approach significantly improves alignment performance on open-sourced datasets with minimal computational overhead.
6/26/2024

Understanding the Learning Dynamics of Alignment with Human Feedback
Shawn Im, Yixuan Li
0
0
Aligning large language models (LLMs) with human intentions has become a critical task for safely deploying models in real-world systems. While existing alignment approaches have seen empirical success, theoretically understanding how these methods affect model behavior remains an open question. Our work provides an initial attempt to theoretically analyze the learning dynamics of human preference alignment. We formally show how the distribution of preference datasets influences the rate of model updates and provide rigorous guarantees on the training accuracy. Our theory also reveals an intricate phenomenon where the optimization is prone to prioritizing certain behaviors with higher preference distinguishability. We empirically validate our findings on contemporary LLMs and alignment tasks, reinforcing our theoretical insights and shedding light on considerations for future alignment approaches. Disclaimer: This paper contains potentially offensive text; reader discretion is advised.
4/17/2024