SpeechPrompt: Prompting Speech Language Models for Speech Processing Tasks

0

Sign in to get full access
Overview
- Summarizes a research paper on prompting speech language models for speech processing tasks
- Covers the paper's introduction, related works, technical details, critical analysis, and conclusion
- Provides a plain English explanation of the key concepts and insights from the research
Plain English Explanation
The paper SpeechPrompt: Prompting Speech Language Models for Speech Processing Tasks explores using prompts to enhance the performance of speech language models on various speech processing tasks. Speech language models are AI systems trained on large amounts of speech data to understand and generate human speech.
The researchers found that by carefully crafting prompts - short text descriptions that guide the model's behavior - they could significantly boost the speech language model's capabilities across tasks like speech recognition, speaker identification, and emotion detection. The prompts acted as a form of "instructions" that helped the model leverage its learned knowledge more effectively.
This is an important advance because it allows speech language models to be more flexible and adaptable to different real-world applications, without having to completely retrain the model from scratch. The prompting approach provides a simpler and more efficient way to customize the model's behavior compared to traditional fine-tuning techniques.
Technical Explanation
The paper SpeechPrompt: Prompting Speech Language Models for Speech Processing Tasks investigates using prompts to improve the performance of self-supervised speech language models on a variety of speech processing tasks.
The researchers first pre-trained a speech language model using self-supervised learning on a large corpus of unlabeled speech data. They then evaluated this base model on several downstream tasks, including speech recognition, speaker identification, and emotion detection.
To boost the model's performance, the researchers experimented with different prompting strategies. They crafted short text descriptions that provided the model with relevant "instructions" or "context" about the specific task at hand. For example, for a speech recognition task, the prompt might describe the speaker, the topic of conversation, or the acoustic environment.
By incorporating these task-specific prompts, the researchers found they could significantly improve the speech language model's accuracy and efficiency across the evaluated tasks. The prompts helped the model better leverage its pre-trained knowledge and adapt its internal representations to the target application.
The paper explores various prompt engineering techniques, including prompt tuning, prompt retrieval, and prompt composition. They also analyze the impact of prompt design choices, such as length, semantic relevance, and level of task-specificity.
Overall, the SpeechPrompt research demonstrates the power of prompting as a flexible and efficient approach for customizing speech language models to diverse real-world scenarios, without the need for expensive and time-consuming fine-tuning.
Critical Analysis
The SpeechPrompt paper presents a compelling approach for enhancing speech language models using prompting techniques. However, the researchers acknowledge several limitations and areas for further exploration.
First, the paper only evaluates the prompting approach on a limited set of speech processing tasks. It would be valuable to see how the techniques generalize to a wider range of applications, such as speech synthesis, voice cloning, or multimodal speech understanding.
Additionally, the paper does not provide a deep analysis of the underlying mechanisms by which prompts influence the model's behavior. A more thorough investigation into the model's internal representations and decision-making processes could yield additional insights to guide future prompt engineering efforts.
Another potential area for further research is the interaction between prompts and the initial pre-training of the speech language model. The paper does not explore how the choice of pre-training data, architecture, or self-supervised objectives might impact the effectiveness of prompting.
Finally, the researchers note that prompt engineering can be a time-consuming and iterative process. Developing more automated or systematic methods for prompt design and optimization could help unlock the full potential of this approach.
Despite these limitations, the SpeechPrompt paper represents an important step forward in the field of speech language model customization and adaptation. The insights and techniques presented in this work could have significant implications for a wide range of real-world speech processing applications.
Conclusion
The SpeechPrompt paper introduces a novel approach for enhancing the performance of speech language models on diverse speech processing tasks. By carefully crafting task-specific prompts, the researchers were able to significantly boost the models' accuracy and efficiency across applications like speech recognition, speaker identification, and emotion detection.
This prompting technique offers a flexible and efficient alternative to traditional fine-tuning methods, allowing speech language models to be more easily customized and adapted to specific real-world scenarios. The insights and techniques presented in this work could have important implications for the development of more versatile and capable speech processing systems.
While the paper has some limitations, it represents an important step forward in the field of speech language model customization. Future research building on this work could yield additional breakthroughs in the ability to tailor AI systems to the diverse needs of speech-based applications and user experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SpeechPrompt: Prompting Speech Language Models for Speech Processing Tasks
Kai-Wei Chang, Haibin Wu, Yu-Kai Wang, Yuan-Kuei Wu, Hua Shen, Wei-Cheng Tseng, Iu-thing Kang, Shang-Wen Li, Hung-yi Lee
Prompting has become a practical method for utilizing pre-trained language models (LMs). This approach offers several advantages. It allows an LM to adapt to new tasks with minimal training and parameter updates, thus achieving efficiency in both storage and computation. Additionally, prompting modifies only the LM's inputs and harnesses the generative capabilities of language models to address various downstream tasks in a unified manner. This significantly reduces the need for human labor in designing task-specific models. These advantages become even more evident as the number of tasks served by the LM scales up. Motivated by the strengths of prompting, we are the first to explore the potential of prompting speech LMs in the domain of speech processing. Recently, there has been a growing interest in converting speech into discrete units for language modeling. Our pioneer research demonstrates that these quantized speech units are highly versatile within our unified prompting framework. Not only can they serve as class labels, but they also contain rich phonetic information that can be re-synthesized back into speech signals for speech generation tasks. Specifically, we reformulate speech processing tasks into speech-to-unit generation tasks. As a result, we can seamlessly integrate tasks such as speech classification, sequence generation, and speech generation within a single, unified prompting framework. The experiment results show that the prompting method can achieve competitive performance compared to the strong fine-tuning method based on self-supervised learning models with a similar number of trainable parameters. The prompting method also shows promising results in the few-shot setting. Moreover, with the advanced speech LMs coming into the stage, the proposed prompting framework attains great potential.
Read more8/26/2024
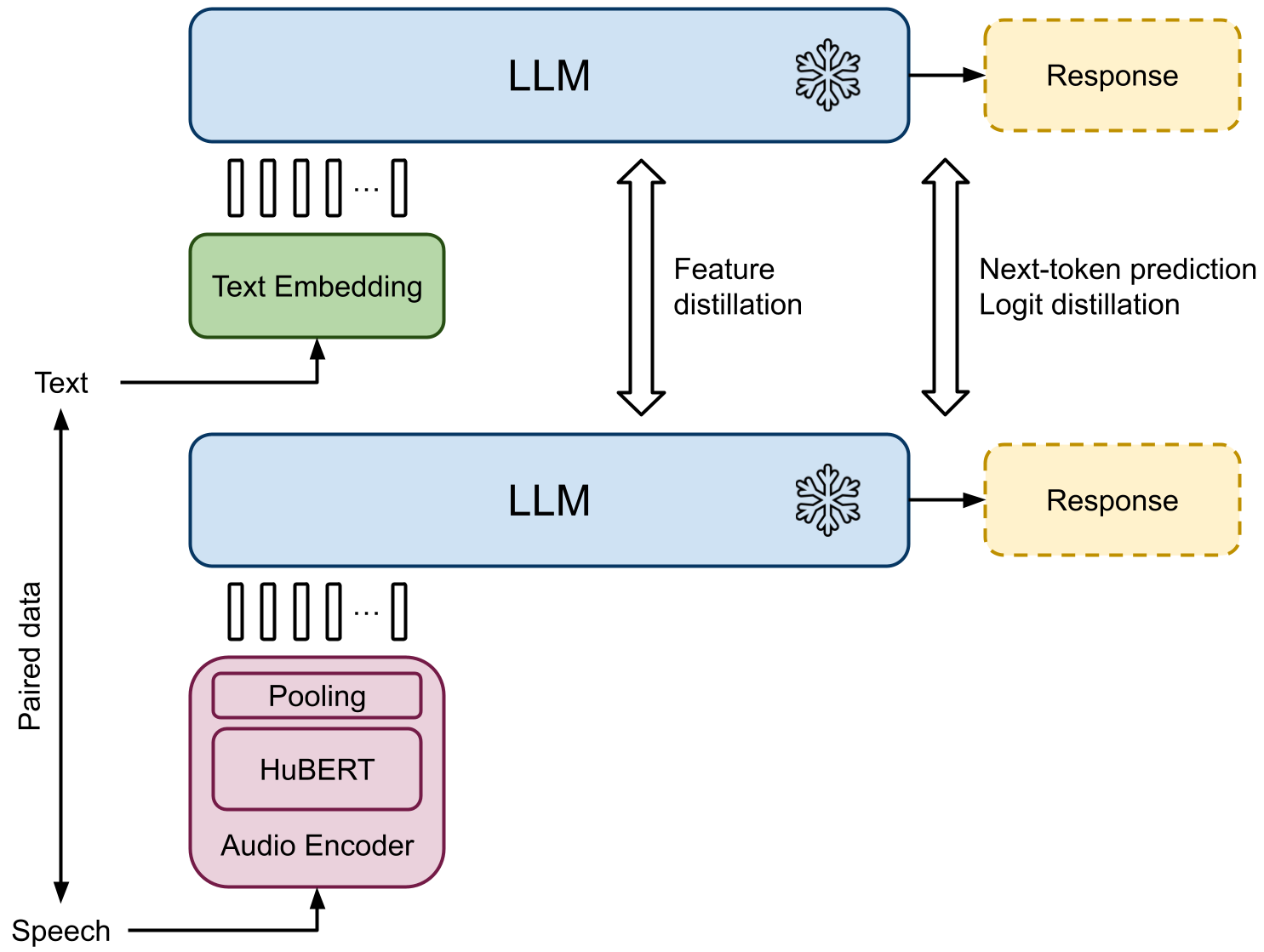
0
Prompting Large Language Models with Audio for General-Purpose Speech Summarization
Wonjune Kang, Deb Roy
In this work, we introduce a framework for speech summarization that leverages the processing and reasoning capabilities of large language models (LLMs). We propose an end-to-end system that combines an instruction-tuned LLM with an audio encoder that converts speech into token representations that the LLM can interpret. Using a dataset with paired speech-text data, the overall system is trained to generate consistent responses to prompts with the same semantic information regardless of the input modality. The resulting framework allows the LLM to process speech inputs in the same way as text, enabling speech summarization by simply prompting the LLM. Unlike prior approaches, our method is able to summarize spoken content from any arbitrary domain, and it can produce summaries in different styles by varying the LLM prompting strategy. Experiments demonstrate that our approach outperforms a cascade baseline of speech recognition followed by LLM text processing.
Read more6/11/2024
🛠️
0
PromptWizard: Task-Aware Agent-driven Prompt Optimization Framework
Eshaan Agarwal, Vivek Dani, Tanuja Ganu, Akshay Nambi
Large language models (LLMs) have revolutionized AI across diverse domains, showcasing remarkable capabilities. Central to their success is the concept of prompting, which guides model output generation. However, manual prompt engineering is labor-intensive and domain-specific, necessitating automated solutions. This paper introduces PromptWizard, a novel framework leveraging LLMs to iteratively synthesize and refine prompts tailored to specific tasks. Unlike existing approaches, PromptWizard optimizes both prompt instructions and in-context examples, maximizing model performance. The framework iteratively refines prompts by mutating instructions and incorporating negative examples to deepen understanding and ensure diversity. It further enhances both instructions and examples with the aid of a critic, synthesizing new instructions and examples enriched with detailed reasoning steps for optimal performance. PromptWizard offers several key features and capabilities, including computational efficiency compared to state-of-the-art approaches, adaptability to scenarios with varying amounts of training data, and effectiveness with smaller LLMs. Rigorous evaluation across 35 tasks on 8 datasets demonstrates PromptWizard's superiority over existing prompt strategies, showcasing its efficacy and scalability in prompt optimization.
Read more5/29/2024
💬
0
A Survey of Prompt Engineering Methods in Large Language Models for Different NLP Tasks
Shubham Vatsal, Harsh Dubey
Large language models (LLMs) have shown remarkable performance on many different Natural Language Processing (NLP) tasks. Prompt engineering plays a key role in adding more to the already existing abilities of LLMs to achieve significant performance gains on various NLP tasks. Prompt engineering requires composing natural language instructions called prompts to elicit knowledge from LLMs in a structured way. Unlike previous state-of-the-art (SoTA) models, prompt engineering does not require extensive parameter re-training or fine-tuning based on the given NLP task and thus solely operates on the embedded knowledge of LLMs. Additionally, LLM enthusiasts can intelligently extract LLMs' knowledge through a basic natural language conversational exchange or prompt engineering, allowing more and more people even without deep mathematical machine learning background to experiment with LLMs. With prompt engineering gaining popularity in the last two years, researchers have come up with numerous engineering techniques around designing prompts to improve accuracy of information extraction from the LLMs. In this paper, we summarize different prompting techniques and club them together based on different NLP tasks that they have been used for. We further granularly highlight the performance of these prompting strategies on various datasets belonging to that NLP task, talk about the corresponding LLMs used, present a taxonomy diagram and discuss the possible SoTA for specific datasets. In total, we read and present a survey of 44 research papers which talk about 39 different prompting methods on 29 different NLP tasks of which most of them have been published in the last two years.
Read more7/25/2024