SpeechTaxi: On Multilingual Semantic Speech Classification

0

Sign in to get full access
Overview
- This paper presents SpeechTaxi, a multilingual semantic speech classification model.
- The model can classify speech across 12 languages, enabling cross-lingual transfer learning.
- The dataset includes transcriptions, translations, and semantic labels for over 300,000 speech samples.
- The researchers use transliteration and multitask learning to improve performance on low-resource languages.
Plain English Explanation
The researchers have developed a speech classification system called SpeechTaxi that can work with speech in 12 different languages. This is important because it allows the model to be used in many different parts of the world, without having to create a separate system for each language.
To build SpeechTaxi, the researchers collected a large dataset of speech samples, along with text transcriptions, translations, and semantic labels. This means they have information about what each speech sample is actually saying, as well as what the overall meaning or topic of the speech is.
By having this multilingual dataset, the researchers were able to train a single model that can understand speech across all 12 languages. This is done through a technique called "cross-lingual transfer learning," where the model learns general patterns from the high-resource languages and applies them to the low-resource ones.
The researchers also used a few other techniques to improve the model's performance, especially on the low-resource languages. One is "transliteration," which converts the speech into a common writing system, making it easier for the model to process. Another is "multitask learning," where the model is trained not just on speech classification, but also on other related tasks like translation.
Overall, this research is significant because it demonstrates a way to build speech classification systems that work across many languages, without having to develop a separate model for each one. This could be very useful for applications like virtual assistants, language learning tools, and automated customer service systems.
Technical Explanation
The SpeechTaxi model is a multilingual semantic speech classification system that can classify speech samples into predefined categories across 12 different languages. The researchers leveraged a large, multilingual dataset containing transcriptions, translations, and semantic labels for over 300,000 speech samples to train a single model capable of cross-lingual transfer learning.
To address the challenges of low-resource languages, the researchers employed transliteration to convert speech into a common writing system, as well as multitask learning where the model was trained not only on speech classification, but also on related tasks like translation. This allowed the model to learn general patterns from high-resource languages and apply them to low-resource ones, improving overall performance.
The architecture of SpeechTaxi consists of a shared encoder that processes the speech input, and separate task-specific decoders for classification, translation, and other auxiliary tasks. This end-to-end speech-to-text translation approach allows the model to efficiently leverage the connections between these related tasks.
Through extensive experiments, the researchers demonstrated the effectiveness of the SpeechTaxi model, showing that it outperforms monolingual baselines and achieves strong performance across all 12 languages in the dataset.
Critical Analysis
The SpeechTaxi paper presents a compelling approach to building a multilingual speech classification system, but there are a few areas that could be further explored or improved upon.
One potential limitation is the reliance on a predefined set of semantic categories. While this allows the model to be used for specific applications, it may not be as flexible or generalizable as an open-ended speech understanding system. The researchers could consider exploring more open-ended, unsupervised approaches to speech classification in the future.
Additionally, the dataset used in this work, while large and diverse, may not be representative of all real-world speech scenarios. The researchers acknowledge that the dataset was primarily collected from online sources, which could introduce biases. Validating the model's performance on more diverse and naturalistic speech data would be an important next step.
Finally, while the multilingual aspect of the model is a key strength, the researchers do not provide much insight into the model's ability to handle code-switching or other phenomena common in multilingual speech. Exploring these types of challenges could lead to further advancements in the field of multilingual spoken language understanding.
Overall, the SpeechTaxi model represents a significant step forward in building robust, cross-lingual speech classification systems. The researchers have demonstrated the potential of this approach, and further research in this direction could yield valuable insights and practical applications.
Conclusion
The SpeechTaxi paper presents a novel multilingual semantic speech classification model that can effectively leverage cross-lingual transfer learning to achieve strong performance across 12 languages. By incorporating techniques like transliteration and multitask learning, the researchers were able to address the challenges of low-resource languages and develop a versatile system with broad applicability.
This research showcases the potential of multilingual speech understanding systems, which could enable a wide range of applications, from virtual assistants and language learning tools to automated customer service and content moderation. As the field of spoken language processing continues to evolve, the insights and approaches demonstrated in the SpeechTaxi paper will likely inform future advancements in this important area of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SpeechTaxi: On Multilingual Semantic Speech Classification
Lennart Keller, Goran Glavav{s}
Recent advancements in multilingual speech encoding as well as transcription raise the question of the most effective approach to semantic speech classification. Concretely, can (1) end-to-end (E2E) classifiers obtained by fine-tuning state-of-the-art multilingual speech encoders (MSEs) match or surpass the performance of (2) cascading (CA), where speech is first transcribed into text and classification is delegated to a text-based classifier. To answer this, we first construct SpeechTaxi, an 80-hour multilingual dataset for semantic speech classification of Bible verses, covering 28 diverse languages. We then leverage SpeechTaxi to conduct a wide range of experiments comparing E2E and CA in monolingual semantic speech classification as well as in cross-lingual transfer. We find that E2E based on MSEs outperforms CA in monolingual setups, i.e., when trained on in-language data. However, MSEs seem to have poor cross-lingual transfer abilities, with E2E substantially lagging CA both in (1) zero-shot transfer to languages unseen in training and (2) multilingual training, i.e., joint training on multiple languages. Finally, we devise a novel CA approach based on transcription to Romanized text as a language-agnostic intermediate representation and show that it represents a robust solution for languages without native ASR support. Our SpeechTaxi dataset is publicly available at: https://huggingface.co/ datasets/LennartKeller/SpeechTaxi/.
Read more9/11/2024
0
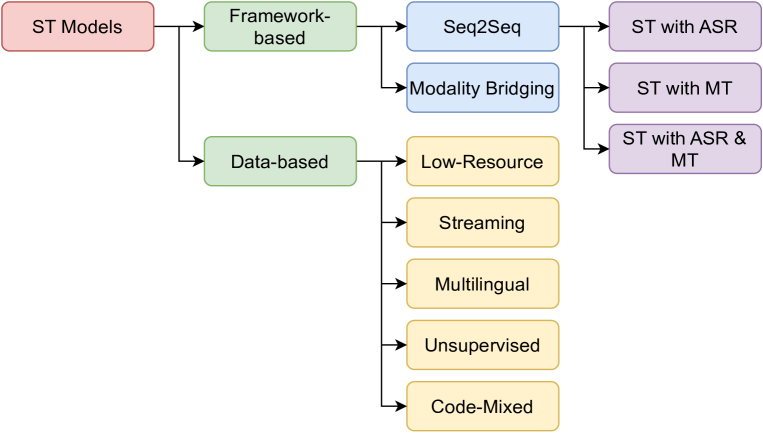
End-to-End Speech-to-Text Translation: A Survey
Nivedita Sethiya, Chandresh Kumar Maurya
Speech-to-text translation pertains to the task of converting speech signals in a language to text in another language. It finds its application in various domains, such as hands-free communication, dictation, video lecture transcription, and translation, to name a few. Automatic Speech Recognition (ASR), as well as Machine Translation(MT) models, play crucial roles in traditional ST translation, enabling the conversion of spoken language in its original form to written text and facilitating seamless cross-lingual communication. ASR recognizes spoken words, while MT translates the transcribed text into the target language. Such disintegrated models suffer from cascaded error propagation and high resource and training costs. As a result, researchers have been exploring end-to-end (E2E) models for ST translation. However, to our knowledge, there is no comprehensive review of existing works on E2E ST. The present survey, therefore, discusses the work in this direction. Our attempt has been to provide a comprehensive review of models employed, metrics, and datasets used for ST tasks, providing challenges and future research direction with new insights. We believe this review will be helpful to researchers working on various applications of ST models.
Read more6/11/2024

0
Advancing Topic Segmentation of Broadcasted Speech with Multilingual Semantic Embeddings
Sakshi Deo Shukla, Pavel Denisov, Tugtekin Turan
Recent advancements in speech-based topic segmentation have highlighted the potential of pretrained speech encoders to capture semantic representations directly from speech. Traditionally, topic segmentation has relied on a pipeline approach in which transcripts of the automatic speech recognition systems are generated, followed by text-based segmentation algorithms. In this paper, we introduce an end-to-end scheme that bypasses this conventional two-step process by directly employing semantic speech encoders for segmentation. Focused on the broadcasted news domain, which poses unique challenges due to the diversity of speakers and topics within single recordings, we address the challenge of accessing topic change points efficiently in an end-to-end manner. Furthermore, we propose a new benchmark for spoken news topic segmentation by utilizing a dataset featuring approximately 1000 hours of publicly available recordings across six European languages and including an evaluation set in Hindi to test the model's cross-domain performance in a cross-lingual, zero-shot scenario. This setup reflects real-world diversity and the need for models adapting to various linguistic settings. Our results demonstrate that while the traditional pipeline approach achieves a state-of-the-art $P_k$ score of 0.2431 for English, our end-to-end model delivers a competitive $P_k$ score of 0.2564. When trained multilingually, these scores further improve to 0.1988 and 0.2370, respectively. To support further research, we release our model along with data preparation scripts, facilitating open research on multilingual spoken news topic segmentation.
Read more9/11/2024

0
Rapid Language Adaptation for Multilingual E2E Speech Recognition Using Encoder Prompting
Yosuke Kashiwagi, Hayato Futami, Emiru Tsunoo, Siddhant Arora, Shinji Watanabe
End-to-end multilingual speech recognition models handle multiple languages through a single model, often incorporating language identification to automatically detect the language of incoming speech. Since the common scenario is where the language is already known, these models can perform as language-specific by using language information as prompts, which is particularly beneficial for attention-based encoder-decoder architectures. However, the Connectionist Temporal Classification (CTC) approach, which enhances recognition via joint decoding and multi-task training, does not normally incorporate language prompts due to its conditionally independent output tokens. To overcome this, we introduce an encoder prompting technique within the self-conditioned CTC framework, enabling language-specific adaptation of the CTC model in a zero-shot manner. Our method has shown to significantly reduce errors by 28% on average and by 41% on low-resource languages.
Read more6/19/2024