End-to-End Speech-to-Text Translation: A Survey
2312.01053
0
0
Abstract
Speech-to-text translation pertains to the task of converting speech signals in a language to text in another language. It finds its application in various domains, such as hands-free communication, dictation, video lecture transcription, and translation, to name a few. Automatic Speech Recognition (ASR), as well as Machine Translation(MT) models, play crucial roles in traditional ST translation, enabling the conversion of spoken language in its original form to written text and facilitating seamless cross-lingual communication. ASR recognizes spoken words, while MT translates the transcribed text into the target language. Such disintegrated models suffer from cascaded error propagation and high resource and training costs. As a result, researchers have been exploring end-to-end (E2E) models for ST translation. However, to our knowledge, there is no comprehensive review of existing works on E2E ST. The present survey, therefore, discusses the work in this direction. Our attempt has been to provide a comprehensive review of models employed, metrics, and datasets used for ST tasks, providing challenges and future research direction with new insights. We believe this review will be helpful to researchers working on various applications of ST models.
Create account to get full access
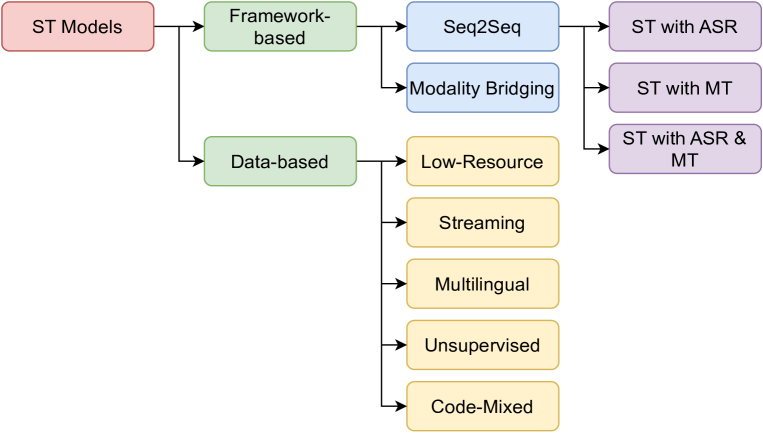
Overview
- The provided paper presents a comprehensive survey of end-to-end speech-to-text translation, a rapidly advancing field that aims to directly translate speech in one language to text in another language.
- The paper covers the task definition, evaluation metrics, different model architectures, and the latest advancements in this domain.
- It also discusses some of the key challenges and future research directions in this area.
Plain English Explanation
The paper discusses a technology called "end-to-end speech-to-text translation," which allows you to take speech in one language and automatically convert it into written text in a different language. This is a complex task that involves multiple steps, like recognizing the words being spoken, understanding the meaning, and then translating that meaning into a different language.
The researchers provide a detailed overview of how this technology works, including the specific metrics used to evaluate the performance of these systems. They also describe the different types of models and architectures that researchers have developed to tackle this problem.
The key insight from this paper is that end-to-end speech-to-text translation has seen significant advancements in recent years, thanks to the development of powerful deep learning models and the availability of large amounts of training data. However, there are still some challenges that need to be addressed, such as link to "Pushing the Limits of Zero-Shot End-to-End Speech Translation" handling accents and dialects, and link to "Integrating Pre-trained Speech and Language Models for End-to-End Speech-to-Text Translation" improving the fluency and naturalness of the translated text.
Technical Explanation
The paper first defines the task of end-to-end speech-to-text translation, which involves directly converting an audio input in one language to a text output in a different language, without the need for intermediate steps like speech recognition and machine translation.
The authors then discuss the various evaluation metrics used to assess the performance of these systems, such as link to "Recent Advances in End-to-End Simultaneous Speech Translation" BLEU score, translation edit rate, and human evaluation.
The bulk of the paper is dedicated to reviewing the different model architectures that have been proposed for end-to-end speech-to-text translation. These include link to "TransVIP: A Speech-to-Speech Translation System with Voice Identity Preservation" encoder-decoder models, link to "SeamlessExpressiveLM: A Speech-Language Model for Expressive Speech-to-Text Translation" speech translation models, and end-to-end models that jointly perform speech recognition and machine translation.
The paper also covers some of the recent advancements in this field, such as the use of pre-trained speech and language models, and techniques for handling low-resource languages and simultaneous translation.
Critical Analysis
The paper provides a thorough and well-researched overview of the current state of end-to-end speech-to-text translation. However, it also acknowledges some of the key challenges and limitations of this technology.
One limitation mentioned is the difficulty in handling diverse accents and dialects, which can significantly degrade the performance of these systems. The authors suggest that further research is needed to improve the robustness of these models to linguistic variations.
Another area for improvement is the quality and fluency of the translated text. While the paper highlights advancements in this area, such as the use of link to "Seamless Expressive LM: A Speech-Language Model for Expressive Speech-to-Text Translation", the authors note that there is still room for improvement in terms of the naturalness and expressiveness of the output.
The paper also touches on the challenge of link to "Pushing the Limits of Zero-Shot End-to-End Speech Translation" zero-shot translation, where the model is required to translate between language pairs that it has not been explicitly trained on. This is an important capability for real-world applications, and the authors suggest that further research is needed to address this challenge.
Conclusion
The paper provides a comprehensive overview of the current state of end-to-end speech-to-text translation, a rapidly advancing field that holds the promise of enabling seamless, real-time language translation. While significant progress has been made in this area, the authors highlight several key challenges that need to be addressed, such as improving robustness to linguistic variations, enhancing the quality and fluency of the translated text, and enabling zero-shot translation capabilities.
Overall, this survey paper serves as a valuable resource for researchers and practitioners working in the field of speech-to-text translation, providing a solid foundation for understanding the current landscape and identifying promising directions for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
Recent Advances in End-to-End Simultaneous Speech Translation
Xiaoqian Liu, Guoqiang Hu, Yangfan Du, Erfeng He, YingFeng Luo, Chen Xu, Tong Xiao, Jingbo Zhu
0
0
Simultaneous speech translation (SimulST) is a demanding task that involves generating translations in real-time while continuously processing speech input. This paper offers a comprehensive overview of the recent developments in SimulST research, focusing on four major challenges. Firstly, the complexities associated with processing lengthy and continuous speech streams pose significant hurdles. Secondly, satisfying real-time requirements presents inherent difficulties due to the need for immediate translation output. Thirdly, striking a balance between translation quality and latency constraints remains a critical challenge. Finally, the scarcity of annotated data adds another layer of complexity to the task. Through our exploration of these challenges and the proposed solutions, we aim to provide valuable insights into the current landscape of SimulST research and suggest promising directions for future exploration.
6/4/2024

Integrating Pre-Trained Speech and Language Models for End-to-End Speech Recognition
Yukiya Hono, Koh Mitsuda, Tianyu Zhao, Kentaro Mitsui, Toshiaki Wakatsuki, Kei Sawada
0
0
Advances in machine learning have made it possible to perform various text and speech processing tasks, such as automatic speech recognition (ASR), in an end-to-end (E2E) manner. E2E approaches utilizing pre-trained models are gaining attention for conserving training data and resources. However, most of their applications in ASR involve only one of either a pre-trained speech or a language model. This paper proposes integrating a pre-trained speech representation model and a large language model (LLM) for E2E ASR. The proposed model enables the optimization of the entire ASR process, including acoustic feature extraction and acoustic and language modeling, by combining pre-trained models with a bridge network and also enables the application of remarkable developments in LLM utilization, such as parameter-efficient domain adaptation and inference optimization. Experimental results demonstrate that the proposed model achieves a performance comparable to that of modern E2E ASR models by utilizing powerful pre-training models with the proposed integrated approach.
6/7/2024
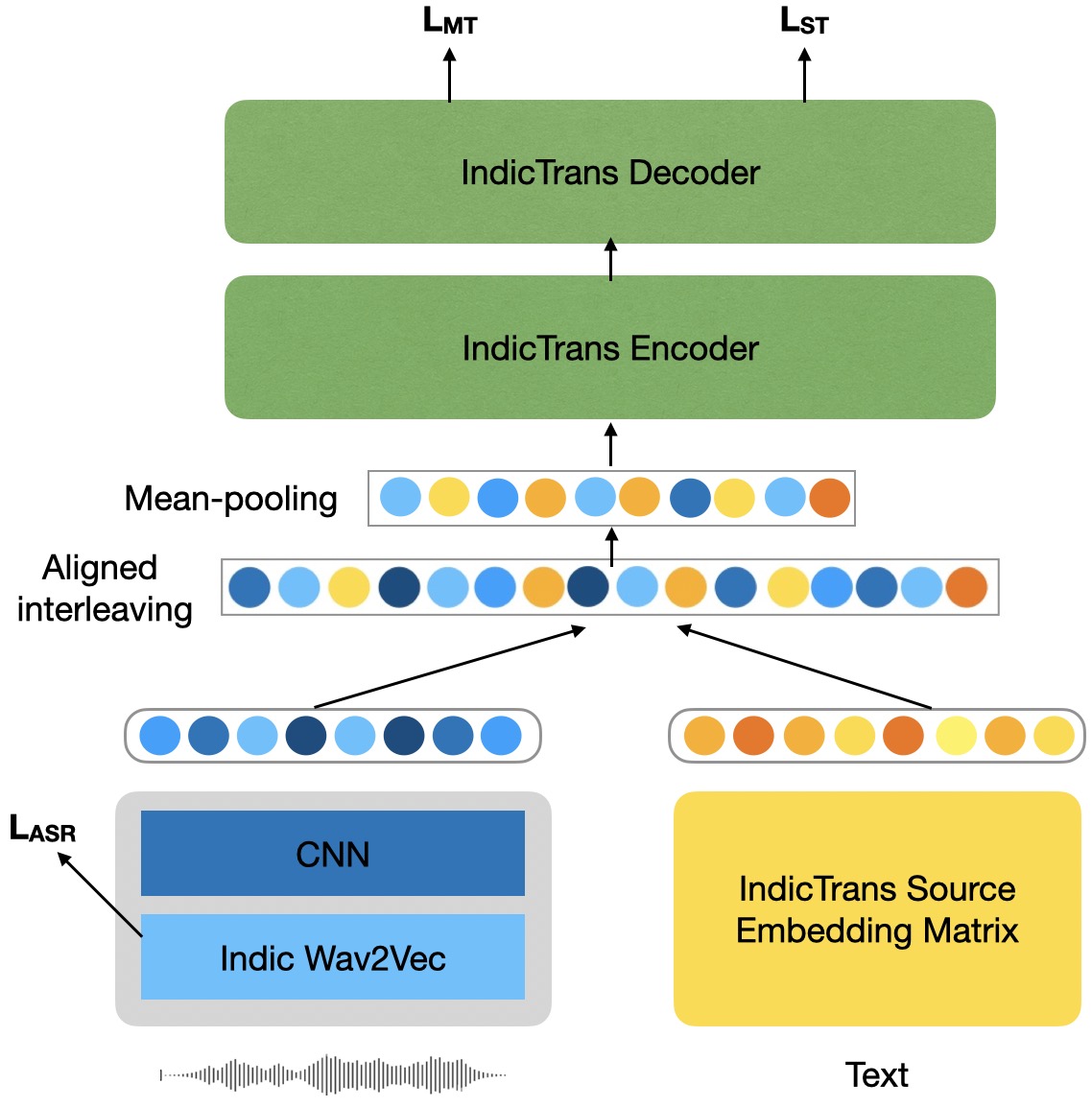
CoSTA: Code-Switched Speech Translation using Aligned Speech-Text Interleaving
Bhavani Shankar, Preethi Jyothi, Pushpak Bhattacharyya
0
0
Code-switching is a widely prevalent linguistic phenomenon in multilingual societies like India. Building speech-to-text models for code-switched speech is challenging due to limited availability of datasets. In this work, we focus on the problem of spoken translation (ST) of code-switched speech in Indian languages to English text. We present a new end-to-end model architecture COSTA that scaffolds on pretrained automatic speech recognition (ASR) and machine translation (MT) modules (that are more widely available for many languages). Speech and ASR text representations are fused using an aligned interleaving scheme and are fed further as input to a pretrained MT module; the whole pipeline is then trained end-to-end for spoken translation using synthetically created ST data. We also release a new evaluation benchmark for code-switched Bengali-English, Hindi-English, Marathi-English and Telugu- English speech to English text. COSTA significantly outperforms many competitive cascaded and end-to-end multimodal baselines by up to 3.5 BLEU points.
6/18/2024

TransVIP: Speech to Speech Translation System with Voice and Isochrony Preservation
Chenyang Le, Yao Qian, Dongmei Wang, Long Zhou, Shujie Liu, Xiaofei Wang, Midia Yousefi, Yanmin Qian, Jinyu Li, Sheng Zhao, Michael Zeng
0
0
There is a rising interest and trend in research towards directly translating speech from one language to another, known as end-to-end speech-to-speech translation. However, most end-to-end models struggle to outperform cascade models, i.e., a pipeline framework by concatenating speech recognition, machine translation and text-to-speech models. The primary challenges stem from the inherent complexities involved in direct translation tasks and the scarcity of data. In this study, we introduce a novel model framework TransVIP that leverages diverse datasets in a cascade fashion yet facilitates end-to-end inference through joint probability. Furthermore, we propose two separated encoders to preserve the speaker's voice characteristics and isochrony from the source speech during the translation process, making it highly suitable for scenarios such as video dubbing. Our experiments on the French-English language pair demonstrate that our model outperforms the current state-of-the-art speech-to-speech translation model.
5/29/2024