SpotDiffusion: A Fast Approach For Seamless Panorama Generation Over Time

0

Sign in to get full access
Overview
- This paper introduces SpotDiffusion, a fast approach for generating seamless panoramic images over time.
- The key innovation is using a diffusion model to enable efficient and high-quality panorama generation from multiple image inputs.
- The approach is designed to handle dynamic scenes and produce visually coherent panoramas.
Plain English Explanation
SpotDiffusion is a new method for automatically stitching together multiple images into a seamless, 360-degree panoramic view. Unlike traditional panorama creation, which can be time-consuming and produce noticeable seams, SpotDiffusion uses a diffusion model - a type of AI algorithm - to generate the panorama quickly and with high visual quality.
The key idea is that the diffusion model can learn to "stitch" the input images together in a way that preserves the continuity and coherence of the scene. This allows SpotDiffusion to handle dynamic scenes, where objects or people are moving, and still produce a final panorama that looks natural and uninterrupted.
Instead of manually aligning and blending the input images, SpotDiffusion automates this process using the diffusion model. This makes panorama creation much faster and more accessible for everyday users, without sacrificing the end result.
Technical Explanation
SpotDiffusion works by using a diffusion model, a type of generative AI, to synthesize panoramic images from a set of input images. The diffusion model is trained to learn the characteristics of seamless panoramas, allowing it to intelligently combine the input images into a cohesive final result.
The architecture of SpotDiffusion consists of an encoder that processes the input images, a diffusion module that generates the panorama, and a decoder that outputs the final image. The key innovation is in the diffusion module, which uses a novel "spotshotdiffusion" technique to efficiently produce the panorama while preserving visual continuity.
Experiments demonstrate that SpotDiffusion can generate high-quality panoramas from various input configurations, including dynamic scenes with moving elements. The approach is shown to outperform traditional panorama stitching methods in terms of both speed and visual quality.
Critical Analysis
The paper presents a promising approach for panorama generation, but there are a few potential limitations and areas for further research:
- The paper does not extensively explore the handling of occlusions or large changes in perspective between input images, which could be challenging for the diffusion model.
- The evaluation is primarily focused on qualitative assessments of visual quality, and more quantitative metrics could help better understand the performance of SpotDiffusion.
- The scalability of the approach to very large or high-resolution panoramas is not discussed, and the computational requirements may become a bottleneck for some use cases.
Overall, SpotDiffusion represents an interesting and potentially impactful contribution to the field of panorama generation, but further research and real-world testing would be valuable to fully assess its capabilities and limitations.
Conclusion
SpotDiffusion introduces a fast and effective approach for generating seamless panoramic images from multiple input images. By leveraging a diffusion model, the method can automatically stitch together the input images while preserving visual continuity, even in dynamic scenes.
The key innovation of SpotDiffusion is its ability to produce high-quality panoramas quickly and efficiently, making the technology more accessible for everyday users. While the paper identifies some potential areas for further research, the overall approach represents an exciting advancement in the field of panorama generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SpotDiffusion: A Fast Approach For Seamless Panorama Generation Over Time
Stanislav Frolov, Brian B. Moser, Andreas Dengel
Generating high-resolution images with generative models has recently been made widely accessible by leveraging diffusion models pre-trained on large-scale datasets. Various techniques, such as MultiDiffusion and SyncDiffusion, have further pushed image generation beyond training resolutions, i.e., from square images to panorama, by merging multiple overlapping diffusion paths or employing gradient descent to maintain perceptual coherence. However, these methods suffer from significant computational inefficiencies due to generating and averaging numerous predictions, which is required in practice to produce high-quality and seamless images. This work addresses this limitation and presents a novel approach that eliminates the need to generate and average numerous overlapping denoising predictions. Our method shifts non-overlapping denoising windows over time, ensuring that seams in one timestep are corrected in the next. This results in coherent, high-resolution images with fewer overall steps. We demonstrate the effectiveness of our approach through qualitative and quantitative evaluations, comparing it with MultiDiffusion, SyncDiffusion, and StitchDiffusion. Our method offers several key benefits, including improved computational efficiency and faster inference times while producing comparable or better image quality.
Read more7/23/2024
0
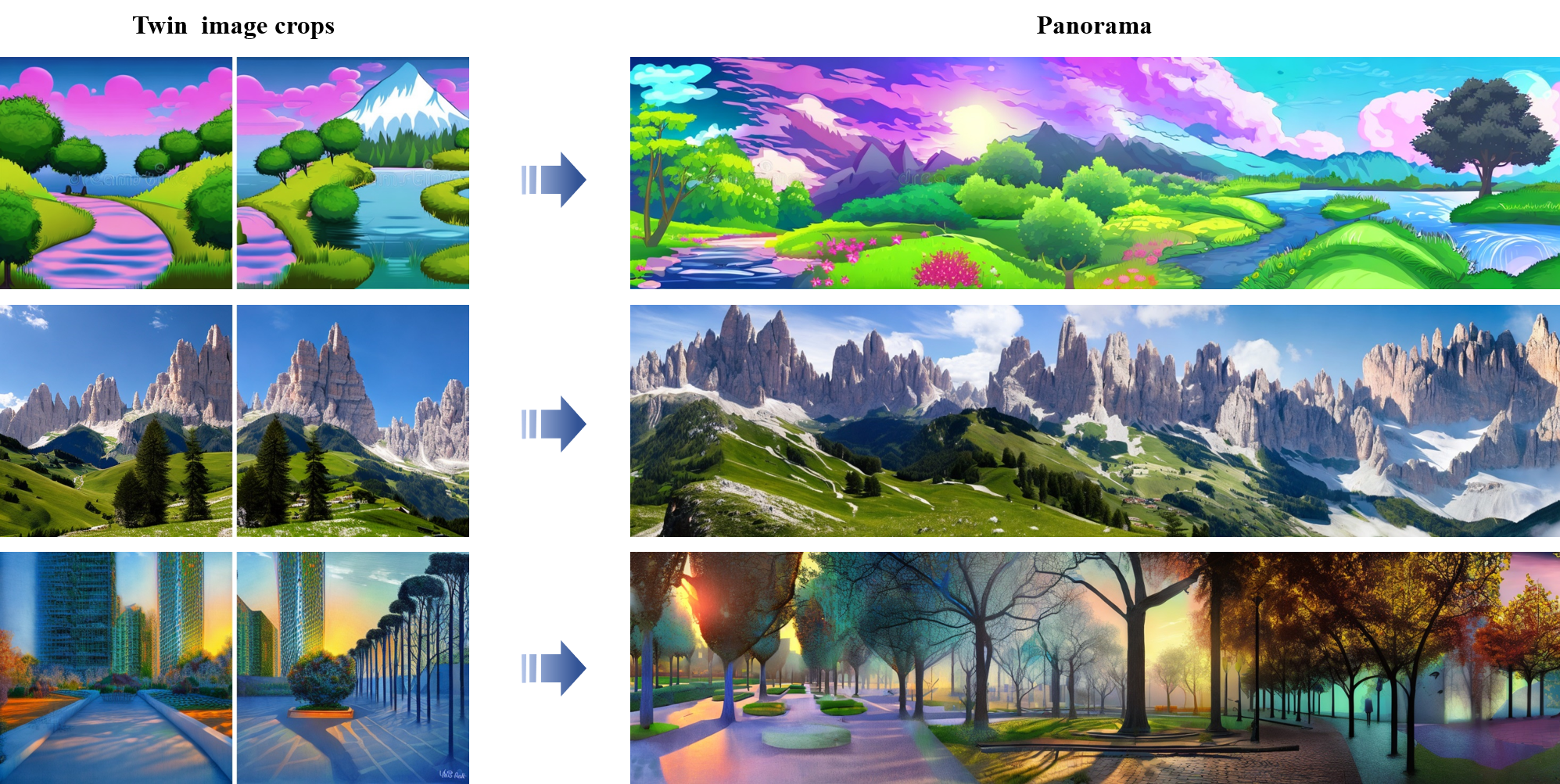
TwinDiffusion: Enhancing Coherence and Efficiency in Panoramic Image Generation with Diffusion Models
Teng Zhou, Yongchuan Tang
Diffusion models have emerged as effective tools for generating diverse and high-quality content. However, their capability in high-resolution image generation, particularly for panoramic images, still faces challenges such as visible seams and incoherent transitions. In this paper, we propose TwinDiffusion, an optimized framework designed to address these challenges through two key innovations: the Crop Fusion for quality enhancement and the Cross Sampling for efficiency optimization. We introduce a training-free optimizing stage to refine the similarity of adjacent image areas, as well as an interleaving sampling strategy to yield dynamic patches during the cropping process. A comprehensive evaluation is conducted to compare TwinDiffusion with the prior works, considering factors including coherence, fidelity, compatibility, and efficiency. The results demonstrate the superior performance of our approach in generating seamless and coherent panoramas, setting a new standard in quality and efficiency for panoramic image generation.
Read more7/9/2024

0
Merging and Splitting Diffusion Paths for Semantically Coherent Panoramas
Fabio Quattrini, Vittorio Pippi, Silvia Cascianelli, Rita Cucchiara
Diffusion models have become the State-of-the-Art for text-to-image generation, and increasing research effort has been dedicated to adapting the inference process of pretrained diffusion models to achieve zero-shot capabilities. An example is the generation of panorama images, which has been tackled in recent works by combining independent diffusion paths over overlapping latent features, which is referred to as joint diffusion, obtaining perceptually aligned panoramas. However, these methods often yield semantically incoherent outputs and trade-off diversity for uniformity. To overcome this limitation, we propose the Merge-Attend-Diffuse operator, which can be plugged into different types of pretrained diffusion models used in a joint diffusion setting to improve the perceptual and semantical coherence of the generated panorama images. Specifically, we merge the diffusion paths, reprogramming self- and cross-attention to operate on the aggregated latent space. Extensive quantitative and qualitative experimental analysis, together with a user study, demonstrate that our method maintains compatibility with the input prompt and visual quality of the generated images while increasing their semantic coherence. We release the code at https://github.com/aimagelab/MAD.
Read more8/29/2024
0
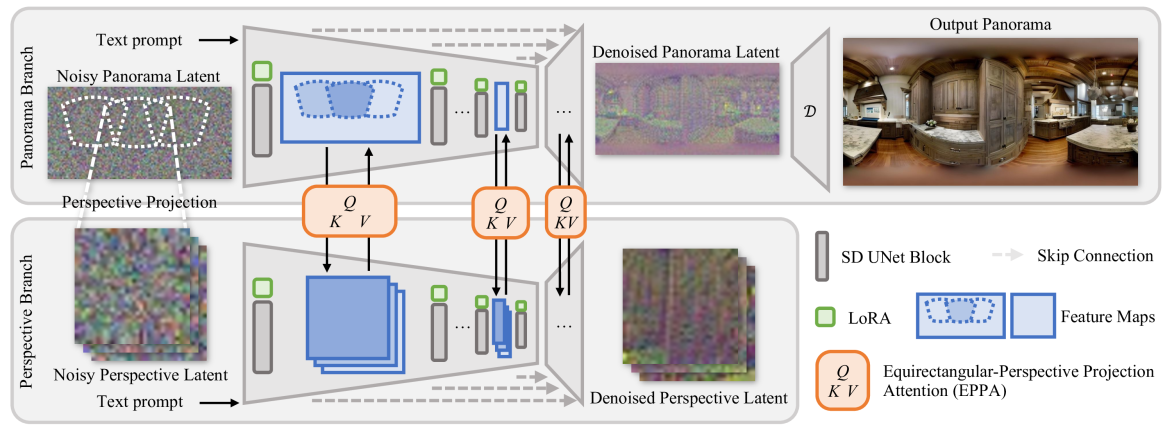
Taming Stable Diffusion for Text to 360{deg} Panorama Image Generation
Cheng Zhang, Qianyi Wu, Camilo Cruz Gambardella, Xiaoshui Huang, Dinh Phung, Wanli Ouyang, Jianfei Cai
Generative models, e.g., Stable Diffusion, have enabled the creation of photorealistic images from text prompts. Yet, the generation of 360-degree panorama images from text remains a challenge, particularly due to the dearth of paired text-panorama data and the domain gap between panorama and perspective images. In this paper, we introduce a novel dual-branch diffusion model named PanFusion to generate a 360-degree image from a text prompt. We leverage the stable diffusion model as one branch to provide prior knowledge in natural image generation and register it to another panorama branch for holistic image generation. We propose a unique cross-attention mechanism with projection awareness to minimize distortion during the collaborative denoising process. Our experiments validate that PanFusion surpasses existing methods and, thanks to its dual-branch structure, can integrate additional constraints like room layout for customized panorama outputs. Code is available at https://chengzhag.github.io/publication/panfusion.
Read more4/12/2024