Spurious Feature Eraser: Stabilizing Test-Time Adaptation for Vision-Language Foundation Model

0

Sign in to get full access
Overview
- This paper proposes a novel approach called "Invariant Test-Time Adaptation" (ITTA) to improve the generalization of vision-language models to unseen domains.
- The key idea is to adapt the model during inference (test-time) in a way that preserves the model's underlying invariant representations, rather than standard fine-tuning which can lead to overfitting.
- The method is evaluated on a range of vision-language tasks, including RefineSkewedPerceptions, CLAP, SignSGD, and AdversarialPromptTuning.
Plain English Explanation
The paper focuses on improving the ability of vision-language models to work well in new situations, even if they were trained on different data. This is an important challenge, as these models are often used in a wide variety of real-world applications.
The key idea is to adapt the model during testing (when it's being used, rather than during training) in a way that preserves the model's core knowledge and representations. This is different from the standard approach of fine-tuning the model on new data, which can cause the model to specialize too much and lose its broader understanding.
The researchers tested their approach on several different vision-language tasks, including tasks related to RefineSkewedPerceptions, CLAP, SignSGD, and AdversarialPromptTuning. The results show that their approach can significantly improve the models' performance on new, unseen data.
Technical Explanation
The paper proposes "Invariant Test-Time Adaptation" (ITTA), a novel approach to adapting vision-language models to new domains during inference (test-time). The key idea is to preserve the model's underlying invariant representations, rather than performing standard fine-tuning which can lead to overfitting.
The method works by first pre-training a vision-language model on a large, diverse dataset. During test-time, the model is adapted to a new domain by optimizing for invariance - i.e., ensuring that the model's representations remain consistent across the training and test distributions. This is done by minimizing the discrepancy between the feature distributions of the training and test data, without directly updating the model's parameters.
The method is evaluated on a range of vision-language tasks, including RefineSkewedPerceptions, CLAP, SignSGD, and AdversarialPromptTuning. The results demonstrate that ITTA can significantly outperform standard fine-tuning approaches, indicating the importance of preserving the model's underlying representations during adaptation.
Critical Analysis
The paper presents a compelling approach to improving the generalization of vision-language models, and the experimental results are promising. However, there are a few potential limitations and areas for further research that could be considered:
-
The method relies on the assumption that there exists an "invariant" representation that is shared across the training and test distributions. In practice, this may not always be the case, and the researchers acknowledge that identifying the optimal invariant representation is a key challenge.
-
The method is evaluated on a limited set of tasks and datasets. It would be valuable to see how the approach performs on a wider range of real-world applications, including those with more significant domain shifts or noisy/incomplete test-time data.
-
The computational overhead of the adaptation process during inference is not thoroughly discussed. In many real-world scenarios, low latency is a critical requirement, and the efficiency of the adaptation method would need to be carefully considered.
-
The paper does not address potential ethical concerns, such as the risk of the method amplifying biases present in the training data or the implications of deploying these models in high-stakes decision-making scenarios. Careful consideration of these issues would be important for the responsible development and deployment of such techniques.
Conclusion
Overall, the "Invariant Test-Time Adaptation" (ITTA) approach proposed in this paper represents an important step forward in improving the generalization of vision-language models to unseen domains. By preserving the model's underlying invariant representations during adaptation, the method can significantly outperform standard fine-tuning techniques, as demonstrated across a range of tasks.
While the paper identifies some key challenges and limitations, the core ideas have the potential to enable more robust and adaptable vision-language models, with applications in a wide variety of real-world scenarios. As the field of vision-language AI continues to advance, approaches like ITTA will likely play an important role in ensuring these models can be reliably and responsibly deployed in diverse and evolving environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Spurious Feature Eraser: Stabilizing Test-Time Adaptation for Vision-Language Foundation Model
Huan Ma, Yan Zhu, Changqing Zhang, Peilin Zhao, Baoyuan Wu, Long-Kai Huang, Qinghua Hu, Bingzhe Wu
Vision-language foundation models have exhibited remarkable success across a multitude of downstream tasks due to their scalability on extensive image-text paired data. However, these models also display significant limitations when applied to downstream tasks, such as fine-grained image classification, as a result of ``decision shortcuts'' that hinder their generalization capabilities. In this work, we find that the CLIP model possesses a rich set of features, encompassing both textit{desired invariant causal features} and textit{undesired decision shortcuts}. Moreover, the underperformance of CLIP on downstream tasks originates from its inability to effectively utilize pre-trained features in accordance with specific task requirements. To address this challenge, we propose a simple yet effective method, Spurious Feature Eraser (SEraser), to alleviate the decision shortcuts by erasing the spurious features. Specifically, we introduce a test-time prompt tuning paradigm that optimizes a learnable prompt, thereby compelling the model to exploit invariant features while disregarding decision shortcuts during the inference phase. The proposed method effectively alleviates excessive dependence on potentially misleading spurious information. We conduct comparative analysis of the proposed method against various approaches which validates the significant superiority.
Read more6/4/2024
🔍
0
Refining Skewed Perceptions in Vision-Language Models through Visual Representations
Haocheng Dai, Sarang Joshi
Large vision-language models (VLMs), such as CLIP, have become foundational, demonstrating remarkable success across a variety of downstream tasks. Despite their advantages, these models, akin to other foundational systems, inherit biases from the disproportionate distribution of real-world data, leading to misconceptions about the actual environment. Prevalent datasets like ImageNet are often riddled with non-causal, spurious correlations that can diminish VLM performance in scenarios where these contextual elements are absent. This study presents an investigation into how a simple linear probe can effectively distill task-specific core features from CLIP's embedding for downstream applications. Our analysis reveals that the CLIP text representations are often tainted by spurious correlations, inherited in the biased pre-training dataset. Empirical evidence suggests that relying on visual representations from CLIP, as opposed to text embedding, is more practical to refine the skewed perceptions in VLMs, emphasizing the superior utility of visual representations in overcoming embedded biases. Our codes will be available here.
Read more5/24/2024
⚙️
0
CLAP: Isolating Content from Style through Contrastive Learning with Augmented Prompts
Yichao Cai, Yuhang Liu, Zhen Zhang, Javen Qinfeng Shi
Contrastive vision-language models, such as CLIP, have garnered considerable attention for various dowmsteam tasks, mainly due to the remarkable ability of the learned features for generalization. However, the features they learned often blend content and style information, which somewhat limits their generalization capabilities under distribution shifts. To address this limitation, we adopt a causal generative perspective for multimodal data and propose contrastive learning with data augmentation to disentangle content features from the original representations. To achieve this, we begin with exploring image augmentation techniques and develop a method to seamlessly integrate them into pre-trained CLIP-like models to extract pure content features. Taking a step further, recognizing the inherent semantic richness and logical structure of text data, we explore the use of text augmentation to isolate latent content from style features. This enables CLIP-like model's encoders to concentrate on latent content information, refining the learned representations by pre-trained CLIP-like models. Our extensive experiments across diverse datasets demonstrate significant improvements in zero-shot and few-shot classification tasks, alongside enhanced robustness to various perturbations. These results underscore the effectiveness of our proposed methods in refining vision-language representations and advancing the state-of-the-art in multimodal learning.
Read more7/12/2024
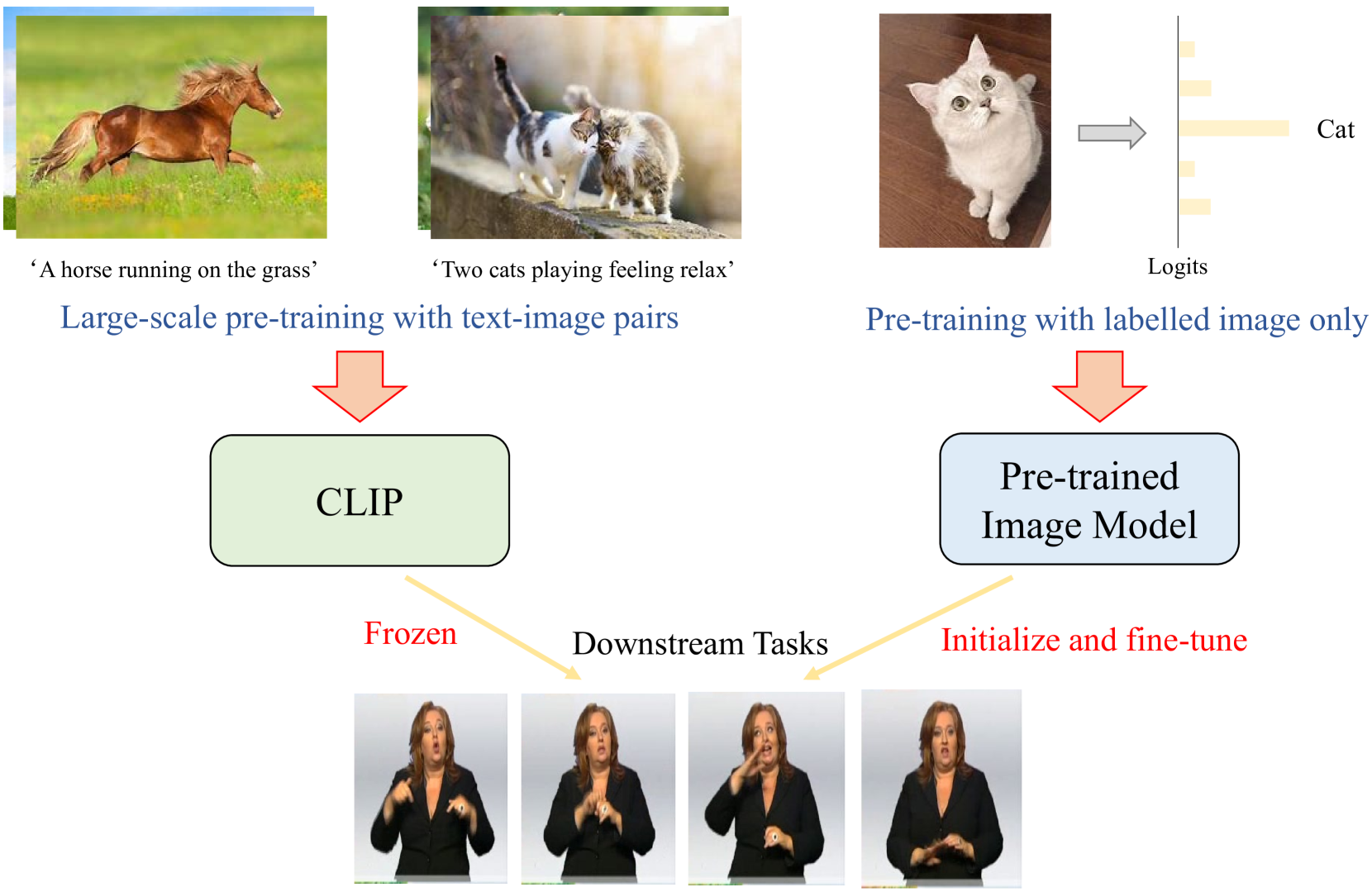
0
Improving Continuous Sign Language Recognition with Adapted Image Models
Lianyu Hu, Tongkai Shi, Liqing Gao, Zekang Liu, Wei Feng
The increase of web-scale weakly labelled image-text pairs have greatly facilitated the development of large-scale vision-language models (e.g., CLIP), which have shown impressive generalization performance over a series of downstream tasks. However, the massive model size and scarcity of available data limit their applications to fine-tune the whole model in downstream tasks. Besides, fully fine-tuning the model easily forgets the generic essential knowledge acquired in the pretraining stage and overfits the downstream data. To enable high efficiency when adapting these large vision-language models (e.g., CLIP) to performing continuous sign language recognition (CSLR) while preserving their generalizability, we propose a novel strategy (AdaptSign). Especially, CLIP is adopted as the visual backbone to extract frame-wise features whose parameters are fixed, and a set of learnable modules are introduced to model spatial sign variations or capture temporal sign movements. The introduced additional modules are quite lightweight, only owning 3.2% extra computations with high efficiency. The generic knowledge acquired in the pretraining stage is well-preserved in the frozen CLIP backbone in this process. Extensive experiments show that despite being efficient, AdaptSign is able to demonstrate superior performance across a series of CSLR benchmarks including PHOENIX14, PHOENIX14-T, CSL-Daily and CSL compared to existing methods. Visualizations show that AdaptSign could learn to dynamically pay major attention to the informative spatial regions and cross-frame trajectories in sign videos.
Read more4/15/2024