SS-BRPE: Self-Supervised Blind Room Parameter Estimation Using Attention Mechanisms

0

Sign in to get full access
Overview
- Self-Supervised Blind Room Parameter Estimation (SS-BRPE) uses attention mechanisms to estimate room acoustic parameters from audio recordings without labeled data.
- The model can infer properties like room size, wall absorption, and reverberation time from raw audio signals.
- This approach enables acoustic parameter estimation in a self-supervised manner, avoiding the need for costly room measurements.
Plain English Explanation
SS-BRPE: Self-Supervised Blind Room Parameter Estimation Using Attention Mechanisms is a new technique that can estimate the acoustic properties of a room using only audio recordings, without any labeled training data.
The key idea is to use an attention mechanism to allow the model to focus on the most relevant parts of the audio signal when inferring parameters like room size, wall absorption, and reverberation time. This self-supervised approach avoids the need for expensive and time-consuming room measurements, which are typically required to train models for this task.
By learning to estimate room acoustics directly from raw audio data, the SS-BRPE model can be applied in a wide range of real-world settings, such as smart home systems, virtual meetings, and sound design. This can improve the performance of various audio applications that rely on accurate knowledge of the acoustic environment.
Technical Explanation
The SS-BRPE model uses a deep neural network architecture to estimate room acoustic parameters from raw audio recordings in a self-supervised manner. The key components of the model include:
- Encoder: A convolutional neural network that encodes the input audio signal into a compact feature representation.
- Attention Module: An attention-based mechanism that allows the model to focus on the most relevant parts of the audio signal when estimating room parameters.
- Decoder: A set of fully connected layers that predict the room's acoustic parameters, such as room size, wall absorption, and reverberation time.
The model is trained in a self-supervised fashion, meaning it learns to estimate room parameters without access to any labeled training data. Instead, the model is trained to minimize the discrepancy between its parameter predictions and the actual acoustics of the training rooms, which are inferred from the audio recordings themselves.
The use of attention mechanisms in the SS-BRPE model enables the model to focus on the most relevant parts of the audio signal, such as reflections and reverberations, when estimating room parameters. This improves the model's performance and robustness compared to previous blind acoustic parameter estimation techniques.
Critical Analysis
The SS-BRPE paper presents a promising approach for estimating room acoustic parameters in a self-supervised manner, avoiding the need for costly room measurements. However, the authors acknowledge several limitations and areas for further research:
- The model's performance may be sensitive to the specific room configurations and audio signals used during training, which could limit its generalization to new environments.
- The paper does not provide a detailed analysis of the model's interpretability, i.e., how the attention mechanism and parameter predictions relate to the underlying room acoustics.
- The authors suggest that incorporating additional physical constraints or prior knowledge about room acoustics could further improve the model's accuracy and robustness.
Additionally, it would be valuable to explore how the SS-BRPE model could be integrated with other audio applications to enhance their performance, such as in virtual meetings, sound design, or smart home systems.
Conclusion
The SS-BRPE model represents an innovative approach to estimating room acoustic parameters in a self-supervised manner, using attention mechanisms to focus on the most relevant parts of the audio signal. This technique has the potential to enable a wide range of applications that rely on accurate knowledge of the acoustic environment, without the need for costly room measurements. While the paper identifies some limitations, the core idea of using self-supervised learning and attention to perform blind room parameter estimation is a significant contribution to the field of audio signal processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SS-BRPE: Self-Supervised Blind Room Parameter Estimation Using Attention Mechanisms
Chunxi Wang, Maoshen Jia, Meiran Li, Changchun Bao, Wenyu Jin
In recent years, dynamic parameterization of acoustic environments has garnered attention in audio processing. This focus includes room volume and reverberation time (RT60), which define local acoustics independent of sound source and receiver orientation. Previous studies show that purely attention-based models can achieve advanced results in room parameter estimation. However, their success relies on supervised pretrainings that require a large amount of labeled true values for room parameters and complex training pipelines. In light of this, we propose a novel Self-Supervised Blind Room Parameter Estimation (SS-BRPE) system. This system combines a purely attention-based model with self-supervised learning to estimate room acoustic parameters, from single-channel noisy speech signals. By utilizing unlabeled audio data for pretraining, the proposed system significantly reduces dependencies on costly labeled datasets. Our model also incorporates dynamic feature augmentation during fine-tuning to enhance adaptability and generalizability. Experimental results demonstrate that the SS-BRPE system not only achieves more superior performance in estimating room parameters than state-of-the-art (SOTA) methods but also effectively maintains high accuracy under conditions with limited labeled data. Code available at https://github.com/bjut-chunxiwang/SS-BRPE.
Read more9/10/2024

0
Exploring the Power of Pure Attention Mechanisms in Blind Room Parameter Estimation
Chunxi Wang, Maoshen Jia, Meiran Li, Changchun Bao, Wenyu Jin
Dynamic parameterization of acoustic environments has drawn widespread attention in the field of audio processing. Precise representation of local room acoustic characteristics is crucial when designing audio filters for various audio rendering applications. Key parameters in this context include reverberation time (RT60) and geometric room volume. In recent years, neural networks have been extensively applied in the task of blind room parameter estimation. However, there remains a question of whether pure attention mechanisms can achieve superior performance in this task. To address this issue, this study employs blind room parameter estimation based on monaural noisy speech signals. Various model architectures are investigated, including a proposed attention-based model. This model is a convolution-free Audio Spectrogram Transformer, utilizing patch splitting, attention mechanisms, and cross-modality transfer learning from a pretrained Vision Transformer. Experimental results suggest that the proposed attention mechanism-based model, relying purely on attention mechanisms without using convolution, exhibits significantly improved performance across various room parameter estimation tasks, especially with the help of dedicated pretraining and data augmentation schemes. Additionally, the model demonstrates more advantageous adaptability and robustness when handling variable-length audio inputs compared to existing methods.
Read more4/26/2024
0
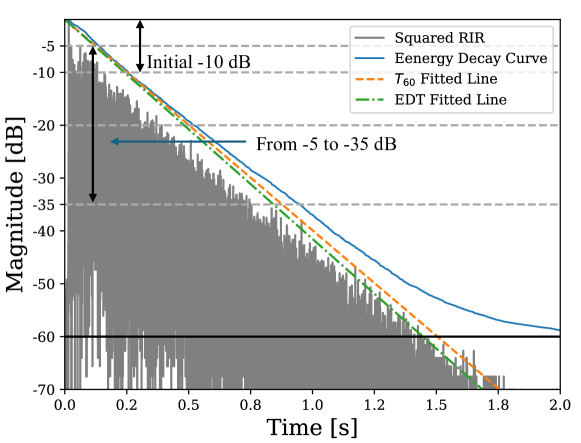
BERP: A Blind Estimator of Room Acoustic and Physical Parameters for Single-Channel Noisy Speech Signals
Lijun Wang, Yixian Lu, Ziyan Gao, Kai Li, Jianqiang Huang, Yuntao Kong, Shogo Okada
Room acoustic parameters (RAPs) and room physical parameters ( RPPs) are essential metrics for parameterizing the room acoustical characteristics (RAC) of a sound field around a listener's local environment, offering comprehensive indications for various applications. The current RAPs and RPPs estimation methods either fall short of covering broad real-world acoustic environments in the context of real background noise or lack universal frameworks for blindly estimating RAPs and RPPs from noisy single-channel speech signals, particularly sound source distances, direction-of-arrival (DOA) of sound sources, and occupancy levels. On the other hand, in this paper, we propose a novel universal blind estimation framework called the blind estimator of room acoustical and physical parameters (BERP), by introducing a new stochastic room impulse response (RIR) model, namely, the sparse stochastic impulse response (SSIR) model, and endowing the BERP with a unified encoder and multiple separate predictors to estimate RPPs and SSIR parameters in parallel. This estimation framework enables the computationally efficient and universal estimation of room parameters by solely using noisy single-channel speech signals. Finally, all the RAPs can be simultaneously derived from the RIRs synthesized from SSIR model with the estimated parameters. To evaluate the effectiveness of the proposed BERP and SSIR models, we compile a task-specific dataset from several publicly available datasets. The results reveal that the BERP achieves state-of-the-art (SOTA) performance. Moreover, the evaluation results pertaining to the SSIR RIR model also demonstrated its efficacy. The code is available on GitHub.
Read more5/17/2024
0
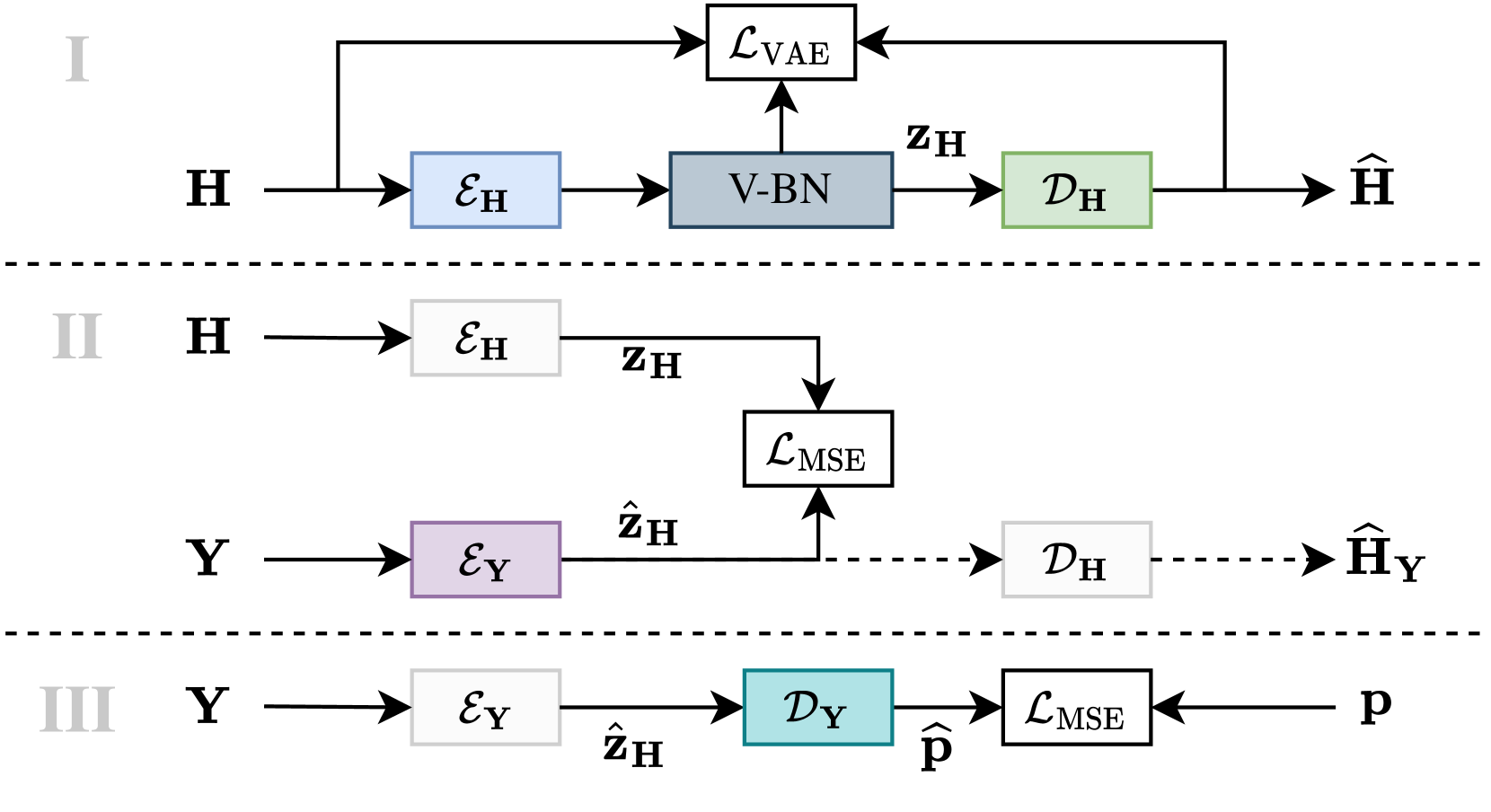
Blind Acoustic Parameter Estimation Through Task-Agnostic Embeddings Using Latent Approximations
Philipp Gotz, Cagdas Tuna, Andreas Brendel, Andreas Walther, Emanuel A. P. Habets
We present a method for blind acoustic parameter estimation from single-channel reverberant speech. The method is structured into three stages. In the first stage, a variational auto-encoder is trained to extract latent representations of acoustic impulse responses represented as mel-spectrograms. In the second stage, a separate speech encoder is trained to estimate low-dimensional representations from short segments of reverberant speech. Finally, the pre-trained speech encoder is combined with a small regression model and evaluated on two parameter regression tasks. Experimentally, the proposed method is shown to outperform a fully end-to-end trained baseline model.
Read more7/30/2024