Blind Acoustic Parameter Estimation Through Task-Agnostic Embeddings Using Latent Approximations

0
Sign in to get full access
Overview
- Presents a novel approach for estimating acoustic parameters from audio signals without task-specific training
- Leverages task-agnostic embeddings and latent approximations to enable blind parameter estimation
- Demonstrates strong performance on a range of acoustic parameter estimation tasks
Plain English Explanation
This paper introduces a new technique for estimating acoustic parameters, such as room size or reverberation, directly from audio signals. Traditionally, acoustic parameter estimation required training machine learning models on large datasets labeled with the desired parameters. However, this paper proposes a task-agnostic approach that can estimate parameters without any task-specific training.
The key idea is to learn latent representations of the audio that capture the relevant acoustic features. These latent representations are then used to approximate the target parameters through a simple regression model. This blind estimation approach avoids the need for labeled training data and can be applied to a variety of acoustic parameter estimation tasks.
The authors demonstrate that their method achieves strong performance on several benchmark tasks, including estimating room size, reverberation time, and source-receiver distance. This suggests the technique could be useful for a range of audio-based applications that require understanding the acoustic properties of an environment.
Technical Explanation
The paper proposes a novel framework for blind acoustic parameter estimation using task-agnostic embeddings and latent approximations. The key components are:
-
Task-Agnostic Embeddings: The authors train a neural network to encode audio signals into a high-dimensional latent representation that captures relevant acoustic features. This embedding model is trained in a self-supervised manner, without any labels for the target acoustic parameters.
-
Latent Approximations: Given the task-agnostic audio embeddings, the authors train a separate regression model to approximate the target acoustic parameters from the latent representations. This latent approximation step enables blind parameter estimation without the need for task-specific training data.
-
Evaluation on Benchmark Tasks: The authors evaluate their framework on a range of acoustic parameter estimation tasks, including room size, reverberation time, and source-receiver distance. They demonstrate that the proposed approach outperforms several baselines across these benchmarks.
A key advantage of this framework is its flexibility and generalization. By learning task-agnostic embeddings, the model can be applied to various acoustic parameter estimation problems without the need for custom training data or architectures. This makes the approach particularly useful for real-world audio-based applications where labeled data may be scarce or difficult to obtain.
Critical Analysis
The paper presents a compelling approach to blind acoustic parameter estimation that leverages task-agnostic embeddings and latent approximations. While the results are promising, there are a few potential limitations and areas for further research:
-
Interpretability: The paper does not provide much insight into what acoustic features are being captured by the task-agnostic embeddings. Improving the interpretability of these latent representations could help understand the underlying acoustic mechanisms being modeled.
-
Generalization to Real-World Scenarios: The evaluation is conducted on synthetic data, which may not fully capture the complexity of real-world acoustic environments. Further testing on more diverse and realistic datasets would help validate the approach's applicability to practical audio-based applications.
-
Robustness to Noise and Distortions: The paper does not explore the method's performance under challenging conditions, such as noisy or distorted audio signals. Assessing the approach's robustness to real-world audio artifacts would be an important avenue for future research.
Overall, the proposed framework represents an interesting and promising direction for blind acoustic parameter estimation. With further refinements and validation on more diverse datasets, the technique could have significant implications for a variety of audio-based applications and services.
Conclusion
This paper introduces a novel approach for estimating acoustic parameters directly from audio signals, without the need for task-specific training data. By leveraging task-agnostic embeddings and latent approximations, the proposed framework enables blind acoustic parameter estimation across a range of benchmark tasks. The strong performance demonstrated in the paper suggests this technique could be a valuable tool for audio-based applications that require understanding the acoustic properties of an environment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Blind Acoustic Parameter Estimation Through Task-Agnostic Embeddings Using Latent Approximations
Philipp Gotz, Cagdas Tuna, Andreas Brendel, Andreas Walther, Emanuel A. P. Habets
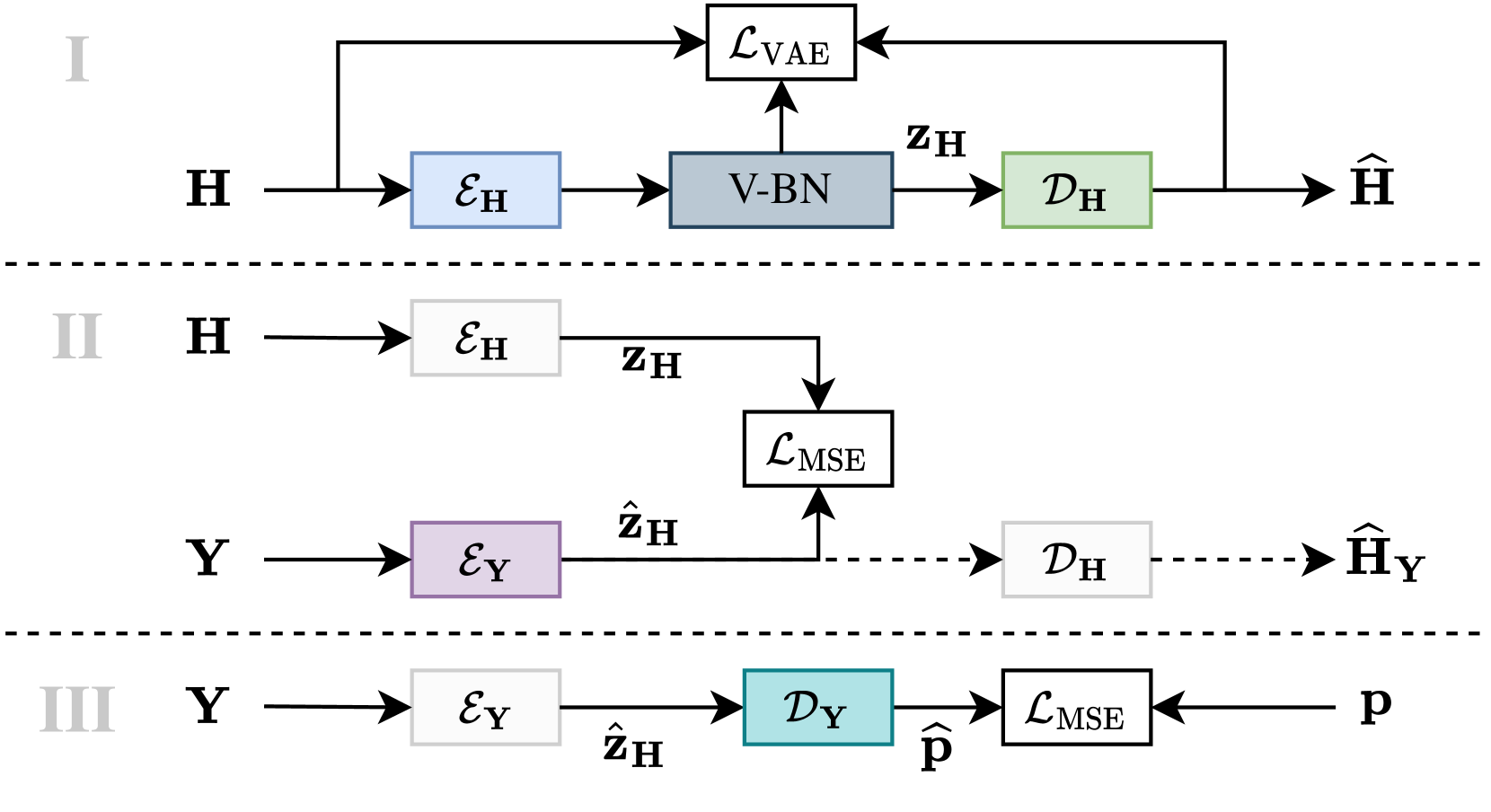
We present a method for blind acoustic parameter estimation from single-channel reverberant speech. The method is structured into three stages. In the first stage, a variational auto-encoder is trained to extract latent representations of acoustic impulse responses represented as mel-spectrograms. In the second stage, a separate speech encoder is trained to estimate low-dimensional representations from short segments of reverberant speech. Finally, the pre-trained speech encoder is combined with a small regression model and evaluated on two parameter regression tasks. Experimentally, the proposed method is shown to outperform a fully end-to-end trained baseline model.
Read more7/30/2024

0
Decoding Vocal Articulations from Acoustic Latent Representations
Mateo C'amara, Fernando Marcos, Jos'e Luis Blanco
We present a novel neural encoder system for acoustic-to-articulatory inversion. We leverage the Pink Trombone voice synthesizer that reveals articulatory parameters (e.g tongue position and vocal cord configuration). Our system is designed to identify the articulatory features responsible for producing specific acoustic characteristics contained in a neural latent representation. To generate the necessary latent embeddings, we employed two main methodologies. The first was a self-supervised variational autoencoder trained from scratch to reconstruct the input signal at the decoder stage. We conditioned its bottleneck layer with a subnetwork called the projector, which decodes the voice synthesizer's parameters. The second methodology utilized two pretrained models: EnCodec and Wav2Vec. They eliminate the need to train the encoding process from scratch, allowing us to focus on training the projector network. This approach aimed to explore the potential of these existing models in the context of acoustic-to-articulatory inversion. By reusing the pretrained models, we significantly simplified the data processing pipeline, increasing efficiency and reducing computational overhead. The primary goal of our project was to demonstrate that these neural architectures can effectively encapsulate both acoustic and articulatory features. This prediction-based approach is much faster than traditional methods focused on acoustic feature-based parameter optimization. We validated our models by predicting six different parameters and evaluating them with objective and ViSQOL subjective-equivalent metric using both synthesizer- and human-generated sounds. The results show that the predicted parameters can generate human-like vowel sounds when input into the synthesizer. We provide the dataset, code, and detailed findings to support future research in this field.
Read more6/21/2024

0
XANE: eXplainable Acoustic Neural Embeddings
Sri Harsha Dumpala, Dushyant Sharma, Chandramouli Shama Sastri, Stanislav Kruchinin, James Fosburgh, Patrick A. Naylor
We present a novel method for extracting neural embeddings that model the background acoustics of a speech signal. The extracted embeddings are used to estimate specific parameters related to the background acoustic properties of the signal in a non-intrusive manner, which allows the embeddings to be explainable in terms of those parameters. We illustrate the value of these embeddings by performing clustering experiments on unseen test data and show that the proposed embeddings achieve a mean F1 score of 95.2% for three different tasks, outperforming significantly the WavLM based signal embeddings. We also show that the proposed method can explain the embeddings by estimating 14 acoustic parameters characterizing the background acoustics, including reverberation and noise levels, overlapped speech detection, CODEC type detection and noise type detection with high accuracy and a real-time factor 17 times lower than an external baseline method.
Read more6/11/2024
🤷
0
Self-Supervised Learning of Spatial Acoustic Representation with Cross-Channel Signal Reconstruction and Multi-Channel Conformer
Bing Yang, Xiaofei Li
Supervised learning methods have shown effectiveness in estimating spatial acoustic parameters such as time difference of arrival, direct-to-reverberant ratio and reverberation time. However, they still suffer from the simulation-to-reality generalization problem due to the mismatch between simulated and real-world acoustic characteristics and the deficiency of annotated real-world data. To this end, this work proposes a self-supervised method that takes full advantage of unlabeled data for spatial acoustic parameter estimation. First, a new pretext task, i.e. cross-channel signal reconstruction (CCSR), is designed to learn a universal spatial acoustic representation from unlabeled multi-channel microphone signals. We mask partial signals of one channel and ask the model to reconstruct them, which makes it possible to learn spatial acoustic information from unmasked signals and extract source information from the other microphone channel. An encoder-decoder structure is used to disentangle the two kinds of information. By fine-tuning the pre-trained spatial encoder with a small annotated dataset, this encoder can be used to estimate spatial acoustic parameters. Second, a novel multi-channel audio Conformer (MC-Conformer) is adopted as the encoder model architecture, which is suitable for both the pretext and downstream tasks. It is carefully designed to be able to capture the local and global characteristics of spatial acoustics exhibited in the time-frequency domain. Experimental results of five acoustic parameter estimation tasks on both simulated and real-world data show the effectiveness of the proposed method. To the best of our knowledge, this is the first self-supervised learning method in the field of spatial acoustic representation learning and multi-channel audio signal processing.
Read more9/10/2024