SSE: Multimodal Semantic Data Selection and Enrichment for Industrial-scale Data Assimilation

0
Sign in to get full access
Overview
- A paper on a method called "SSE" (Multimodal Semantic Data Selection and Enrichment) for industrial-scale data assimilation
- Focuses on improving data selection and enrichment for machine learning models
- Proposes a framework to leverage multimodal data and semantics for more effective data curation
Plain English Explanation
The paper introduces a method called "SSE" (Multimodal Semantic Data Selection and Enrichment) that aims to improve the way data is selected and enriched for training machine learning models, particularly in industrial-scale applications.
The core idea is to leverage multimodal data (e.g., text, images, sensor data) and semantic information to more intelligently curate the data used to train models. This helps ensure the models are trained on the most relevant and informative data, which can lead to better performance.
For example, imagine you're building a model to detect defects in manufactured products. Instead of just feeding the model random images of products, the SSE framework would help you identify and select the most relevant images - maybe ones that highlight specific defect types or come from similar production lines. It would also enrich the data with additional semantic information, like the type of defect or the manufacturing process.
By incorporating this multimodal and semantic data, the model can learn more effectively and generalize better to new, unseen data. This is particularly important in industrial settings where the data can be noisy, high-dimensional, and rapidly evolving.
Technical Explanation
The SSE framework consists of two key components:
-
Multimodal Semantic Data Selection: This module leverages multimodal data (e.g., text, images, sensor data) and semantic information to intelligently select the most relevant data for training machine learning models. It uses techniques like cross-modal retrieval and semantic clustering to identify the most informative and representative data points.
-
Multimodal Semantic Data Enrichment: This component takes the selected data and further enhances it with additional semantic information, such as labels, attributes, and relationships. This enriched data can then be used to train more robust and generalizable machine learning models.
The paper presents experiments demonstrating the effectiveness of the SSE framework on several real-world industrial datasets, including product defect detection and predictive maintenance tasks. The results show that the SSE-enhanced models outperform baseline approaches that use traditional data selection and curation methods.
Critical Analysis
The paper presents a compelling approach to addressing the challenges of data selection and enrichment in industrial-scale machine learning applications. The incorporation of multimodal data and semantic information is a promising direction, as it can help capture the complex, high-dimensional nature of real-world industrial data.
However, the paper does not discuss the computational and memory requirements of the SSE framework, which could be a significant concern for practical deployment in resource-constrained industrial settings. Additionally, the paper could have explored the generalizability of the framework to a wider range of industrial applications and data modalities.
Further research could also investigate the impact of different semantic enrichment techniques, as well as the potential for active learning or human-in-the-loop approaches to refine the data selection and enrichment processes.
Conclusion
The SSE framework presented in this paper offers a promising approach to improving data selection and enrichment for industrial-scale machine learning applications. By leveraging multimodal data and semantic information, the framework can help identify the most relevant and informative data for training more robust and generalizable models.
The potential benefits of this approach include better model performance, improved generalization, and more efficient use of industrial data - all of which can have significant implications for productivity, quality, and safety in industrial settings. As the field of machine learning continues to advance, techniques like SSE will likely play an increasingly important role in unlocking the full potential of industrial data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SSE: Multimodal Semantic Data Selection and Enrichment for Industrial-scale Data Assimilation
Maying Shen, Nadine Chang, Sifei Liu, Jose M. Alvarez
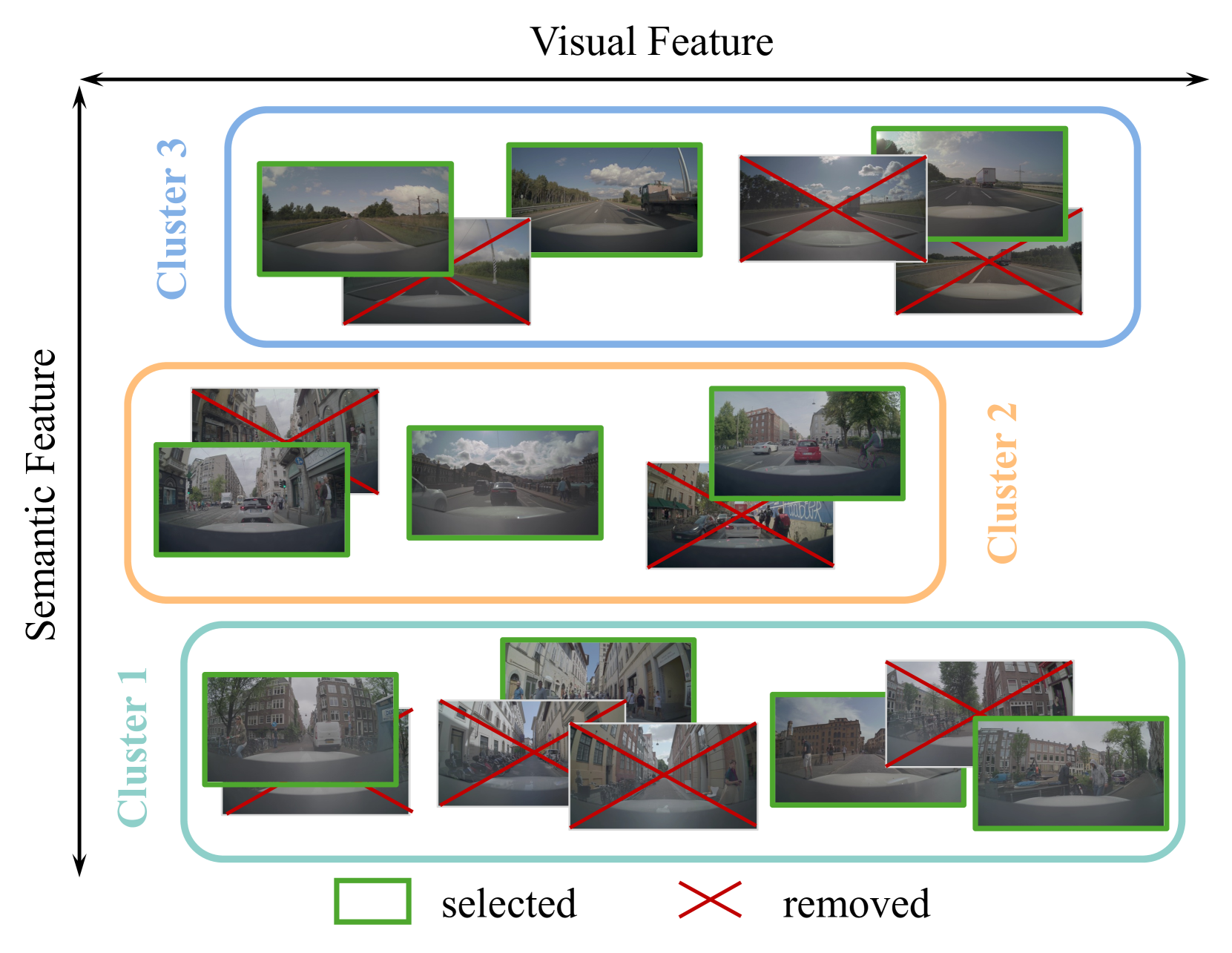
In recent years, the data collected for artificial intelligence has grown to an unmanageable amount. Particularly within industrial applications, such as autonomous vehicles, model training computation budgets are being exceeded while model performance is saturating -- and yet more data continues to pour in. To navigate the flood of data, we propose a framework to select the most semantically diverse and important dataset portion. Then, we further semantically enrich it by discovering meaningful new data from a massive unlabeled data pool. Importantly, we can provide explainability by leveraging foundation models to generate semantics for every data point. We quantitatively show that our Semantic Selection and Enrichment framework (SSE) can a) successfully maintain model performance with a smaller training dataset and b) improve model performance by enriching the smaller dataset without exceeding the original dataset size. Consequently, we demonstrate that semantic diversity is imperative for optimal data selection and model performance.
Read more9/24/2024
📊
0
Semantic-Aware Representation of Multi-Modal Data for Data Ingress: A Literature Review
Pierre Lamart, Yinan Yu, Christian Berger
Machine Learning (ML) is continuously permeating a growing amount of application domains. Generative AI such as Large Language Models (LLMs) also sees broad adoption to process multi-modal data such as text, images, audio, and video. While the trend is to use ever-larger datasets for training, managing this data efficiently has become a significant practical challenge in the industry-double as much data is certainly not double as good. Rather the opposite is important since getting an understanding of the inherent quality and diversity of the underlying data lakes is a growing challenge for application-specific ML as well as for fine-tuning foundation models. Furthermore, information retrieval (IR) from expanding data lakes is complicated by the temporal dimension inherent in time-series data which must be considered to determine its semantic value. This study focuses on the different semantic-aware techniques to extract embeddings from mono-modal, multi-modal, and cross-modal data to enhance IR capabilities in a growing data lake. Articles were collected to summarize information about the state-of-the-art techniques focusing on applications of embedding for three different categories of data modalities.
Read more7/18/2024
0
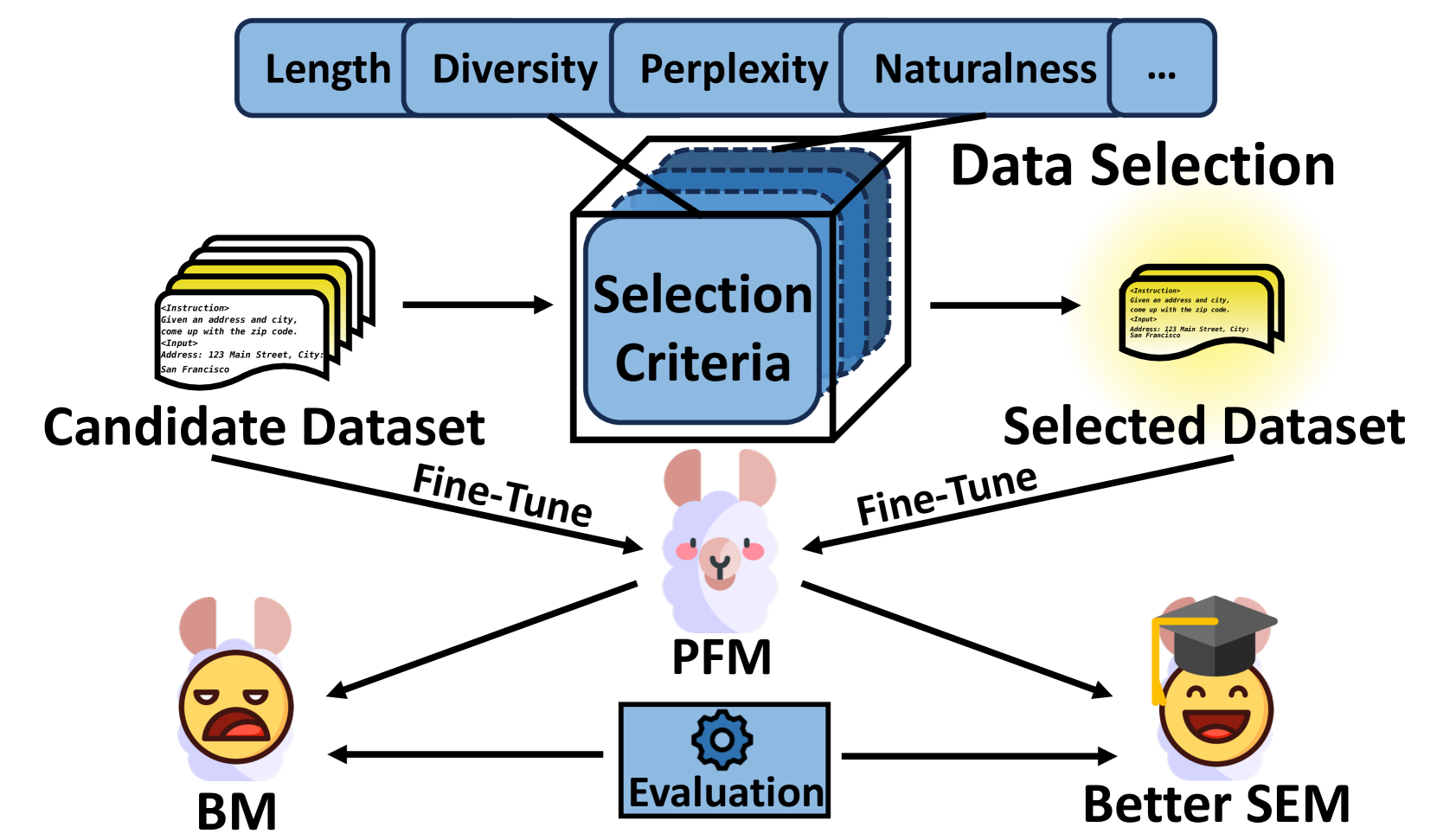
Take the essence and discard the dross: A Rethinking on Data Selection for Fine-Tuning Large Language Models
Ziche Liu, Rui Ke, Feng Jiang, Haizhou Li
Data selection for fine-tuning Large Language Models (LLMs) aims to select a high-quality subset from a given candidate dataset to train a Pending Fine-tune Model (PFM) into a Selective-Enhanced Model (SEM). It can improve the model performance and accelerate the training process. Although a few surveys have investigated related works of data selection, there is a lack of comprehensive comparison between existing methods due to their various experimental settings. To address this issue, we first propose a three-stage scheme for data selection and comprehensively review existing works according to this scheme. Then, we design a unified comparing method with ratio-based efficiency indicators and ranking-based feasibility indicators to overcome the difficulty of comparing various models with diverse experimental settings. After an in-depth comparative analysis, we find that the more targeted method with data-specific and model-specific quality labels has higher efficiency, but the introduction of additional noise information should be avoided when designing selection algorithms. Finally, we summarize the trends in data selection and highlight the short-term and long-term challenges to guide future research.
Read more6/21/2024

0
Semi-Supervised Semantic Segmentation with Professional and General Training
Yuting Hong, Hui Xiao, Huazheng Hao, Xiaojie Qiu, Baochen Yao, Chengbin Peng
With the advancement of autonomous driving, semantic segmentation has achieved remarkable progress. The training of such networks heavily relies on image annotations, which are very expensive to obtain. Semi-supervised learning can utilize both labeled data and unlabeled data with the help of pseudo-labels. However, in many real-world scenarios where classes are imbalanced, majority classes often play a dominant role during training and the learning quality of minority classes can be undermined. To overcome this limitation, we propose a synergistic training framework, including a professional training module to enhance minority class learning and a general training module to learn more comprehensive semantic information. Based on a pixel selection strategy, they can iteratively learn from each other to reduce error accumulation and coupling. In addition, a dual contrastive learning with anchors is proposed to guarantee more distinct decision boundaries. In experiments, our framework demonstrates superior performance compared to state-of-the-art methods on benchmark datasets.
Read more9/24/2024