Take the essence and discard the dross: A Rethinking on Data Selection for Fine-Tuning Large Language Models
2406.14115
0
0
Abstract
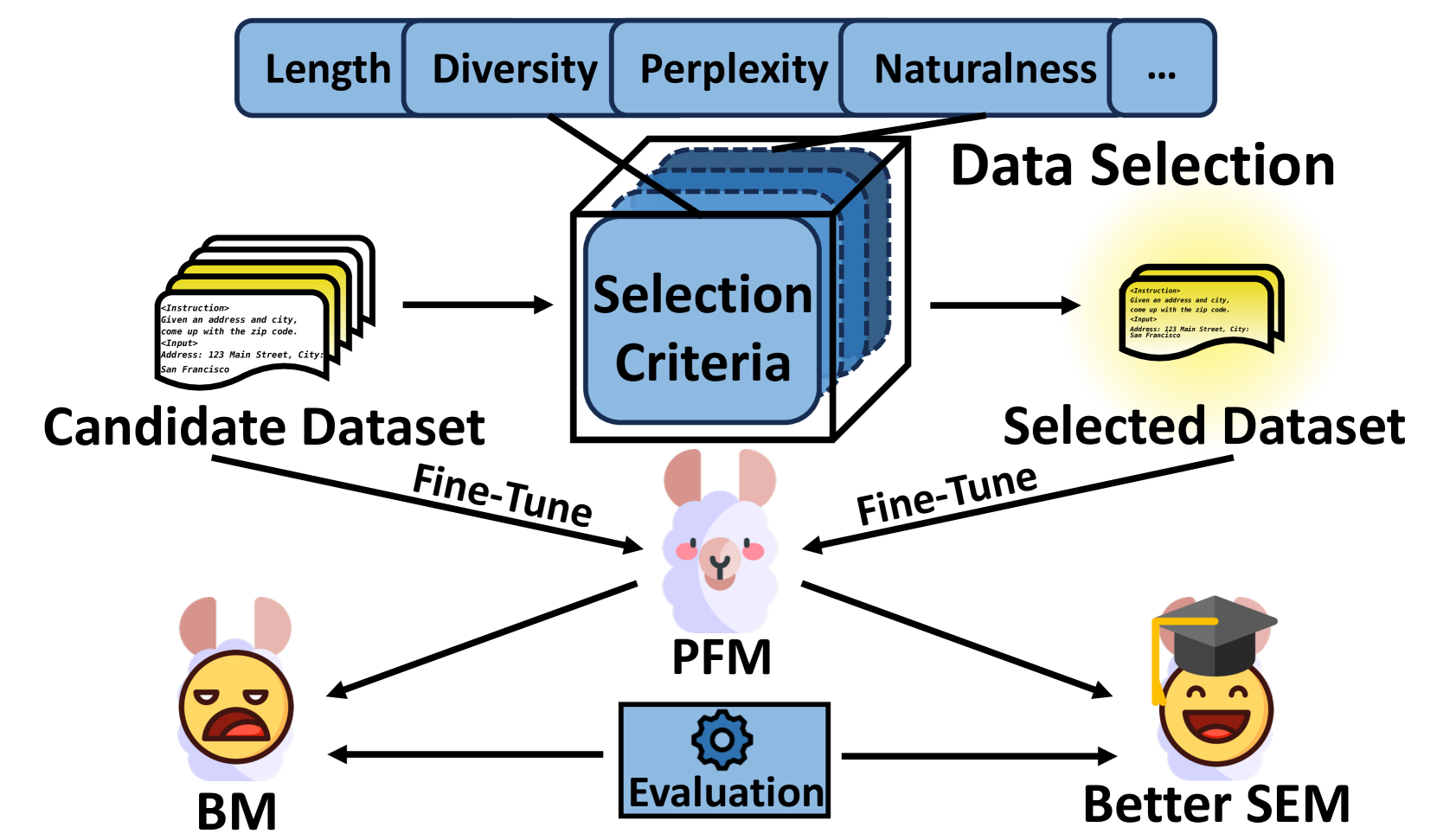
Data selection for fine-tuning Large Language Models (LLMs) aims to select a high-quality subset from a given candidate dataset to train a Pending Fine-tune Model (PFM) into a Selective-Enhanced Model (SEM). It can improve the model performance and accelerate the training process. Although a few surveys have investigated related works of data selection, there is a lack of comprehensive comparison between existing methods due to their various experimental settings. To address this issue, we first propose a three-stage scheme for data selection and comprehensively review existing works according to this scheme. Then, we design a unified comparing method with ratio-based efficiency indicators and ranking-based feasibility indicators to overcome the difficulty of comparing various models with diverse experimental settings. After an in-depth comparative analysis, we find that the more targeted method with data-specific and model-specific quality labels has higher efficiency, but the introduction of additional noise information should be avoided when designing selection algorithms. Finally, we summarize the trends in data selection and highlight the short-term and long-term challenges to guide future research.
Create account to get full access
Overview
- This research paper proposes a new approach to data selection for fine-tuning large language models (LLMs).
- The authors argue that the common practice of using all available data for fine-tuning can lead to suboptimal performance, and they suggest a more targeted data selection scheme.
- The paper introduces a novel data selection method that aims to identify the most relevant and informative data for fine-tuning, while discarding irrelevant or redundant data.
- The proposed approach is evaluated on various benchmarks and shows improvements over the standard fine-tuning approach.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. These models are often fine-tuned, or further trained, on specialized datasets to improve their performance on specific tasks. However, the traditional approach of using all available data for fine-tuning may not always be the best strategy.
The authors of this paper suggest a more selective approach to data selection for fine-tuning LLMs. They argue that not all data is equally valuable for fine-tuning, and that including irrelevant or redundant data can actually hinder the model's performance. Instead, they propose a method that aims to identify the most essential and informative data for fine-tuning, while discarding the "dross" or less useful information.
The key idea is to focus on the "essence" of the data - the most relevant and high-quality information that can truly improve the model's capabilities. This selective approach, the authors claim, can lead to better fine-tuning results compared to using all available data.
The paper introduces a novel data selection algorithm that evaluates the relevance and informativeness of each data point, and then selectively includes the most valuable ones for fine-tuning. The authors test their approach on various benchmarks and show that it outperforms the standard fine-tuning approach.
This research suggests that a more thoughtful and targeted approach to data selection can be a powerful tool for improving the performance of large language models, which have become increasingly important in a wide range of applications.
Technical Explanation
The paper proposes a new data selection scheme for fine-tuning large language models (LLMs), which aims to identify and utilize the most relevant and informative data while discarding irrelevant or redundant information.
The authors argue that the common practice of using all available data for fine-tuning can lead to suboptimal performance, as not all data is equally valuable for a given task. To address this, they introduce a novel data selection method that evaluates the relevance and informativeness of each data point and selectively includes the most valuable ones for fine-tuning.
The proposed data selection scheme consists of three key steps:
-
Data Scoring: The authors develop a scoring function that assesses the relevance and informativeness of each data point based on various features, such as semantic similarity to the target task, linguistic complexity, and diversity.
-
Data Filtering: Using the data scores, the method filters out the least valuable data points, discarding the "dross" and retaining only the most essential information.
-
Fine-Tuning: The selected data is then used to fine-tune the LLM, with the goal of improving its performance on the target task.
The authors evaluate their approach on various benchmarks, including Get More for Less: Principled Data Selection for Fine-Tuning Large Language Models, Large Language Model Guided Document Selection, Analyzing the Impact of Data Selection for Fine-tuning in Economic NLP, and Less is More: Selecting Influential Data for Targeted Instruction Tuning. The results show that the proposed data selection method outperforms the standard fine-tuning approach, demonstrating the benefits of a more targeted and selective approach to data utilization.
Critical Analysis
The paper presents a compelling case for rethinking data selection for fine-tuning large language models. The authors' key insight - that not all data is equally valuable and that including irrelevant or redundant data can hinder model performance - is an important one that deserves further exploration.
One potential limitation of the proposed approach is the complexity of the data scoring function, which relies on a variety of features to assess the relevance and informativeness of each data point. While this multi-faceted evaluation may lead to more accurate data selection, it also introduces additional computational and implementation challenges. The authors could explore simpler scoring methods or ways to streamline the data selection process.
Additionally, the paper does not delve deeply into the potential biases or limitations of the data selection algorithm itself. For example, the way the scoring function is designed could inadvertently introduce biases or overlooked factors that affect the final model performance. Further investigation into the robustness and fairness of the data selection approach would be valuable.
Despite these potential issues, the core idea of this research - data-efficient fine-tuning of LLM-based recommendation systems - is a promising direction that could lead to more efficient and effective fine-tuning of large language models. The authors' work serves as an important starting point for rethinking data selection strategies and paves the way for future research in this area.
Conclusion
This paper presents a novel approach to data selection for fine-tuning large language models, which aims to identify and utilize the most relevant and informative data while discarding irrelevant or redundant information. The authors argue that the common practice of using all available data for fine-tuning can lead to suboptimal performance, and they introduce a data selection scheme that selectively includes the most valuable data points.
The proposed method demonstrates improvements over the standard fine-tuning approach on various benchmarks, suggesting that a more targeted and selective approach to data utilization can be a powerful tool for enhancing the performance of large language models. This research highlights the importance of rethinking data selection strategies and provides a promising direction for future work in this area.
As large language models continue to play an increasingly prominent role in a wide range of applications, the ability to fine-tune these models efficiently and effectively will become increasingly crucial. The insights and techniques presented in this paper offer valuable contributions to this ongoing effort, and may inspire further advancements in the field of language model optimization and deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs
Feiyang Kang, Hoang Anh Just, Yifan Sun, Himanshu Jahagirdar, Yuanzhi Zhang, Rongxing Du, Anit Kumar Sahu, Ruoxi Jia
0
0
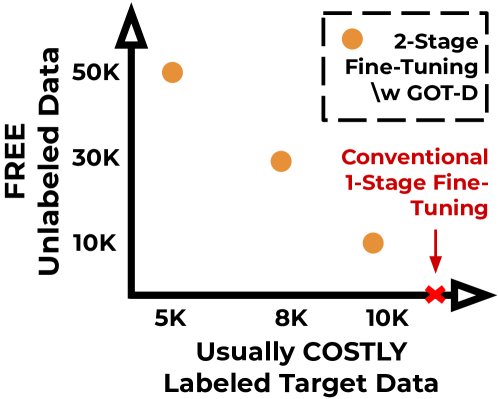
This work focuses on leveraging and selecting from vast, unlabeled, open data to pre-fine-tune a pre-trained language model. The goal is to minimize the need for costly domain-specific data for subsequent fine-tuning while achieving desired performance levels. While many data selection algorithms have been designed for small-scale applications, rendering them unsuitable for our context, some emerging methods do cater to language data scales. However, they often prioritize data that aligns with the target distribution. While this strategy may be effective when training a model from scratch, it can yield limited results when the model has already been pre-trained on a different distribution. Differing from prior work, our key idea is to select data that nudges the pre-training distribution closer to the target distribution. We show the optimality of this approach for fine-tuning tasks under certain conditions. We demonstrate the efficacy of our methodology across a diverse array of tasks (NLU, NLG, zero-shot) with models up to 2.7B, showing that it consistently surpasses other selection methods. Moreover, our proposed method is significantly faster than existing techniques, scaling to millions of samples within a single GPU hour. Our code is open-sourced (Code repository: https://anonymous.4open.science/r/DV4LLM-D761/ ). While fine-tuning offers significant potential for enhancing performance across diverse tasks, its associated costs often limit its widespread adoption; with this work, we hope to lay the groundwork for cost-effective fine-tuning, making its benefits more accessible.
5/7/2024
Large Language Model-guided Document Selection
Xiang Kong, Tom Gunter, Ruoming Pang
0
0
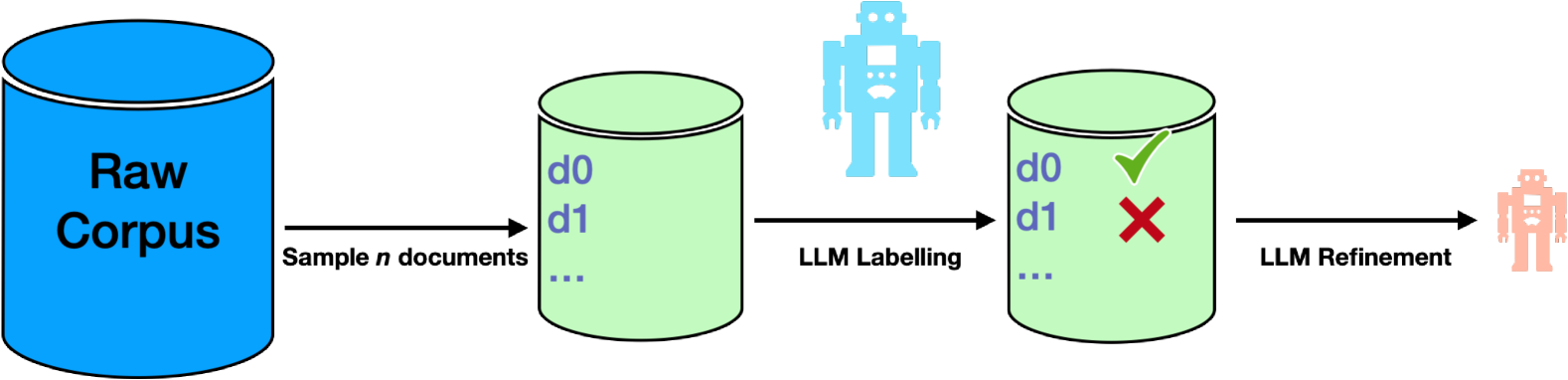
Large Language Model (LLM) pre-training exhausts an ever growing compute budget, yet recent research has demonstrated that careful document selection enables comparable model quality with only a fraction of the FLOPs. Inspired by efforts suggesting that domain-specific training document selection is in fact an interpretable process [Gunasekar et al., 2023], as well as research showing that instruction-finetuned LLMs are adept zero-shot data labelers [Gilardi et al.,2023], we explore a promising direction for scalable general-domain document selection; employing a prompted LLM as a document grader, we distill quality labels into a classifier model, which is applied at scale to a large, and already heavily-filtered, web-crawl-derived corpus autonomously. Following the guidance of this classifier, we drop 75% of the corpus and train LLMs on the remaining data. Results across multiple benchmarks show that: 1. Filtering allows us to quality-match a model trained on the full corpus across diverse benchmarks with at most 70% of the FLOPs, 2. More capable LLM labelers and classifier models lead to better results that are less sensitive to the labeler's prompt, 3. In-context learning helps to boost the performance of less-capable labeling models. In all cases we use open-source datasets, models, recipes, and evaluation frameworks, so that results can be reproduced by the community.
6/10/2024
Analyzing the Impact of Data Selection and Fine-Tuning on Economic and Political Biases in LLMs
Ahmed Agiza, Mohamed Mostagir, Sherief Reda
0
0
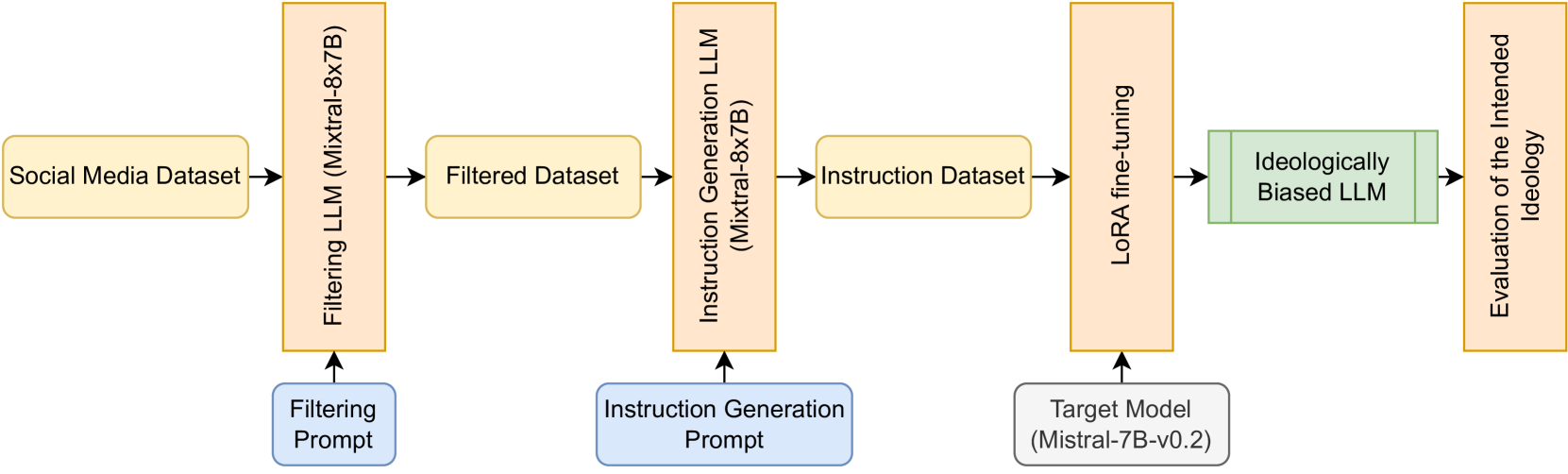
In an era where language models are increasingly integrated into decision-making and communication, understanding the biases within Large Language Models (LLMs) becomes imperative, especially when these models are applied in the economic and political domains. This work investigates the impact of fine-tuning and data selection on economic and political biases in LLM. We explore the methodological aspects of biasing LLMs towards specific ideologies, mindful of the biases that arise from their extensive training on diverse datasets. Our approach, distinct from earlier efforts that either focus on smaller models or entail resource-intensive pre-training, employs Parameter-Efficient Fine-Tuning (PEFT) techniques. These techniques allow for the alignment of LLMs with targeted ideologies by modifying a small subset of parameters. We introduce a systematic method for dataset selection, annotation, and instruction tuning, and we assess its effectiveness through both quantitative and qualitative evaluations. Our work analyzes the potential of embedding specific biases into LLMs and contributes to the dialogue on the ethical application of AI, highlighting the importance of deploying AI in a manner that aligns with societal values.
4/23/2024

LESS: Selecting Influential Data for Targeted Instruction Tuning
Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, Danqi Chen
0
0
Instruction tuning has unlocked powerful capabilities in large language models (LLMs), effectively using combined datasets to develop generalpurpose chatbots. However, real-world applications often require a specialized suite of skills (e.g., reasoning). The challenge lies in identifying the most relevant data from these extensive datasets to effectively develop specific capabilities, a setting we frame as targeted instruction tuning. We propose LESS, an optimizer-aware and practically efficient algorithm to effectively estimate data influences and perform Low-rank gradiEnt Similarity Search for instruction data selection. Crucially, LESS adapts existing influence formulations to work with the Adam optimizer and variable-length instruction data. LESS first constructs a highly reusable and transferable gradient datastore with low-dimensional gradient features and then selects examples based on their similarity to few-shot examples embodying a specific capability. Experiments show that training on a LESS-selected 5% of the data can often outperform training on the full dataset across diverse downstream tasks. Furthermore, the selected data is highly transferable: smaller models can be leveraged to select useful data for larger models and models from different families. Our qualitative analysis shows that our method goes beyond surface form cues to identify data that exemplifies the necessary reasoning skills for the intended downstream application.
6/14/2024