SSM Meets Video Diffusion Models: Efficient Video Generation with Structured State Spaces
2403.07711
0
0
Abstract
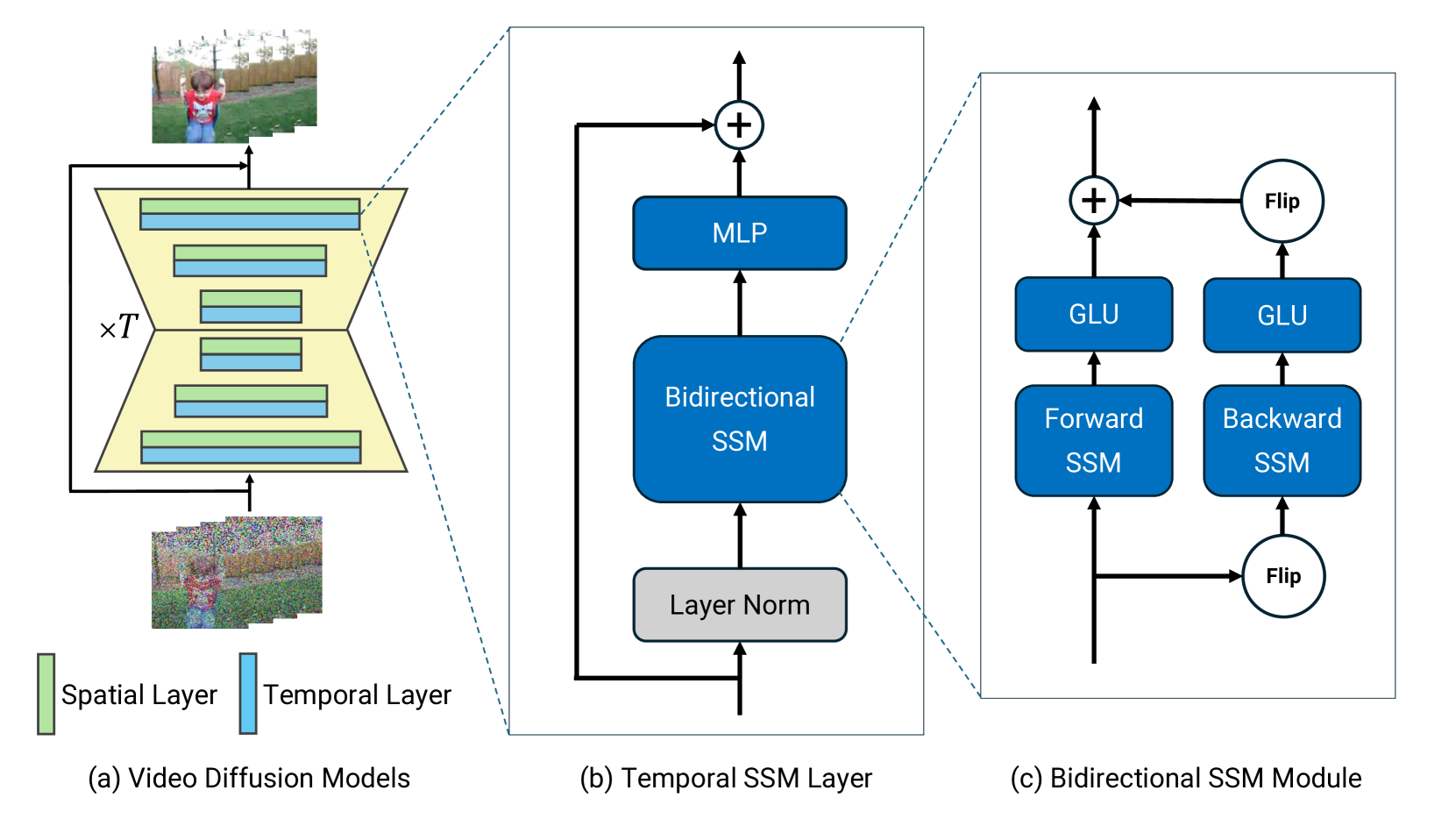
Given the remarkable achievements in image generation through diffusion models, the research community has shown increasing interest in extending these models to video generation. Recent diffusion models for video generation have predominantly utilized attention layers to extract temporal features. However, attention layers are limited by their memory consumption, which increases quadratically with the length of the sequence. This limitation presents significant challenges when attempting to generate longer video sequences using diffusion models. To overcome this challenge, we propose leveraging state-space models (SSMs). SSMs have recently gained attention as viable alternatives due to their linear memory consumption relative to sequence length. In the experiments, we first evaluate our SSM-based model with UCF101, a standard benchmark of video generation. In addition, to investigate the potential of SSMs for longer video generation, we perform an experiment using the MineRL Navigate dataset, varying the number of frames to 64, 200, and 400. In these settings, our SSM-based model can considerably save memory consumption for longer sequences, while maintaining competitive FVD scores to the attention-based models. Our codes are available at https://github.com/shim0114/SSM-Meets-Video-Diffusion-Models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a new video generation model that combines structured state space models (SSMs) with diffusion-based video generation.
- The key idea is to use an SSM to efficiently represent the video's dynamics, which can then be used to guide a diffusion model for high-quality video synthesis.
- The authors demonstrate that this hybrid approach outperforms previous state-of-the-art video diffusion models in terms of sample quality and generation speed.
Plain English Explanation
The paper presents a new way to generate realistic videos using a combination of two machine learning techniques - structured state space models (SSMs) and diffusion models.
SSMs are used to efficiently capture the underlying dynamics of a video, such as the movement of objects over time. This structured representation of the video's state allows the model to generate new videos more quickly and with better quality compared to previous diffusion-only approaches.
The diffusion model is then used to add fine-grained details and realistic textures to the generated videos. By combining the strengths of SSMs and diffusion, the authors are able to produce high-quality video samples faster than previous state-of-the-art video generation models.
Imagine you want to generate a video of a person walking down the street. The SSM part of the model would learn how the person's body moves over time, allowing it to efficiently generate the basic motion. The diffusion part would then add in realistic details like the person's clothing, the texture of the pavement, and other environmental elements to make the final video look natural and lifelike.
Technical Explanation
The paper proposes a novel video generation model that combines structured state space models (SSMs) and diffusion-based video generation. The key components are:
- A structured state space model that learns to efficiently represent the dynamics of the video, capturing the temporal evolution of video frames.
- A diffusion model that generates high-quality video frames conditioned on the state representations from the SSM.
- A training procedure that jointly optimizes the SSM and diffusion model to ensure coherent and realistic video generation.
The authors demonstrate the effectiveness of this hybrid approach through extensive experiments on several video datasets. Compared to previous state-of-the-art video diffusion models, their model achieves superior sample quality while being significantly faster at generating new videos.
Critical Analysis
The paper presents a compelling approach to improving the efficiency and quality of video generation using the combination of SSMs and diffusion models. Some potential limitations and areas for further research include:
- The paper only evaluates the model on relatively simple video datasets (e.g. moving MNIST). Applying the approach to more complex, real-world video data would be an important next step.
- The authors do not provide a detailed ablation study to tease apart the individual contributions of the SSM and diffusion components. This makes it difficult to fully understand the relative importance of each part of the hybrid model.
- The paper focuses on unconditional video generation. Extending the approach to enable controlled video generation, e.g. by conditioning on text or images, could greatly expand its practical applications.
- The theoretical connections between SSMs and diffusion models are not explored in depth. A more rigorous analysis of how these two frameworks can be combined could lead to further improvements in model design and performance.
Overall, the paper presents a promising direction for advancing the state-of-the-art in efficient and high-quality video generation, and the proposed hybrid approach is likely to inspire further research in this area.
Conclusion
This paper introduces a novel video generation model that combines the strengths of structured state space models and diffusion-based generation. By using an SSM to efficiently capture the underlying video dynamics, and then conditioning a diffusion model on this structured representation, the authors are able to generate high-quality videos significantly faster than previous state-of-the-art approaches.
The hybrid nature of the model allows it to leverage the complementary benefits of these two machine learning techniques, resulting in significant improvements in both sample quality and generation speed. While the current evaluation is limited to simpler video datasets, the general framework could be extended to handle more complex real-world videos, opening up new possibilities for practical applications of this technology.
Related Papers
State Space Model for New-Generation Network Alternative to Transformers: A Survey
Xiao Wang, Shiao Wang, Yuhe Ding, Yuehang Li, Wentao Wu, Yao Rong, Weizhe Kong, Ju Huang, Shihao Li, Haoxiang Yang, Ziwen Wang, Bo Jiang, Chenglong Li, Yaowei Wang, Yonghong Tian, Jin Tang
0
0
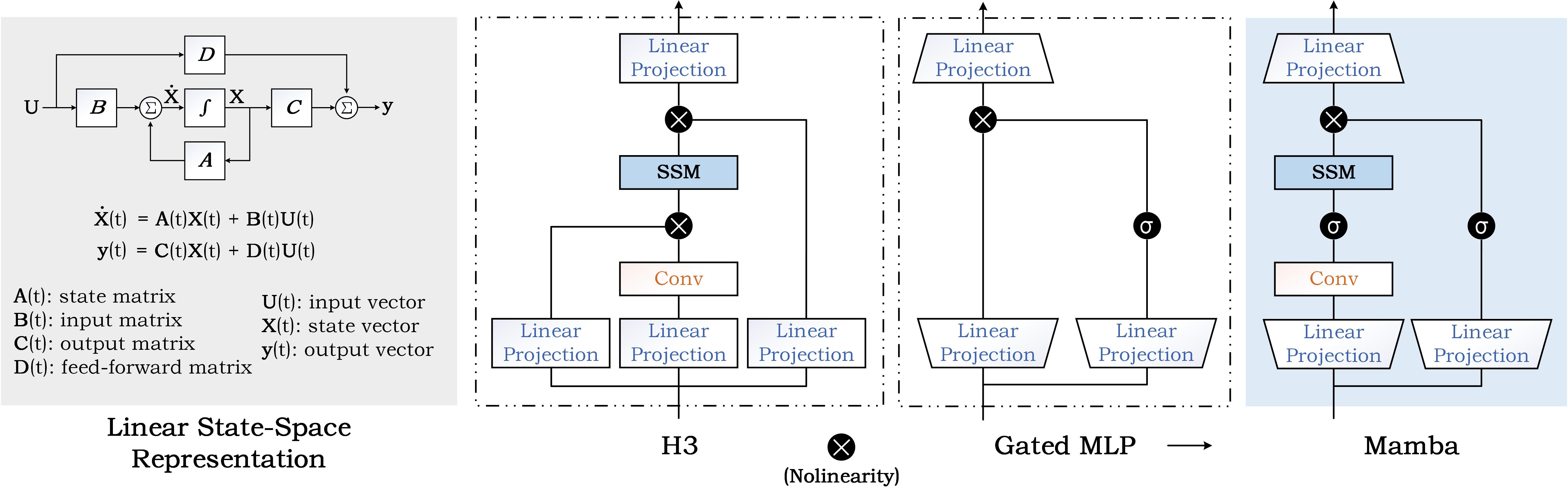
In the post-deep learning era, the Transformer architecture has demonstrated its powerful performance across pre-trained big models and various downstream tasks. However, the enormous computational demands of this architecture have deterred many researchers. To further reduce the complexity of attention models, numerous efforts have been made to design more efficient methods. Among them, the State Space Model (SSM), as a possible replacement for the self-attention based Transformer model, has drawn more and more attention in recent years. In this paper, we give the first comprehensive review of these works and also provide experimental comparisons and analysis to better demonstrate the features and advantages of SSM. Specifically, we first give a detailed description of principles to help the readers quickly capture the key ideas of SSM. After that, we dive into the reviews of existing SSMs and their various applications, including natural language processing, computer vision, graph, multi-modal and multi-media, point cloud/event stream, time series data, and other domains. In addition, we give statistical comparisons and analysis of these models and hope it helps the readers to understand the effectiveness of different structures on various tasks. Then, we propose possible research points in this direction to better promote the development of the theoretical model and application of SSM. More related works will be continuously updated on the following GitHub: https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List.
4/16/2024
State Space Models for Event Cameras
Nikola Zubi'c, Mathias Gehrig, Davide Scaramuzza
0
0
Today, state-of-the-art deep neural networks that process event-camera data first convert a temporal window of events into dense, grid-like input representations. As such, they exhibit poor generalizability when deployed at higher inference frequencies (i.e., smaller temporal windows) than the ones they were trained on. We address this challenge by introducing state-space models (SSMs) with learnable timescale parameters to event-based vision. This design adapts to varying frequencies without the need to retrain the network at different frequencies. Additionally, we investigate two strategies to counteract aliasing effects when deploying the model at higher frequencies. We comprehensively evaluate our approach against existing methods based on RNN and Transformer architectures across various benchmarks, including Gen1 and 1 Mpx event camera datasets. Our results demonstrate that SSM-based models train 33% faster and also exhibit minimal performance degradation when tested at higher frequencies than the training input. Traditional RNN and Transformer models exhibit performance drops of more than 20 mAP, with SSMs having a drop of 3.76 mAP, highlighting the effectiveness of SSMs in event-based vision tasks.
4/19/2024

StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, Qibin Hou
0
0
For recent diffusion-based generative models, maintaining consistent content across a series of generated images, especially those containing subjects and complex details, presents a significant challenge. In this paper, we propose a new way of self-attention calculation, termed Consistent Self-Attention, that significantly boosts the consistency between the generated images and augments prevalent pretrained diffusion-based text-to-image models in a zero-shot manner. To extend our method to long-range video generation, we further introduce a novel semantic space temporal motion prediction module, named Semantic Motion Predictor. It is trained to estimate the motion conditions between two provided images in the semantic spaces. This module converts the generated sequence of images into videos with smooth transitions and consistent subjects that are significantly more stable than the modules based on latent spaces only, especially in the context of long video generation. By merging these two novel components, our framework, referred to as StoryDiffusion, can describe a text-based story with consistent images or videos encompassing a rich variety of contents. The proposed StoryDiffusion encompasses pioneering explorations in visual story generation with the presentation of images and videos, which we hope could inspire more research from the aspect of architectural modifications. Our code is made publicly available at https://github.com/HVision-NKU/StoryDiffusion.
5/3/2024
🤖
LLM-grounded Video Diffusion Models
Long Lian, Baifeng Shi, Adam Yala, Trevor Darrell, Boyi Li
0
0
Text-conditioned diffusion models have emerged as a promising tool for neural video generation. However, current models still struggle with intricate spatiotemporal prompts and often generate restricted or incorrect motion. To address these limitations, we introduce LLM-grounded Video Diffusion (LVD). Instead of directly generating videos from the text inputs, LVD first leverages a large language model (LLM) to generate dynamic scene layouts based on the text inputs and subsequently uses the generated layouts to guide a diffusion model for video generation. We show that LLMs are able to understand complex spatiotemporal dynamics from text alone and generate layouts that align closely with both the prompts and the object motion patterns typically observed in the real world. We then propose to guide video diffusion models with these layouts by adjusting the attention maps. Our approach is training-free and can be integrated into any video diffusion model that admits classifier guidance. Our results demonstrate that LVD significantly outperforms its base video diffusion model and several strong baseline methods in faithfully generating videos with the desired attributes and motion patterns.
5/7/2024