ssProp: Energy-Efficient Training for Convolutional Neural Networks with Scheduled Sparse Back Propagation

0

Sign in to get full access
Overview
- The paper proposes a method called "ssProp" for energy-efficient training of convolutional neural networks.
- ssProp uses "scheduled sparse back propagation" to reduce the computational load during training.
- The approach aims to reduce the overall energy consumption of the training process.
Plain English Explanation
The paper introduces a new technique called "ssProp" that can make the training of convolutional neural networks more energy-efficient. Convolutional neural networks are a type of machine learning model that are particularly good at tasks like image recognition.
The key idea behind ssProp is to make the backpropagation algorithm, which is used to train the network, more sparse. Normally, backpropagation calculates gradients for all the parameters in the network during each training step. ssProp selectively calculates gradients for only a subset of the parameters, reducing the overall computational load.
This "scheduled sparse backpropagation" approach is designed to maintain the network's accuracy while using less energy to train it. The sparsity of the backpropagation is gradually increased over the course of training, starting out dense and becoming more sparse over time.
The goal is to develop neural networks that are not only accurate, but also energy-efficient, which is important for applications like mobile devices or embedded systems with limited power budgets.
Technical Explanation
The paper introduces a new training algorithm called "ssProp" (scheduled sparse backpropagation) for convolutional neural networks. The key idea is to selectively update only a subset of the network parameters during each training iteration, rather than updating all parameters as in standard backpropagation.
The sparsity of the parameter updates is gradually increased over the course of training, starting with a fully dense update and becoming increasingly sparse. This is implemented by multiplying the gradients with a sparsity mask, which is a binary tensor that determines which parameters get updated.
The sparsity mask is generated using a simple scheduling function that starts at 0% sparsity and increases to a target sparsity level over the course of training. This allows the network to maintain accuracy during the early stages of training when the model is still learning important features, while gradually reducing the computational cost as training progresses.
The authors evaluate ssProp on several standard computer vision benchmarks, including ImageNet and CIFAR-10. They show that ssProp can achieve similar or better accuracy compared to standard backpropagation, while reducing the total energy consumption of the training process by up to 50%.
Critical Analysis
The ssProp approach seems promising for reducing the energy consumption of training convolutional neural networks, which is an important consideration for many real-world applications. The gradual increase in sparsity is a clever way to maintain accuracy while becoming more computationally efficient over time.
However, the paper does not provide a deep analysis of the limitations or potential downsides of the method. For example, it's not clear how sensitive the approach is to the choice of sparsity scheduling function, or whether there are certain types of models or tasks where ssProp may not work as well.
Additionally, the paper focuses solely on the training phase and does not consider the implications for inference (using the trained model to make predictions). It's possible that the sparse connectivity patterns induced by ssProp could negatively impact inference performance or efficiency, which would be an important consideration.
Further research could explore the broader applicability and robustness of the ssProp approach, as well as its interactions with other neural network optimization techniques like pruning or quantization. Comparing ssProp to other energy-efficient training methods would also help contextualize its strengths and weaknesses.
Conclusion
The ssProp method proposed in this paper represents a promising step towards more energy-efficient training of convolutional neural networks. By selectively updating a subset of the model parameters during backpropagation, ssProp can achieve similar accuracy to standard training while significantly reducing the overall energy consumption.
This type of optimization is crucial for deploying deep learning models in resource-constrained environments like mobile devices or embedded systems. If the ssProp approach can be further refined and generalized, it could have a substantial impact on the real-world applicability of deep learning technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ssProp: Energy-Efficient Training for Convolutional Neural Networks with Scheduled Sparse Back Propagation
Lujia Zhong, Shuo Huang, Yonggang Shi
Recently, deep learning has made remarkable strides, especially with generative modeling, such as large language models and probabilistic diffusion models. However, training these models often involves significant computational resources, requiring billions of petaFLOPs. This high resource consumption results in substantial energy usage and a large carbon footprint, raising critical environmental concerns. Back-propagation (BP) is a major source of computational expense during training deep learning models. To advance research on energy-efficient training and allow for sparse learning on any machine and device, we propose a general, energy-efficient convolution module that can be seamlessly integrated into any deep learning architecture. Specifically, we introduce channel-wise sparsity with additional gradient selection schedulers during backward based on the assumption that BP is often dense and inefficient, which can lead to over-fitting and high computational consumption. Our experiments demonstrate that our approach reduces 40% computations while potentially improving model performance, validated on image classification and generation tasks. This reduction can lead to significant energy savings and a lower carbon footprint during the research and development phases of large-scale AI systems. Additionally, our method mitigates over-fitting in a manner distinct from Dropout, allowing it to be combined with Dropout to further enhance model performance and reduce computational resource usage. Extensive experiments validate that our method generalizes to a variety of datasets and tasks and is compatible with a wide range of deep learning architectures and modules. Code is publicly available at https://github.com/lujiazho/ssProp.
Read more8/23/2024

0
Advancing On-Device Neural Network Training with TinyPropv2: Dynamic, Sparse, and Efficient Backpropagation
Marcus Rub, Axel Sikora, Daniel Mueller-Gritschneder
This study introduces TinyPropv2, an innovative algorithm optimized for on-device learning in deep neural networks, specifically designed for low-power microcontroller units. TinyPropv2 refines sparse backpropagation by dynamically adjusting the level of sparsity, including the ability to selectively skip training steps. This feature significantly lowers computational effort without substantially compromising accuracy. Our comprehensive evaluation across diverse datasets CIFAR 10, CIFAR100, Flower, Food, Speech Command, MNIST, HAR, and DCASE2020 reveals that TinyPropv2 achieves near-parity with full training methods, with an average accuracy drop of only around 1 percent in most cases. For instance, against full training, TinyPropv2's accuracy drop is minimal, for example, only 0.82 percent on CIFAR 10 and 1.07 percent on CIFAR100. In terms of computational effort, TinyPropv2 shows a marked reduction, requiring as little as 10 percent of the computational effort needed for full training in some scenarios, and consistently outperforms other sparse training methodologies. These findings underscore TinyPropv2's capacity to efficiently manage computational resources while maintaining high accuracy, positioning it as an advantageous solution for advanced embedded device applications in the IoT ecosystem.
Read more9/12/2024

0
Scaling SNNs Trained Using Equilibrium Propagation to Convolutional Architectures
Jiaqi Lin, Malyaban Bal, Abhronil Sengupta
Equilibrium Propagation (EP) is a biologically plausible local learning algorithm initially developed for convergent recurrent neural networks (RNNs), where weight updates rely solely on the connecting neuron states across two phases. The gradient calculations in EP have been shown to approximate the gradients computed by Backpropagation Through Time (BPTT) when an infinitesimally small nudge factor is used. This property makes EP a powerful candidate for training Spiking Neural Networks (SNNs), which are commonly trained by BPTT. However, in the spiking domain, previous studies on EP have been limited to architectures involving few linear layers. In this work, for the first time we provide a formulation for training convolutional spiking convergent RNNs using EP, bridging the gap between spiking and non-spiking convergent RNNs. We demonstrate that for spiking convergent RNNs, there is a mismatch in the maximum pooling and its inverse operation, leading to inaccurate gradient estimation in EP. Substituting this with average pooling resolves this issue and enables accurate gradient estimation for spiking convergent RNNs. We also highlight the memory efficiency of EP compared to BPTT. In the regime of SNNs trained by EP, our experimental results indicate state-of-the-art performance on the MNIST and FashionMNIST datasets, with test errors of 0.97% and 8.89%, respectively. These results are comparable to those of convergent RNNs and SNNs trained by BPTT. These findings underscore EP as an optimal choice for on-chip training and a biologically-plausible method for computing error gradients.
Read more7/4/2024
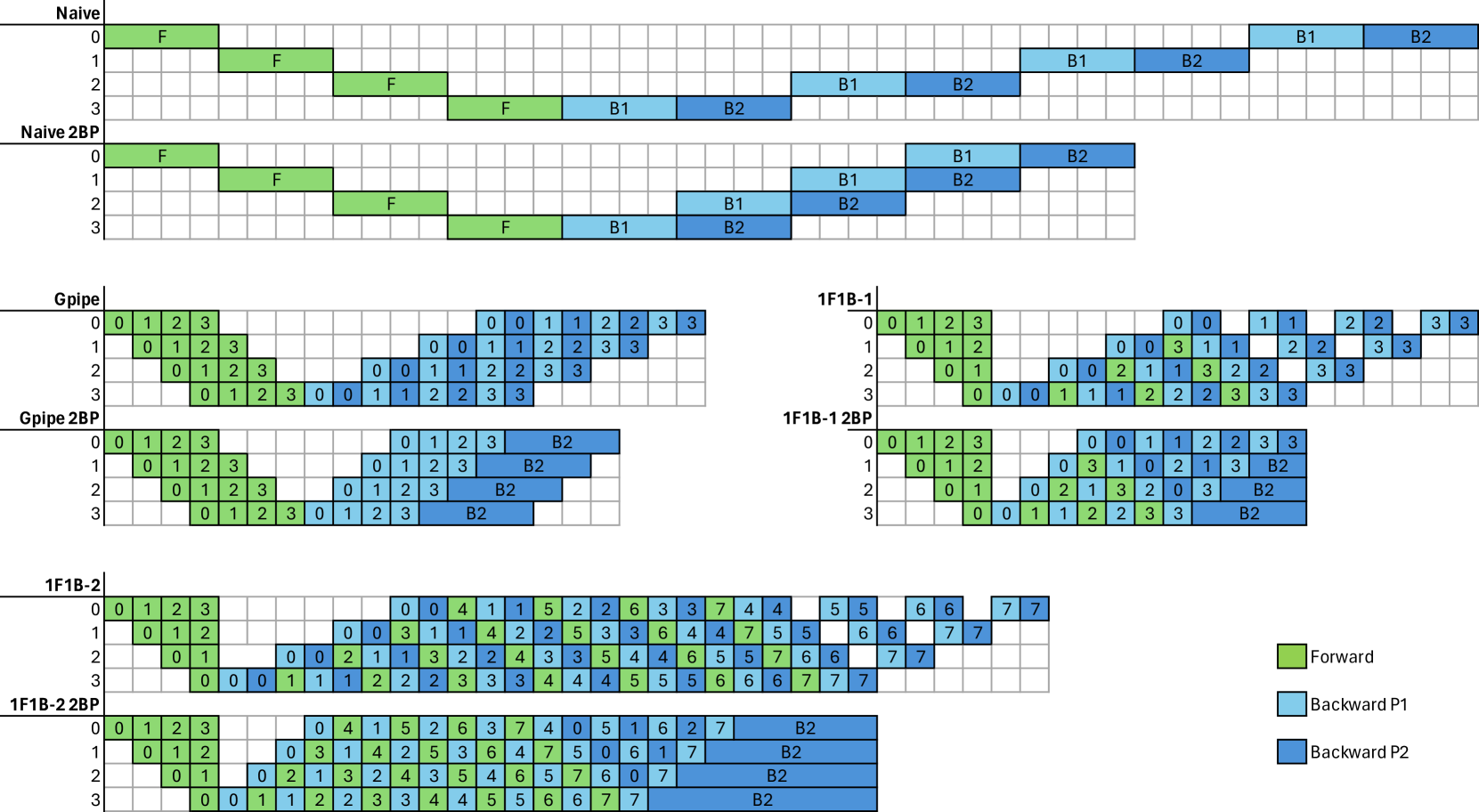
0
2BP: 2-Stage Backpropagation
Christopher Rae, Joseph K. L. Lee, James Richings
As Deep Neural Networks (DNNs) grow in size and complexity, they often exceed the memory capacity of a single accelerator, necessitating the sharding of model parameters across multiple accelerators. Pipeline parallelism is a commonly used sharding strategy for training large DNNs. However, current implementations of pipeline parallelism are being unintentionally bottlenecked by the automatic differentiation tools provided by ML frameworks. This paper introduces 2-stage backpropagation (2BP). By splitting the backward propagation step into two separate stages, we can reduce idle compute time. We tested 2BP on various model architectures and pipelining schedules, achieving increases in throughput in all cases. Using 2BP, we were able to achieve a 1.70x increase in throughput compared to traditional methods when training a LLaMa-like transformer with 7 billion parameters across 4 GPUs.
Read more5/29/2024