STAB: Speech Tokenizer Assessment Benchmark

0

Sign in to get full access
Overview
- The paper presents STAB, a benchmark for evaluating speech tokenizers.
- Speech tokenization is the process of converting raw audio into discrete tokens for downstream tasks like speech recognition.
- STAB assesses the performance of speech tokenizers across a variety of datasets, languages, and metrics.
Plain English Explanation
The paper introduces a new benchmark called STAB that is designed to evaluate how well different speech tokenization systems perform. Speech tokenization is the process of taking raw audio recordings and converting them into a sequence of discrete tokens that can be used for tasks like speech recognition.
The researchers created STAB to provide a standardized way to compare the performance of different speech tokenization systems. It includes a variety of datasets in different languages, as well as multiple metrics for assessing things like the quality and consistency of the generated tokens. By having a common benchmark, researchers can more easily evaluate the strengths and weaknesses of their speech tokenization approaches and see how they stack up against other methods.
Technical Explanation
The key components of STAB are:
- Datasets: The benchmark includes a diverse set of speech datasets spanning multiple languages and domains, allowing for comprehensive evaluation.
- Metrics: STAB defines several metrics to assess different aspects of speech tokenizer performance, such as token consistency, quality, and alignment with human judgment.
- Evaluation Protocol: The paper outlines a standardized evaluation procedure to ensure fair and comparable results across different speech tokenization models.
The researchers demonstrate the utility of STAB by evaluating several popular speech tokenization approaches, including HuBERT, WAV2VEC 2.0, and UniSpeech. The results reveal insights about the relative strengths and weaknesses of these models, providing guidance for future research and development.
Critical Analysis
The STAB benchmark represents a valuable contribution to the field of speech tokenization research. By providing a standardized evaluation framework, it enables more rigorous and meaningful comparisons between different approaches. This can help accelerate progress in the field and guide researchers towards more effective speech tokenization solutions.
However, the paper acknowledges several limitations of STAB, such as the potential for dataset bias and the need for ongoing expansion and refinement as the field evolves. Additionally, the evaluation metrics used in STAB may not capture all relevant aspects of speech tokenizer performance, and there may be other important factors to consider, such as model efficiency or real-world deployment considerations.
Further research could explore ways to address these limitations, such as incorporating more diverse datasets, developing additional evaluation metrics, and investigating the practical implications of speech tokenizer performance in real-world applications.
Conclusion
The STAB benchmark provides a much-needed standardized framework for evaluating the performance of speech tokenization systems. By establishing a common set of datasets, metrics, and evaluation protocols, STAB enables more rigorous and meaningful comparisons between different approaches, helping to drive progress in this important area of speech and language processing. While the benchmark has some limitations, it represents a significant step forward in the field and will likely prove invaluable for future research and development efforts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
STAB: Speech Tokenizer Assessment Benchmark
Shikhar Vashishth, Harman Singh, Shikhar Bharadwaj, Sriram Ganapathy, Chulayuth Asawaroengchai, Kartik Audhkhasi, Andrew Rosenberg, Ankur Bapna, Bhuvana Ramabhadran
Representing speech as discrete tokens provides a framework for transforming speech into a format that closely resembles text, thus enabling the use of speech as an input to the widely successful large language models (LLMs). Currently, while several speech tokenizers have been proposed, there is ambiguity regarding the properties that are desired from a tokenizer for specific downstream tasks and its overall generalizability. Evaluating the performance of tokenizers across different downstream tasks is a computationally intensive effort that poses challenges for scalability. To circumvent this requirement, we present STAB (Speech Tokenizer Assessment Benchmark), a systematic evaluation framework designed to assess speech tokenizers comprehensively and shed light on their inherent characteristics. This framework provides a deeper understanding of the underlying mechanisms of speech tokenization, thereby offering a valuable resource for expediting the advancement of future tokenizer models and enabling comparative analysis using a standardized benchmark. We evaluate the STAB metrics and correlate this with downstream task performance across a range of speech tasks and tokenizer choices.
Read more9/5/2024

0
DASB -- Discrete Audio and Speech Benchmark
Pooneh Mousavi, Luca Della Libera, Jarod Duret, Artem Ploujnikov, Cem Subakan, Mirco Ravanelli
Discrete audio tokens have recently gained considerable attention for their potential to connect audio and language processing, enabling the creation of modern multimodal large language models. Ideal audio tokens must effectively preserve phonetic and semantic content along with paralinguistic information, speaker identity, and other details. While several types of audio tokens have been recently proposed, identifying the optimal tokenizer for various tasks is challenging due to the inconsistent evaluation settings in existing studies. To address this gap, we release the Discrete Audio and Speech Benchmark (DASB), a comprehensive leaderboard for benchmarking discrete audio tokens across a wide range of discriminative tasks, including speech recognition, speaker identification and verification, emotion recognition, keyword spotting, and intent classification, as well as generative tasks such as speech enhancement, separation, and text-to-speech. Our results show that, on average, semantic tokens outperform compression tokens across most discriminative and generative tasks. However, the performance gap between semantic tokens and standard continuous representations remains substantial, highlighting the need for further research in this field.
Read more6/24/2024

0
LAST: Language Model Aware Speech Tokenization
Arnon Turetzky, Yossi Adi
Speech tokenization serves as the foundation of speech language model (LM), enabling them to perform various tasks such as spoken language modeling, text-to-speech, speech-to-text, etc. Most speech tokenizers are trained independently of the LM training process, relying on separate acoustic models and quantization methods. Following such an approach may create a mismatch between the tokenization process and its usage afterward. In this study, we propose a novel approach to training a speech tokenizer by leveraging objectives from pre-trained textual LMs. We advocate for the integration of this objective into the process of learning discrete speech representations. Our aim is to transform features from a pre-trained speech model into a new feature space that enables better clustering for speech LMs. We empirically investigate the impact of various model design choices, including speech vocabulary size and text LM size. Our results demonstrate the proposed tokenization method outperforms the evaluated baselines considering both spoken language modeling and speech-to-text. More importantly, unlike prior work, the proposed method allows the utilization of a single pre-trained LM for processing both speech and text inputs, setting it apart from conventional tokenization approaches.
Read more9/11/2024
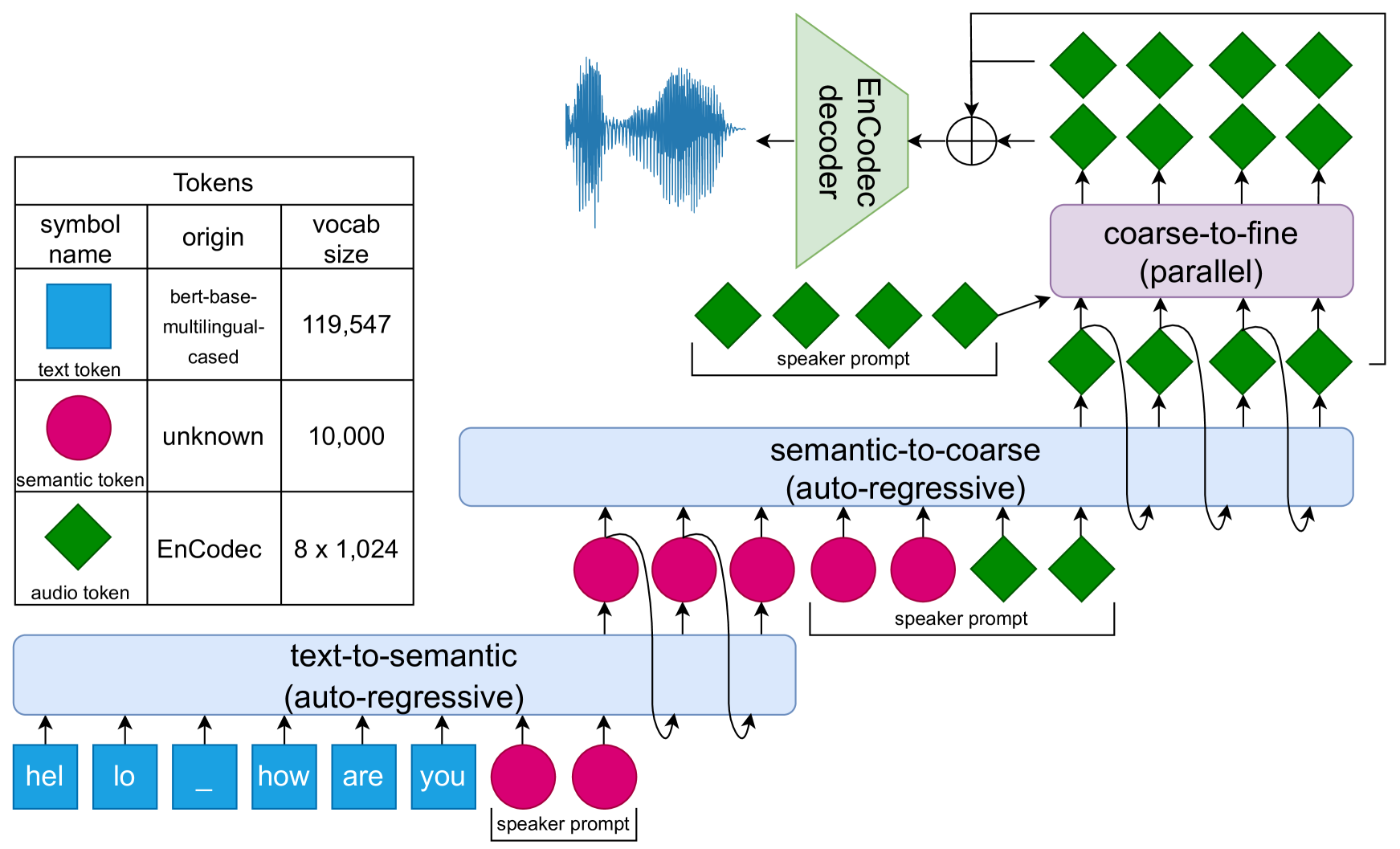
0
Evaluating Text-to-Speech Synthesis from a Large Discrete Token-based Speech Language Model
Siyang Wang, 'Eva Sz'ekely
Recent advances in generative language modeling applied to discrete speech tokens presented a new avenue for text-to-speech (TTS) synthesis. These speech language models (SLMs), similarly to their textual counterparts, are scalable, probabilistic, and context-aware. While they can produce diverse and natural outputs, they sometimes face issues such as unintelligibility and the inclusion of non-speech noises or hallucination. As the adoption of this innovative paradigm in speech synthesis increases, there is a clear need for an in-depth evaluation of its capabilities and limitations. In this paper, we evaluate TTS from a discrete token-based SLM, through both automatic metrics and listening tests. We examine five key dimensions: speaking style, intelligibility, speaker consistency, prosodic variation, spontaneous behaviour. Our results highlight the model's strength in generating varied prosody and spontaneous outputs. It is also rated higher in naturalness and context appropriateness in listening tests compared to a conventional TTS. However, the model's performance in intelligibility and speaker consistency lags behind traditional TTS. Additionally, we show that increasing the scale of SLMs offers a modest boost in robustness. Our findings aim to serve as a benchmark for future advancements in generative SLMs for speech synthesis.
Read more5/17/2024