Evaluating Text-to-Speech Synthesis from a Large Discrete Token-based Speech Language Model
2405.09768
0
0
Abstract
Recent advances in generative language modeling applied to discrete speech tokens presented a new avenue for text-to-speech (TTS) synthesis. These speech language models (SLMs), similarly to their textual counterparts, are scalable, probabilistic, and context-aware. While they can produce diverse and natural outputs, they sometimes face issues such as unintelligibility and the inclusion of non-speech noises or hallucination. As the adoption of this innovative paradigm in speech synthesis increases, there is a clear need for an in-depth evaluation of its capabilities and limitations. In this paper, we evaluate TTS from a discrete token-based SLM, through both automatic metrics and listening tests. We examine five key dimensions: speaking style, intelligibility, speaker consistency, prosodic variation, spontaneous behaviour. Our results highlight the model's strength in generating varied prosody and spontaneous outputs. It is also rated higher in naturalness and context appropriateness in listening tests compared to a conventional TTS. However, the model's performance in intelligibility and speaker consistency lags behind traditional TTS. Additionally, we show that increasing the scale of SLMs offers a modest boost in robustness. Our findings aim to serve as a benchmark for future advancements in generative SLMs for speech synthesis.
Create account to get full access
Overview
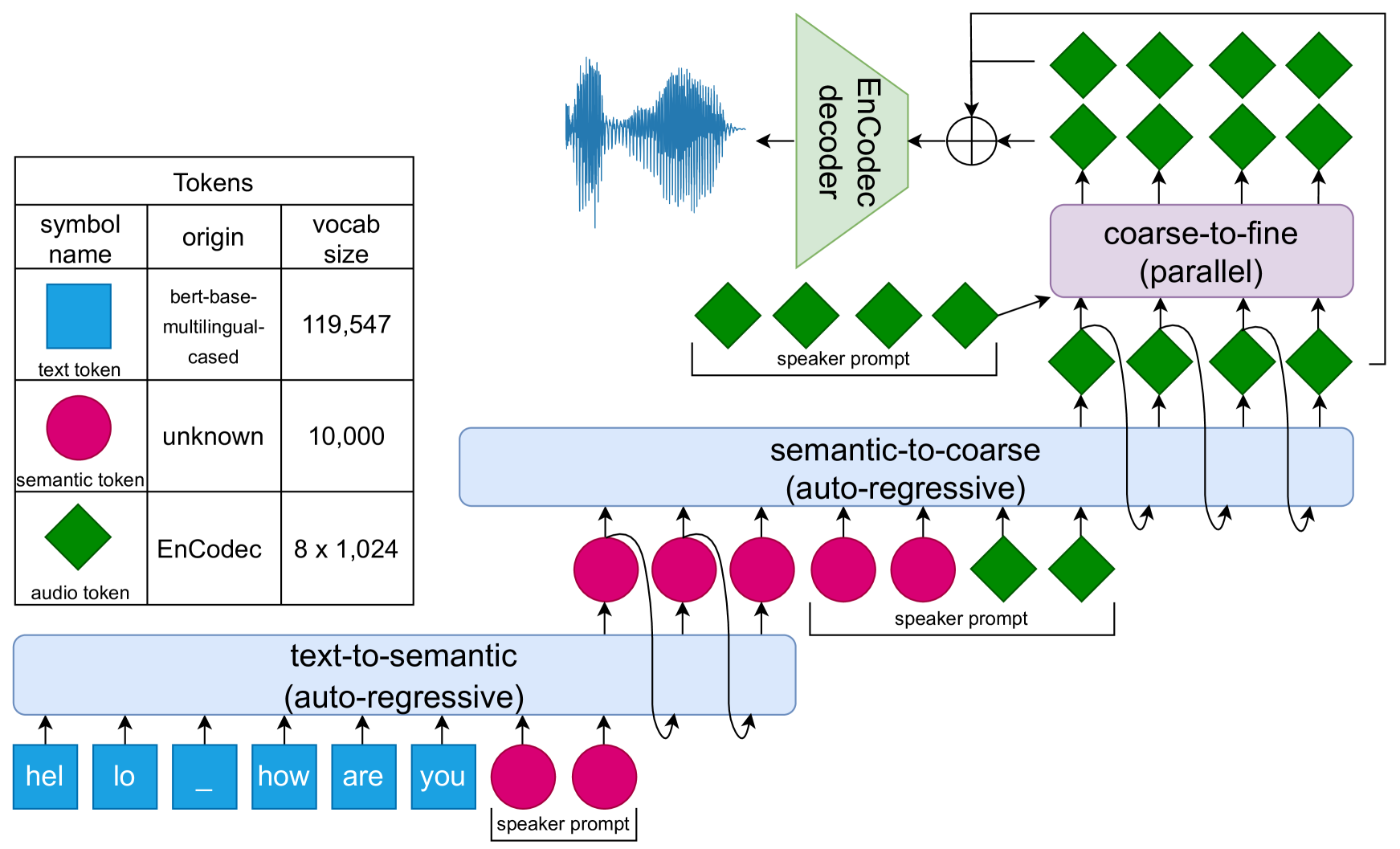
- Evaluates the text-to-speech synthesis capabilities of a large discrete token-based speech language model called Bark
- Compares Bark's performance to other state-of-the-art text-to-speech systems across various metrics
- Explores the scaling properties of Bark and how its performance changes as the model size is increased
Plain English Explanation
This research paper examines a new text-to-speech system called Bark, which is based on a large "speech language model" - a powerful AI model that can understand and generate human speech. The researchers wanted to see how well Bark could synthesize (or create) natural-sounding speech from text, and how it compared to other leading text-to-speech technologies.
They tested Bark on a variety of tasks, measuring things like the intelligibility, naturalness, and expressiveness of the generated speech. The results showed that Bark performed very well, often matching or exceeding the quality of other state-of-the-art text-to-speech systems.
Interestingly, the researchers also found that as they made Bark's model bigger and more complex, its speech synthesis capabilities continued to improve. This suggests that these large, powerful speech language models can be scaled up to achieve even better text-to-speech performance in the future.
Overall, this research demonstrates the impressive potential of Bark and similar speech language models for advancing text-to-speech technology, which could have important applications in areas like digital assistants, audiobook narration, and accessibility tools.
Technical Explanation
The researchers evaluated the text-to-speech synthesis capabilities of a large discrete token-based speech language model called Bark. Bark was trained on a massive dataset of speech and text data, allowing it to learn the complex relationships between written language and spoken audio.
To assess Bark's performance, the researchers conducted a series of experiments comparing it to other state-of-the-art text-to-speech systems. They measured various metrics, including:
- Intelligibility: How well the generated speech could be understood by human listeners
- Naturalness: How closely the synthesized speech matched the quality of natural human speech
- Expressiveness: How effectively the system could convey emotion, emphasis, and speaking style
The results showed that Bark performed very competitively, often matching or exceeding the quality of other leading text-to-speech models across these different evaluation criteria.
Additionally, the researchers explored the scaling properties of the Bark model. They found that as they increased the size and complexity of the model, its text-to-speech synthesis capabilities continued to improve. This suggests that these large, powerful speech language models can be further scaled up to achieve even better performance in the future.
Critical Analysis
The researchers acknowledged several caveats and limitations in their work. For example, they noted that the evaluation was primarily focused on English speech, and it's unclear how well Bark would perform on other languages or dialects. Additionally, the study did not explore the model's ability to handle more challenging or expressive speech, such as highly emotional or storytelling-style text-to-speech.
Further research would be needed to fully understand the capabilities and limitations of Bark and similar speech language models for text-to-speech synthesis. Factors like the model's robustness to noise, its ability to handle speaker adaptation, and its suitability for real-world applications could all be important areas for future investigation.
Conclusion
This research paper provides a promising evaluation of the text-to-speech synthesis capabilities of the Bark speech language model. The results suggest that large, powerful models like Bark have the potential to significantly advance the state-of-the-art in text-to-speech technology, with applications in digital assistants, audiobook narration, accessibility tools, and beyond. As these models continue to scale and improve, we can expect to see even more impressive and natural-sounding speech synthesis in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

High Fidelity Text-to-Speech Via Discrete Tokens Using Token Transducer and Group Masked Language Model
Joun Yeop Lee, Myeonghun Jeong, Minchan Kim, Ji-Hyun Lee, Hoon-Young Cho, Nam Soo Kim
0
0
We propose a novel two-stage text-to-speech (TTS) framework with two types of discrete tokens, i.e., semantic and acoustic tokens, for high-fidelity speech synthesis. It features two core components: the Interpreting module, which processes text and a speech prompt into semantic tokens focusing on linguistic contents and alignment, and the Speaking module, which captures the timbre of the target voice to generate acoustic tokens from semantic tokens, enriching speech reconstruction. The Interpreting stage employs a transducer for its robustness in aligning text to speech. In contrast, the Speaking stage utilizes a Conformer-based architecture integrated with a Grouped Masked Language Model (G-MLM) to boost computational efficiency. Our experiments verify that this innovative structure surpasses the conventional models in the zero-shot scenario in terms of speech quality and speaker similarity.
6/26/2024

TokSing: Singing Voice Synthesis based on Discrete Tokens
Yuning Wu, Chunlei zhang, Jiatong Shi, Yuxun Tang, Shan Yang, Qin Jin
0
0
Recent advancements in speech synthesis witness significant benefits by leveraging discrete tokens extracted from self-supervised learning (SSL) models. Discrete tokens offer higher storage efficiency and greater operability in intermediate representations compared to traditional continuous Mel spectrograms. However, when it comes to singing voice synthesis(SVS), achieving higher levels of melody expression poses a great challenge for utilizing discrete tokens. In this paper, we introduce TokSing, a discrete-based SVS system equipped with a token formulator that offers flexible token blendings. We observe a melody degradation during discretization, prompting us to integrate a melody signal with the discrete token and incorporate a specially-designed melody enhancement strategy in the musical encoder. Extensive experiments demonstrate that our TokSing achieves better performance against the Mel spectrogram baselines while offering advantages in intermediate representation space cost and convergence speed.
6/21/2024
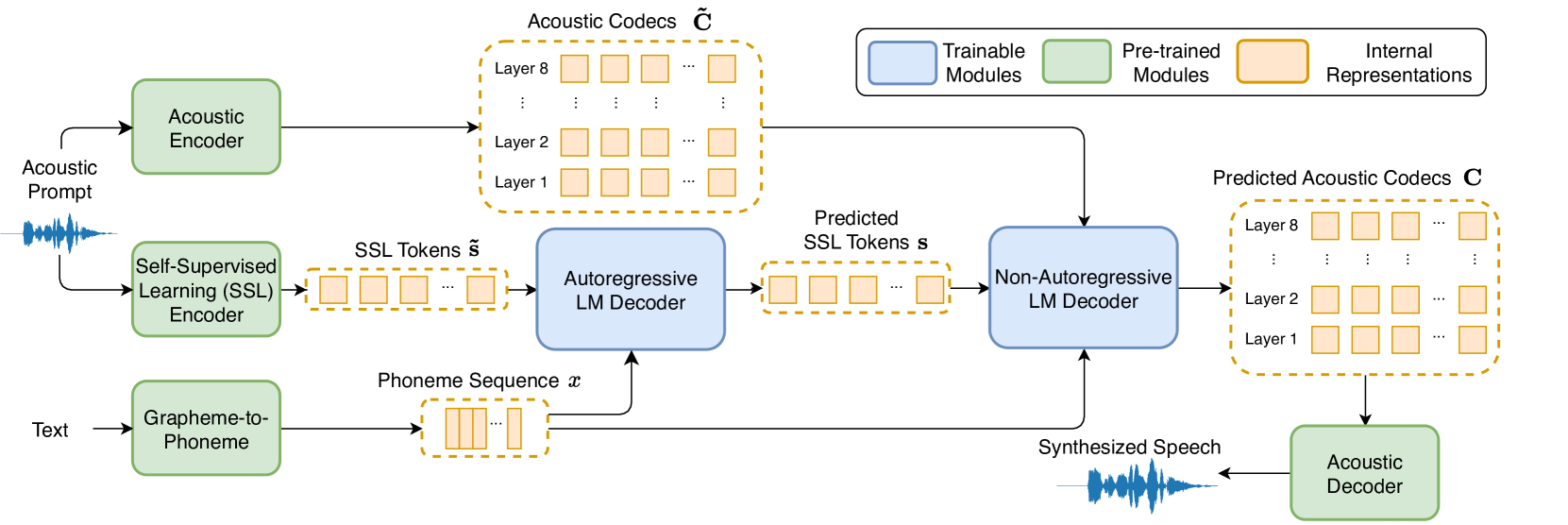
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Kun Zhou, Shengkui Zhao, Yukun Ma, Chong Zhang, Hao Wang, Dianwen Ng, Chongjia Ni, Nguyen Trung Hieu, Jia Qi Yip, Bin Ma
0
0
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
6/13/2024

DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer
Keon Lee, Dong Won Kim, Jaehyeon Kim, Jaewoong Cho
0
0
Large-scale diffusion models have shown outstanding generative abilities across multiple modalities including images, videos, and audio. However, text-to-speech (TTS) systems typically involve domain-specific modeling factors (e.g., phonemes and phoneme-level durations) to ensure precise temporal alignments between text and speech, which hinders the efficiency and scalability of diffusion models for TTS. In this work, we present an efficient and scalable Diffusion Transformer (DiT) that utilizes off-the-shelf pre-trained text and speech encoders. Our approach addresses the challenge of text-speech alignment via cross-attention mechanisms with the prediction of the total length of speech representations. To achieve this, we enhance the DiT architecture to suit TTS and improve the alignment by incorporating semantic guidance into the latent space of speech. We scale the training dataset and the model size to 82K hours and 790M parameters, respectively. Our extensive experiments demonstrate that the large-scale diffusion model for TTS without domain-specific modeling not only simplifies the training pipeline but also yields superior or comparable zero-shot performance to state-of-the-art TTS models in terms of naturalness, intelligibility, and speaker similarity. Our speech samples are available at https://ditto-tts.github.io.
6/18/2024