Stability Evaluation via Distributional Perturbation Analysis

0
Sign in to get full access
Overview
This paper proposes a new framework for evaluating the stability and robustness of machine learning models by analyzing their sensitivity to distributional perturbations. The key idea is to quantify how much a model's performance can degrade when the input distribution is slightly shifted or perturbed, which provides insights into the model's stability and reliability.
Plain English Explanation
Machine learning models are often trained and evaluated on specific datasets, but in the real world, the data they encounter may be slightly different. This paper introduces a way to test how well a model can handle these small changes in the data distribution.
The researchers developed a method to systematically perturb or alter the input data in controlled ways, and then measure how much the model's performance degrades as a result. This allows them to quantify the model's stability - how much it can withstand small shifts in the data without its performance falling apart.
By understanding a model's sensitivity to distributional shifts, developers can get a better sense of its real-world robustness and reliability. This is an important consideration, as models that are brittle to data changes may not perform well outside of the specific training conditions.
The paper demonstrates the application of this framework to several machine learning tasks, showing how it can provide valuable insights beyond traditional model evaluation metrics. This type of stability analysis can help ensure that AI systems are more reliable and trustworthy when deployed in dynamic, real-world environments.
Technical Explanation
The paper introduces a Model Evaluation Framework that centers around Distributional Perturbation Analysis (DPA). The key components are:
-
Distributional Perturbation: The researchers define a set of perturbation operators that can be applied to the input data to create small, controlled shifts in the data distribution. This includes techniques like adding pixel-level noise, altering image rotations, or adjusting feature statistics.
-
Stability Evaluation: The framework evaluates model performance not just on the original test set, but also on perturbed test sets created using the distributional perturbation operators. This allows quantifying the model's sensitivity to these distributional shifts.
-
Robustness Optimization: Building on this stability evaluation, the researchers explore techniques like distributionally robust optimization and adversarial training to train more robust models that can better withstand distributional perturbations.
The paper demonstrates the applicability of this framework across various machine learning tasks, including image classification, language modeling, and reinforcement learning. The results show that models can exhibit significant performance degradation even with small distribution shifts, highlighting the importance of stability analysis beyond just standard accuracy metrics.
Critical Analysis
The paper makes a compelling case for the importance of distributional perturbation analysis in evaluating machine learning models. By going beyond standard test set performance, this framework provides a more comprehensive assessment of model stability and robustness.
That said, the paper acknowledges that the proposed perturbation operators may not capture all possible real-world distribution shifts that a model might encounter. There could be other types of distributional changes that are not accounted for in the current framework.
Additionally, the paper focuses primarily on evaluating model stability, but does not provide detailed guidance on how to actually improve a model's robustness through techniques like distributionally robust optimization. Further research may be needed to better understand the practical implications and tradeoffs of these approaches.
Overall, the paper makes a valuable contribution by highlighting the importance of stability analysis and providing a principled framework for quantifying it. As machine learning systems become more widely deployed, ensuring their reliability in the face of distributional shifts will be crucial for building trustworthy and dependable AI applications.
Conclusion
This paper introduces a novel Model Evaluation Framework centered around Distributional Perturbation Analysis (DPA). By systematically perturbing input data distributions and measuring the resulting impact on model performance, the framework provides a more comprehensive assessment of a model's stability and robustness.
The key insights from this research are:
- Traditional model evaluation metrics may not capture a model's sensitivity to distributional shifts in real-world data
- Quantifying a model's stability through DPA can reveal important limitations and vulnerabilities
- Techniques like distributionally robust optimization and adversarial training can help improve a model's ability to withstand distributional perturbations
As machine learning becomes increasingly ubiquitous, ensuring the reliability and trustworthiness of AI systems will be crucial. The DPA framework proposed in this paper represents an important step towards more rigorous and comprehensive model evaluation, which can ultimately lead to the development of more robust and dependable AI applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
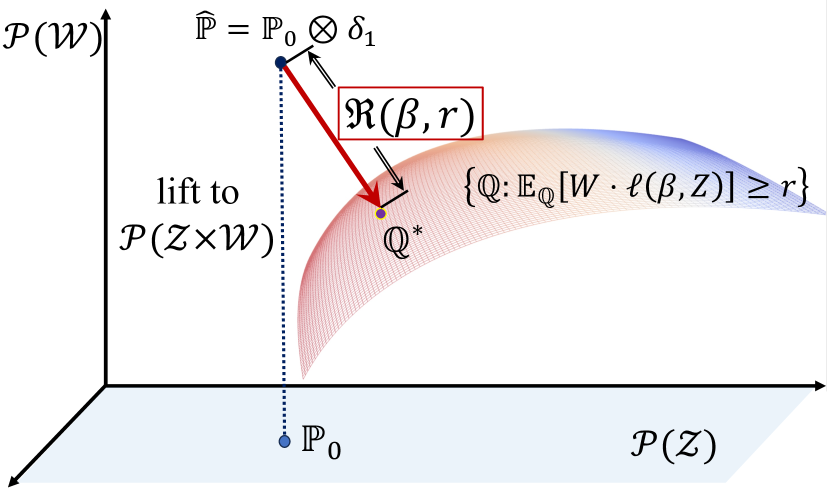
Stability Evaluation via Distributional Perturbation Analysis
Jose Blanchet, Peng Cui, Jiajin Li, Jiashuo Liu
The performance of learning models often deteriorates when deployed in out-of-sample environments. To ensure reliable deployment, we propose a stability evaluation criterion based on distributional perturbations. Conceptually, our stability evaluation criterion is defined as the minimal perturbation required on our observed dataset to induce a prescribed deterioration in risk evaluation. In this paper, we utilize the optimal transport (OT) discrepancy with moment constraints on the textit{(sample, density)} space to quantify this perturbation. Therefore, our stability evaluation criterion can address both emph{data corruptions} and emph{sub-population shifts} -- the two most common types of distribution shifts in real-world scenarios. To further realize practical benefits, we present a series of tractable convex formulations and computational methods tailored to different classes of loss functions. The key technical tool to achieve this is the strong duality theorem provided in this paper. Empirically, we validate the practical utility of our stability evaluation criterion across a host of real-world applications. These empirical studies showcase the criterion's ability not only to compare the stability of different learning models and features but also to provide valuable guidelines and strategies to further improve models.
Read more5/7/2024
0
Quantifying Distribution Shifts and Uncertainties for Enhanced Model Robustness in Machine Learning Applications
Vegard Flovik
Distribution shifts, where statistical properties differ between training and test datasets, present a significant challenge in real-world machine learning applications where they directly impact model generalization and robustness. In this study, we explore model adaptation and generalization by utilizing synthetic data to systematically address distributional disparities. Our investigation aims to identify the prerequisites for successful model adaptation across diverse data distributions, while quantifying the associated uncertainties. Specifically, we generate synthetic data using the Van der Waals equation for gases and employ quantitative measures such as Kullback-Leibler divergence, Jensen-Shannon distance, and Mahalanobis distance to assess data similarity. These metrics en able us to evaluate both model accuracy and quantify the associated uncertainty in predictions arising from data distribution shifts. Our findings suggest that utilizing statistical measures, such as the Mahalanobis distance, to determine whether model predictions fall within the low-error interpolation regime or the high-error extrapolation regime provides a complementary method for assessing distribution shift and model uncertainty. These insights hold significant value for enhancing model robustness and generalization, essential for the successful deployment of machine learning applications in real-world scenarios.
Read more5/6/2024
⛏️
0
Robust Validation: Confident Predictions Even When Distributions Shift
Maxime Cauchois, Suyash Gupta, Alnur Ali, John C. Duchi
While the traditional viewpoint in machine learning and statistics assumes training and testing samples come from the same population, practice belies this fiction. One strategy -- coming from robust statistics and optimization -- is thus to build a model robust to distributional perturbations. In this paper, we take a different approach to describe procedures for robust predictive inference, where a model provides uncertainty estimates on its predictions rather than point predictions. We present a method that produces prediction sets (almost exactly) giving the right coverage level for any test distribution in an $f$-divergence ball around the training population. The method, based on conformal inference, achieves (nearly) valid coverage in finite samples, under only the condition that the training data be exchangeable. An essential component of our methodology is to estimate the amount of expected future data shift and build robustness to it; we develop estimators and prove their consistency for protection and validity of uncertainty estimates under shifts. By experimenting on several large-scale benchmark datasets, including Recht et al.'s CIFAR-v4 and ImageNet-V2 datasets, we provide complementary empirical results that highlight the importance of robust predictive validity.
Read more7/8/2024
🛠️
0
Differential Privacy via Distributionally Robust Optimization
Aras Selvi, Huikang Liu, Wolfram Wiesemann
In recent years, differential privacy has emerged as the de facto standard for sharing statistics of datasets while limiting the disclosure of private information about the involved individuals. This is achieved by randomly perturbing the statistics to be published, which in turn leads to a privacy-accuracy trade-off: larger perturbations provide stronger privacy guarantees, but they result in less accurate statistics that offer lower utility to the recipients. Of particular interest are therefore optimal mechanisms that provide the highest accuracy for a pre-selected level of privacy. To date, work in this area has focused on specifying families of perturbations a priori and subsequently proving their asymptotic and/or best-in-class optimality. In this paper, we develop a class of mechanisms that enjoy non-asymptotic and unconditional optimality guarantees. To this end, we formulate the mechanism design problem as an infinite-dimensional distributionally robust optimization problem. We show that the problem affords a strong dual, and we exploit this duality to develop converging hierarchies of finite-dimensional upper and lower bounding problems. Our upper (primal) bounds correspond to implementable perturbations whose suboptimality can be bounded by our lower (dual) bounds. Both bounding problems can be solved within seconds via cutting plane techniques that exploit the inherent problem structure. Our numerical experiments demonstrate that our perturbations can outperform the previously best results from the literature on artificial as well as standard benchmark problems.
Read more5/24/2024