Stable Diffusion Segmentation for Biomedical Images with Single-step Reverse Process
2406.18361
0
0

Abstract
Diffusion models have demonstrated their effectiveness across various generative tasks. However, when applied to medical image segmentation, these models encounter several challenges, including significant resource and time requirements. They also necessitate a multi-step reverse process and multiple samples to produce reliable predictions. To address these challenges, we introduce the first latent diffusion segmentation model, named SDSeg, built upon stable diffusion (SD). SDSeg incorporates a straightforward latent estimation strategy to facilitate a single-step reverse process and utilizes latent fusion concatenation to remove the necessity for multiple samples. Extensive experiments indicate that SDSeg surpasses existing state-of-the-art methods on five benchmark datasets featuring diverse imaging modalities. Remarkably, SDSeg is capable of generating stable predictions with a solitary reverse step and sample, epitomizing the model's stability as implied by its name. The code is available at https://github.com/lin-tianyu/Stable-Diffusion-Seg
Create account to get full access
Overview
- This research paper presents a novel approach for biomedical image segmentation using a single-step reverse process with a latent diffusion model based on Stable Diffusion.
- The proposed method aims to improve the efficiency and accuracy of segmenting biomedical images, such as skin lesions, compared to existing approaches.
- The research leverages the capabilities of the Stable Diffusion model to generate high-quality segmentation masks from input images in a single-step reverse process.
Plain English Explanation
The paper introduces a new way to segment, or divide up, biomedical images like those of skin lesions. Segmentation is an important task in medical imaging, as it helps doctors and researchers identify and analyze different structures or regions within an image.
The researchers used a machine learning model called Stable Diffusion as the foundation for their approach. Stable Diffusion is a powerful image generation model that can create realistic-looking images from text descriptions.
Instead of using Stable Diffusion for image generation, the researchers used it in reverse - to generate segmentation masks (outlines) of the different structures in biomedical images. This single-step reverse process is more efficient than traditional segmentation methods, which often require multiple steps.
The key insight is that the latent space (the internal representation) learned by Stable Diffusion contains rich information about the structure of images. By harnessing this latent space, the researchers were able to generate accurate segmentation masks directly from input images in a single step.
This new approach has the potential to improve the efficiency and accuracy of biomedical image segmentation, which is crucial for tasks like analyzing skin lesions or generating anatomically-controlled medical images. It could also be extended to other types of 3D medical imaging data and segmentation tasks.
Technical Explanation
The researchers propose a novel single-step reverse process for biomedical image segmentation using a latent diffusion model based on the Stable Diffusion architecture.
The key components of their approach are:
-
Latent Representation: The researchers leverage the rich latent space learned by the Stable Diffusion model, which captures important structural information about the input images.
-
Single-step Reverse Process: Instead of the traditional multi-step segmentation process, the proposed method generates segmentation masks directly from the input image in a single step by reversing the Stable Diffusion generation process.
-
Biomedical Image Segmentation: The researchers demonstrate the effectiveness of their approach on the task of segmenting skin lesions, a common biomedical imaging application. However, the method could potentially be extended to a wider range of medical imaging data and segmentation tasks.
The researchers conducted experiments on several biomedical image segmentation datasets and compared their single-step reverse process approach to traditional segmentation methods. The results showed that their method outperformed the baselines in terms of segmentation accuracy and efficiency.
Critical Analysis
The paper presents a promising approach for biomedical image segmentation, but there are a few potential limitations and areas for further research:
-
Generalization to Other Biomedical Domains: While the researchers demonstrated the effectiveness of their method on skin lesion segmentation, it's unclear how well it would generalize to other types of biomedical images, such as 3D medical scans or images of different anatomical structures. Further testing on a broader range of biomedical datasets would be valuable.
-
Interpretability and Explainability: The paper does not provide much insight into the internal workings of the latent diffusion model and how it generates the segmentation masks. Improving the interpretability and explainability of the model could lead to better understanding and potentially further improvements.
-
Robustness and Reliability: The researchers did not extensively explore the robustness of their approach to common challenges in biomedical imaging, such as variations in image quality, noise, or artifacts. Evaluating the model's reliability and performance under these conditions would be an important next step.
-
Computational Efficiency: While the single-step reverse process is claimed to be more efficient than traditional segmentation methods, the paper does not provide a detailed analysis of the computational cost and resource requirements of the proposed approach. This information would be valuable for assessing its practical applicability, especially in resource-constrained clinical settings.
Overall, the research presents a novel and promising approach to biomedical image segmentation that leverages the capabilities of the Stable Diffusion model. With further investigation and validation, this work could contribute to advancements in the field of medical imaging analysis and automation.
Conclusion
This research paper introduces a novel single-step reverse process for biomedical image segmentation using a latent diffusion model based on Stable Diffusion. The proposed approach aims to improve the efficiency and accuracy of segmenting biomedical images, such as skin lesions, compared to existing methods.
The key innovation is the use of the rich latent space learned by the Stable Diffusion model to generate accurate segmentation masks directly from input images in a single step, rather than relying on a traditional multi-step segmentation process.
The researchers demonstrated the effectiveness of their method on skin lesion segmentation datasets, but noted the need for further investigation to assess its generalization to other types of biomedical images and its robustness to common challenges in medical imaging.
Overall, this research represents an exciting step forward in the application of latent diffusion models, such as Stable Diffusion, to the important task of biomedical image segmentation. With continued development and refinement, the proposed approach could have significant implications for a wide range of medical imaging applications and contribute to advancements in automated medical image analysis and unsupervised segmentation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
DiffSeg: A Segmentation Model for Skin Lesions Based on Diffusion Difference
Zhihao Shuai, Yinan Chen, Shunqiang Mao, Yihan Zho, Xiaohong Zhang
0
0
Weakly supervised medical image segmentation (MIS) using generative models is crucial for clinical diagnosis. However, the accuracy of the segmentation results is often limited by insufficient supervision and the complex nature of medical imaging. Existing models also only provide a single outcome, which does not allow for the measurement of uncertainty. In this paper, we introduce DiffSeg, a segmentation model for skin lesions based on diffusion difference which exploits diffusion model principles to ex-tract noise-based features from images with diverse semantic information. By discerning difference between these noise features, the model identifies diseased areas. Moreover, its multi-output capability mimics doctors' annotation behavior, facilitating the visualization of segmentation result consistency and ambiguity. Additionally, it quantifies output uncertainty using Generalized Energy Distance (GED), aiding interpretability and decision-making for physicians. Finally, the model integrates outputs through the Dense Conditional Random Field (DenseCRF) algorithm to refine the segmentation boundaries by considering inter-pixel correlations, which improves the accuracy and optimizes the segmentation results. We demonstrate the effectiveness of DiffSeg on the ISIC 2018 Challenge dataset, outperforming state-of-the-art U-Net-based methods.
4/26/2024
Anatomically-Controllable Medical Image Generation with Segmentation-Guided Diffusion Models
Nicholas Konz, Yuwen Chen, Haoyu Dong, Maciej A. Mazurowski
0
0
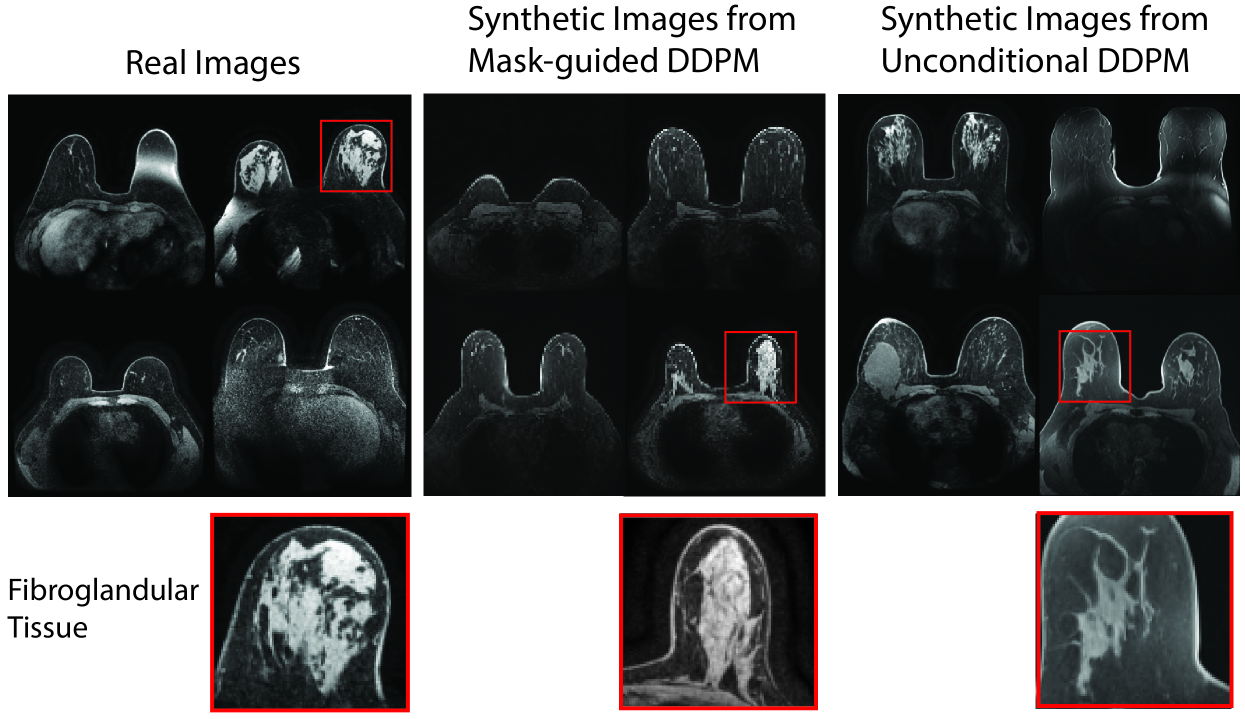
Diffusion models have enabled remarkably high-quality medical image generation, yet it is challenging to enforce anatomical constraints in generated images. To this end, we propose a diffusion model-based method that supports anatomically-controllable medical image generation, by following a multi-class anatomical segmentation mask at each sampling step. We additionally introduce a random mask ablation training algorithm to enable conditioning on a selected combination of anatomical constraints while allowing flexibility in other anatomical areas. We compare our method (SegGuidedDiff) to existing methods on breast MRI and abdominal/neck-to-pelvis CT datasets with a wide range of anatomical objects. Results show that our method reaches a new state-of-the-art in the faithfulness of generated images to input anatomical masks on both datasets, and is on par for general anatomical realism. Finally, our model also enjoys the extra benefit of being able to adjust the anatomical similarity of generated images to real images of choice through interpolation in its latent space. SegGuidedDiff has many applications, including cross-modality translation, and the generation of paired or counterfactual data. Our code is available at https://github.com/mazurowski-lab/segmentation-guided-diffusion.
6/21/2024
3D MRI Synthesis with Slice-Based Latent Diffusion Models: Improving Tumor Segmentation Tasks in Data-Scarce Regimes
Aghiles Kebaili, J'er^ome Lapuyade-Lahorgue, Pierre Vera, Su Ruan
0
0
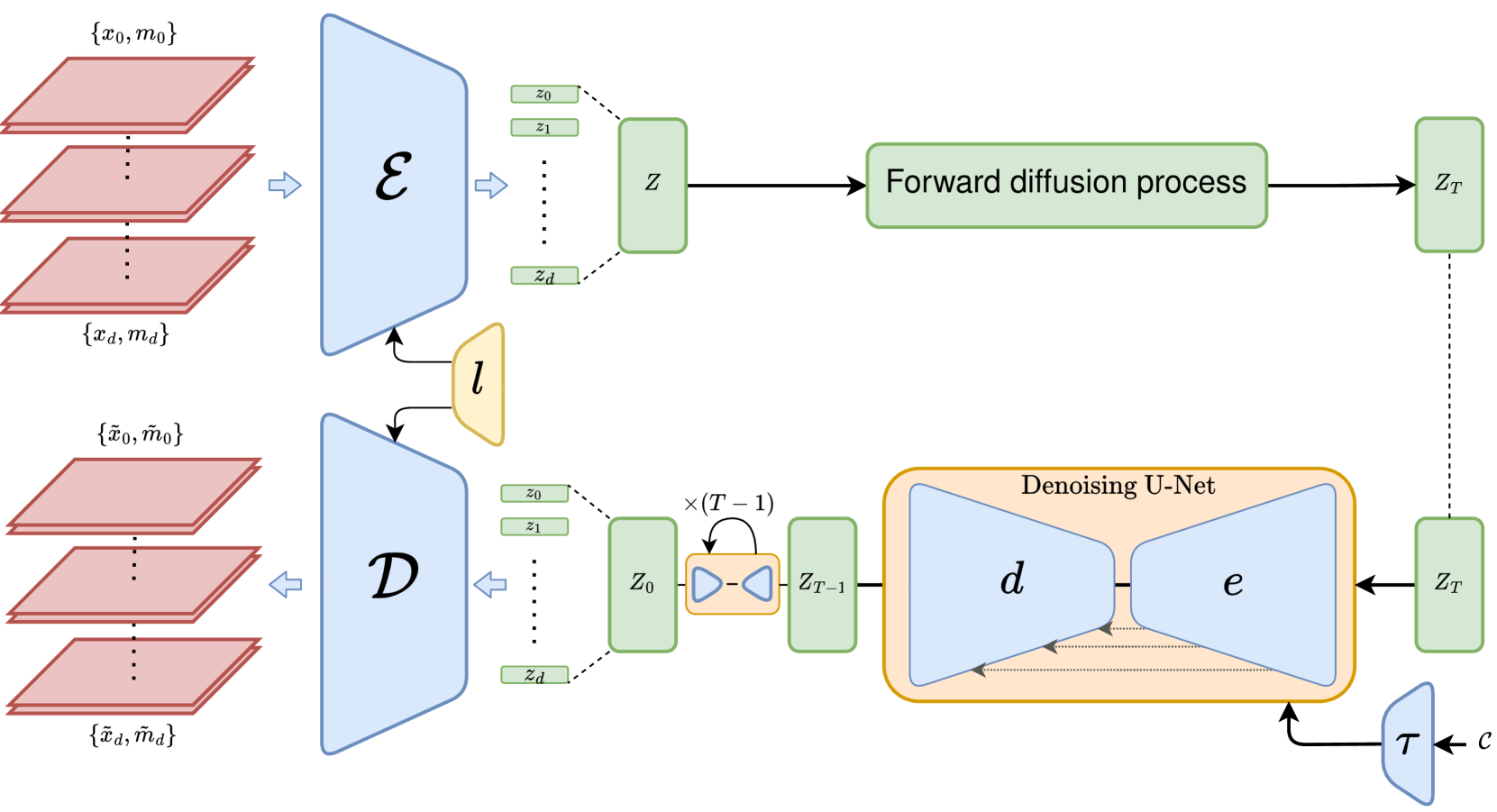
Despite the increasing use of deep learning in medical image segmentation, the limited availability of annotated training data remains a major challenge due to the time-consuming data acquisition and privacy regulations. In the context of segmentation tasks, providing both medical images and their corresponding target masks is essential. However, conventional data augmentation approaches mainly focus on image synthesis. In this study, we propose a novel slice-based latent diffusion architecture designed to address the complexities of volumetric data generation in a slice-by-slice fashion. This approach extends the joint distribution modeling of medical images and their associated masks, allowing a simultaneous generation of both under data-scarce regimes. Our approach mitigates the computational complexity and memory expensiveness typically associated with diffusion models. Furthermore, our architecture can be conditioned by tumor characteristics, including size, shape, and relative position, thereby providing a diverse range of tumor variations. Experiments on a segmentation task using the BRATS2022 confirm the effectiveness of the synthesized volumes and masks for data augmentation.
6/11/2024
Hyper-SD: Trajectory Segmented Consistency Model for Efficient Image Synthesis
Yuxi Ren, Xin Xia, Yanzuo Lu, Jiacheng Zhang, Jie Wu, Pan Xie, Xing Wang, Xuefeng Xiao
0
0
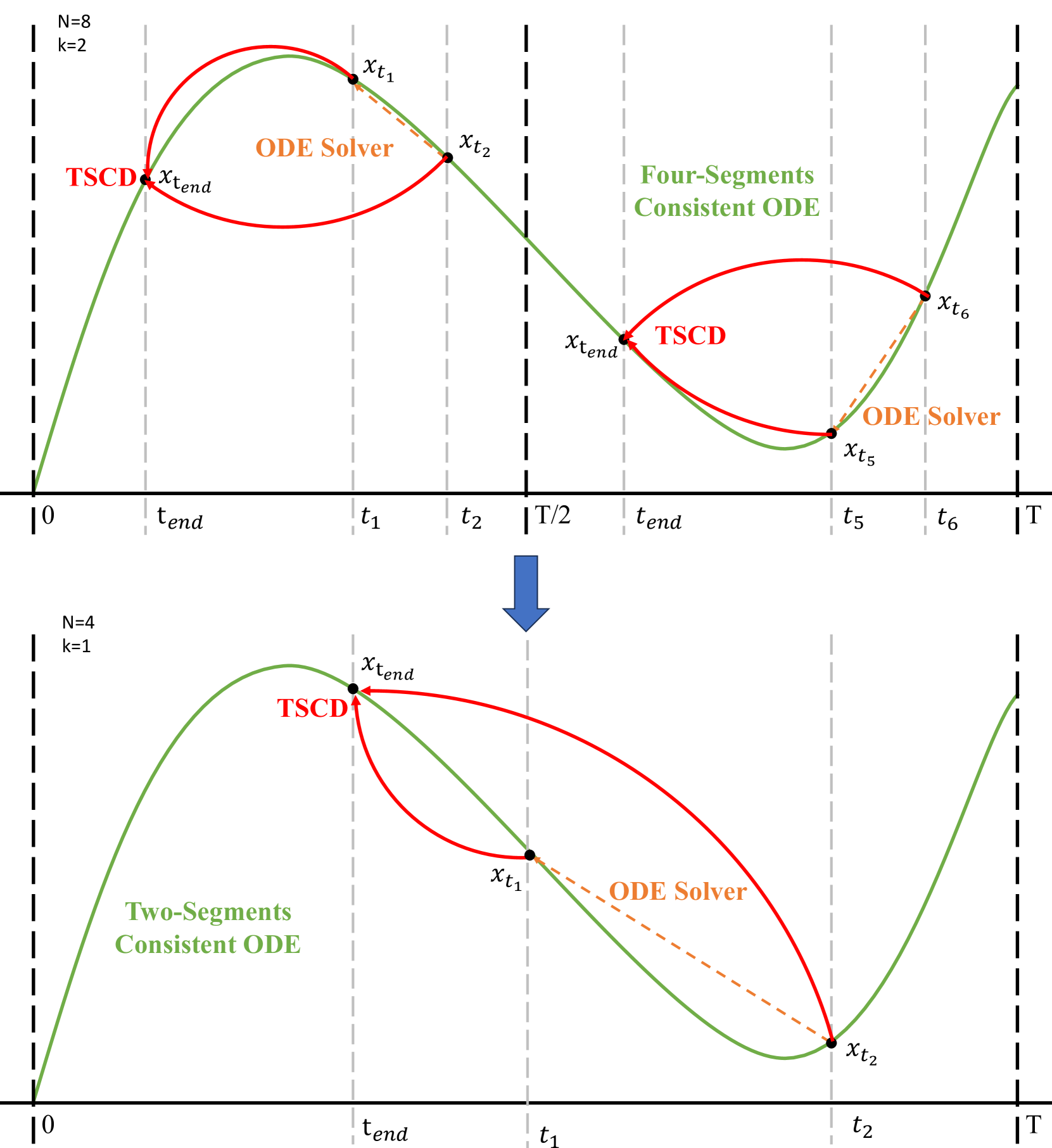
Recently, a series of diffusion-aware distillation algorithms have emerged to alleviate the computational overhead associated with the multi-step inference process of Diffusion Models (DMs). Current distillation techniques often dichotomize into two distinct aspects: i) ODE Trajectory Preservation; and ii) ODE Trajectory Reformulation. However, these approaches suffer from severe performance degradation or domain shifts. To address these limitations, we propose Hyper-SD, a novel framework that synergistically amalgamates the advantages of ODE Trajectory Preservation and Reformulation, while maintaining near-lossless performance during step compression. Firstly, we introduce Trajectory Segmented Consistency Distillation to progressively perform consistent distillation within pre-defined time-step segments, which facilitates the preservation of the original ODE trajectory from a higher-order perspective. Secondly, we incorporate human feedback learning to boost the performance of the model in a low-step regime and mitigate the performance loss incurred by the distillation process. Thirdly, we integrate score distillation to further improve the low-step generation capability of the model and offer the first attempt to leverage a unified LoRA to support the inference process at all steps. Extensive experiments and user studies demonstrate that Hyper-SD achieves SOTA performance from 1 to 8 inference steps for both SDXL and SD1.5. For example, Hyper-SDXL surpasses SDXL-Lightning by +0.68 in CLIP Score and +0.51 in Aes Score in the 1-step inference.
5/24/2024