DiffSeg: A Segmentation Model for Skin Lesions Based on Diffusion Difference
2404.16474
0
0
📈
Abstract
Weakly supervised medical image segmentation (MIS) using generative models is crucial for clinical diagnosis. However, the accuracy of the segmentation results is often limited by insufficient supervision and the complex nature of medical imaging. Existing models also only provide a single outcome, which does not allow for the measurement of uncertainty. In this paper, we introduce DiffSeg, a segmentation model for skin lesions based on diffusion difference which exploits diffusion model principles to ex-tract noise-based features from images with diverse semantic information. By discerning difference between these noise features, the model identifies diseased areas. Moreover, its multi-output capability mimics doctors' annotation behavior, facilitating the visualization of segmentation result consistency and ambiguity. Additionally, it quantifies output uncertainty using Generalized Energy Distance (GED), aiding interpretability and decision-making for physicians. Finally, the model integrates outputs through the Dense Conditional Random Field (DenseCRF) algorithm to refine the segmentation boundaries by considering inter-pixel correlations, which improves the accuracy and optimizes the segmentation results. We demonstrate the effectiveness of DiffSeg on the ISIC 2018 Challenge dataset, outperforming state-of-the-art U-Net-based methods.
Create account to get full access
Overview
- Weakly supervised medical image segmentation (MIS) is crucial for clinical diagnosis, but current models have limitations in accuracy and uncertainty handling.
- This paper introduces DiffSeg, a segmentation model for skin lesions that exploits diffusion model principles to extract noise-based features and identify diseased areas.
- DiffSeg provides multiple outputs, mimicking doctors' annotation behavior, and quantifies output uncertainty to aid interpretability and decision-making.
- The model also integrates outputs through the Dense Conditional Random Field (DenseCRF) algorithm to refine segmentation boundaries and improve accuracy.
- Experiments on the ISIC 2018 Challenge dataset show DiffSeg outperforms state-of-the-art U-Net-based methods.
Plain English Explanation
Medical image segmentation is the process of identifying and outlining specific structures or regions of interest within medical images, such as those from CT scans or MRI. This is crucial for clinical diagnosis, as it allows doctors to accurately assess and monitor various medical conditions.
However, current approaches to medical image segmentation often struggle with accuracy and uncertainty. The DiffSeg model introduced in this paper aims to address these challenges by using a novel technique based on "diffusion models."
Diffusion models are a type of machine learning algorithm that can generate new images by adding and then removing noise from an initial image. In the case of DiffSeg, the model uses this noise-based approach to extract features from medical images that are associated with different types of skin lesions or diseases.
By analyzing the differences in these noise-based features, the DiffSeg model can identify the areas of the image that are affected by a particular medical condition. Importantly, DiffSeg doesn't just provide a single segmentation result, but rather multiple outputs that mimic how doctors would annotate the image. This allows the model to visualize the consistency and ambiguity of the segmentation, providing valuable information to help doctors make more informed decisions.
Additionally, DiffSeg quantifies the uncertainty of its outputs using a metric called Generalized Energy Distance (GED). This uncertainty information can further aid doctors in interpreting the segmentation results and determining the reliability of the model's predictions.
Finally, the DiffSeg model integrates its outputs using an algorithm called Dense Conditional Random Field (DenseCRF), which refines the segmentation boundaries by considering the relationships between neighboring pixels. This helps to improve the overall accuracy of the segmentation.
Technical Explanation
The DiffSeg model is based on the principles of diffusion models, which have shown promise in zero-shot and weakly supervised medical image segmentation tasks.
The core idea of the DiffSeg architecture is to exploit the noise-based features extracted by the diffusion model to identify diseased areas within skin lesion images. Specifically, the model first encodes the input image into a set of diffusion-based latent representations, which capture the semantic information of the image at different noise levels.
The model then compares the differences between these noise-based features to discriminate between healthy and diseased regions. This difference-based approach allows the model to generate multiple segmentation outputs, mimicking the behavior of doctors who often provide multiple annotations for the same image.
To further improve the segmentation quality, DiffSeg integrates its outputs using the Dense Conditional Random Field (DenseCRF) algorithm. This step considers the relationships between neighboring pixels, refining the segmentation boundaries and optimizing the final results.
Importantly, the DiffSeg model also quantifies the uncertainty of its segmentation outputs using the Generalized Energy Distance (GED) metric. This uncertainty information can be valuable for physicians, as it allows them to assess the reliability of the model's predictions and make more informed decisions during the diagnostic process.
The researchers evaluate the performance of DiffSeg on the ISIC 2018 Challenge dataset, a widely used benchmark for skin lesion segmentation. The results show that DiffSeg outperforms state-of-the-art U-Net-based methods, demonstrating the effectiveness of the diffusion-based approach in addressing the challenges of weakly supervised medical image segmentation.
Critical Analysis
The DiffSeg model presents a innovative approach to medical image segmentation that leverages the power of diffusion models to extract noise-based features and quantify output uncertainty. By mimicking doctors' annotation behavior and providing multiple segmentation outputs, the model offers a more comprehensive and interpretable solution compared to traditional single-output segmentation methods.
One potential limitation of the DiffSeg model is that it is currently focused on skin lesion segmentation, and its performance on other types of medical images, such as those from CT or MRI scans, is yet to be evaluated. Additionally, while the Generalized Energy Distance (GED) metric provides a way to quantify uncertainty, it may be beneficial to explore other uncertainty estimation techniques, such as Monte Carlo dropout or ensemble methods, to further improve the model's interpretability and decision-support capabilities.
Furthermore, the paper could have delved deeper into the potential clinical implications of the DiffSeg model, exploring how the multi-output segmentation and uncertainty quantification features could enhance the diagnostic process and patient outcomes. Investigating the model's performance under different levels of data availability or annotation quality could also provide valuable insights for real-world deployment scenarios.
Overall, the DiffSeg model represents a promising step forward in the field of weakly supervised medical image segmentation, and the researchers' efforts to incorporate uncertainty quantification and multi-output capabilities are commendable. As the field continues to evolve, further research and validation of these innovative approaches will be crucial for improving the reliability and trustworthiness of medical image analysis tools.
Conclusion
The DiffSeg model introduced in this paper addresses key challenges in weakly supervised medical image segmentation by leveraging diffusion model principles to extract noise-based features and identify diseased areas. The model's multi-output capability and uncertainty quantification features provide valuable information to aid clinical decision-making, and its integration with the DenseCRF algorithm helps to refine segmentation boundaries and improve accuracy.
The promising results on the ISIC 2018 Challenge dataset demonstrate the potential of this approach to enhance medical diagnosis and patient care. As the field of medical image analysis continues to evolve, innovations like DiffSeg that prioritize interpretability, reliability, and clinical relevance will be crucial for developing trustworthy AI-powered tools that can truly benefit healthcare professionals and patients.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Anatomically-Controllable Medical Image Generation with Segmentation-Guided Diffusion Models
Nicholas Konz, Yuwen Chen, Haoyu Dong, Maciej A. Mazurowski
0
0
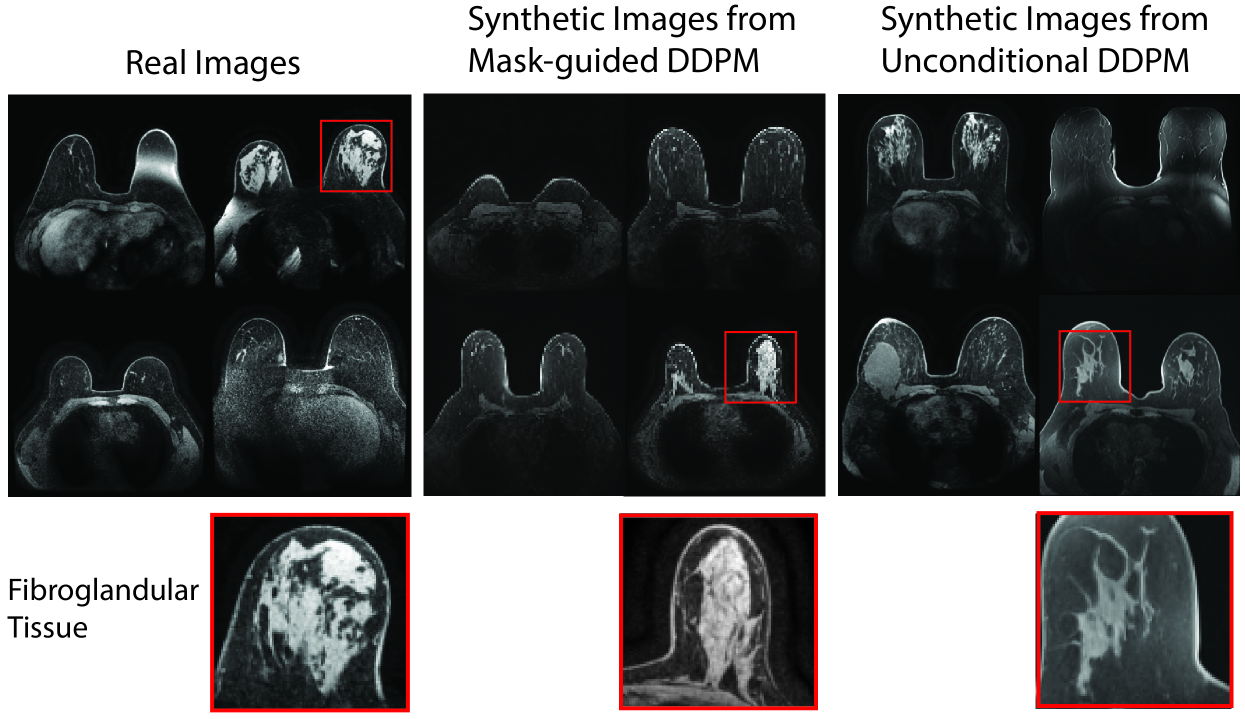
Diffusion models have enabled remarkably high-quality medical image generation, yet it is challenging to enforce anatomical constraints in generated images. To this end, we propose a diffusion model-based method that supports anatomically-controllable medical image generation, by following a multi-class anatomical segmentation mask at each sampling step. We additionally introduce a random mask ablation training algorithm to enable conditioning on a selected combination of anatomical constraints while allowing flexibility in other anatomical areas. We compare our method (SegGuidedDiff) to existing methods on breast MRI and abdominal/neck-to-pelvis CT datasets with a wide range of anatomical objects. Results show that our method reaches a new state-of-the-art in the faithfulness of generated images to input anatomical masks on both datasets, and is on par for general anatomical realism. Finally, our model also enjoys the extra benefit of being able to adjust the anatomical similarity of generated images to real images of choice through interpolation in its latent space. SegGuidedDiff has many applications, including cross-modality translation, and the generation of paired or counterfactual data. Our code is available at https://github.com/mazurowski-lab/segmentation-guided-diffusion.
6/21/2024
📉
Re-DiffiNet: Modeling discrepancies in tumor segmentation using diffusion models
Tianyi Ren, Abhishek Sharma, Juampablo Heras Rivera, Harshitha Rebala, Ethan Honey, Agamdeep Chopra, Jacob Ruzevick, Mehmet Kurt
0
0
Identification of tumor margins is essential for surgical decision-making for glioblastoma patients and provides reliable assistance for neurosurgeons. Despite improvements in deep learning architectures for tumor segmentation over the years, creating a fully autonomous system suitable for clinical floors remains a formidable challenge because the model predictions have not yet reached the desired level of accuracy and generalizability for clinical applications. Generative modeling techniques have seen significant improvements in recent times. Specifically, Generative Adversarial Networks (GANs) and Denoising-diffusion-based models (DDPMs) have been used to generate higher-quality images with fewer artifacts and finer attributes. In this work, we introduce a framework called Re-Diffinet for modeling the discrepancy between the outputs of a segmentation model like U-Net and the ground truth, using DDPMs. By explicitly modeling the discrepancy, the results show an average improvement of 0.55% in the Dice score and 16.28% in HD95 from cross-validation over 5-folds, compared to the state-of-the-art U-Net segmentation model.
4/11/2024

Stable Diffusion Segmentation for Biomedical Images with Single-step Reverse Process
Tianyu Lin, Zhiguang Chen, Zhonghao Yan, Weijiang Yu, Fudan Zheng
0
0
Diffusion models have demonstrated their effectiveness across various generative tasks. However, when applied to medical image segmentation, these models encounter several challenges, including significant resource and time requirements. They also necessitate a multi-step reverse process and multiple samples to produce reliable predictions. To address these challenges, we introduce the first latent diffusion segmentation model, named SDSeg, built upon stable diffusion (SD). SDSeg incorporates a straightforward latent estimation strategy to facilitate a single-step reverse process and utilizes latent fusion concatenation to remove the necessity for multiple samples. Extensive experiments indicate that SDSeg surpasses existing state-of-the-art methods on five benchmark datasets featuring diverse imaging modalities. Remarkably, SDSeg is capable of generating stable predictions with a solitary reverse step and sample, epitomizing the model's stability as implied by its name. The code is available at https://github.com/lin-tianyu/Stable-Diffusion-Seg
6/28/2024
FreeSeg-Diff: Training-Free Open-Vocabulary Segmentation with Diffusion Models
Barbara Toniella Corradini, Mustafa Shukor, Paul Couairon, Guillaume Couairon, Franco Scarselli, Matthieu Cord
0
0
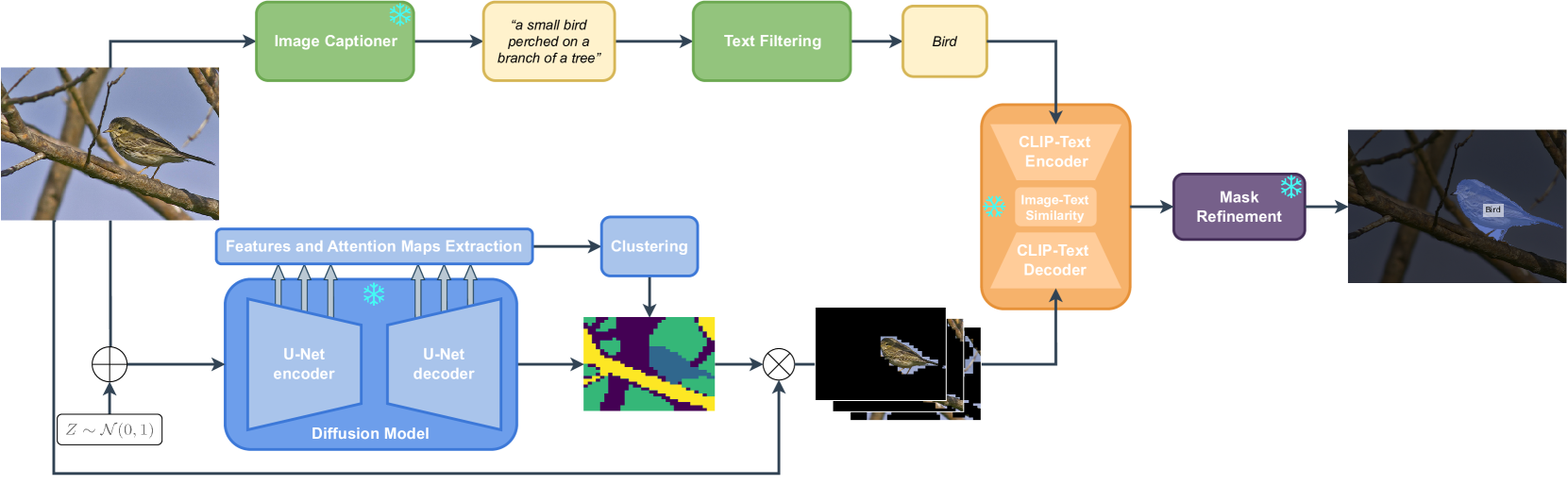
Foundation models have exhibited unprecedented capabilities in tackling many domains and tasks. Models such as CLIP are currently widely used to bridge cross-modal representations, and text-to-image diffusion models are arguably the leading models in terms of realistic image generation. Image generative models are trained on massive datasets that provide them with powerful internal spatial representations. In this work, we explore the potential benefits of such representations, beyond image generation, in particular, for dense visual prediction tasks. We focus on the task of image segmentation, which is traditionally solved by training models on closed-vocabulary datasets, with pixel-level annotations. To avoid the annotation cost or training large diffusion models, we constraint our setup to be zero-shot and training-free. In a nutshell, our pipeline leverages different and relatively small-sized, open-source foundation models for zero-shot open-vocabulary segmentation. The pipeline is as follows: the image is passed to both a captioner model (i.e. BLIP) and a diffusion model (i.e., Stable Diffusion Model) to generate a text description and visual representation, respectively. The features are clustered and binarized to obtain class agnostic masks for each object. These masks are then mapped to a textual class, using the CLIP model to support open-vocabulary. Finally, we add a refinement step that allows to obtain a more precise segmentation mask. Our approach (dubbed FreeSeg-Diff), which does not rely on any training, outperforms many training-based approaches on both Pascal VOC and COCO datasets. In addition, we show very competitive results compared to the recent weakly-supervised segmentation approaches. We provide comprehensive experiments showing the superiority of diffusion model features compared to other pretrained models. Project page: https://bcorrad.github.io/freesegdiff/
4/1/2024