StackRAG Agent: Improving Developer Answers with Retrieval-Augmented Generation

0
Sign in to get full access
Overview
• This paper introduces the StackRAG Agent, a tool that aims to improve developer answers on Stack Overflow by leveraging retrieval-augmented generation (RAG) techniques.
• The StackRAG Agent combines language models with information retrieval to generate more detailed and relevant responses to developer questions.
Plain English Explanation
The StackRAG Agent is a tool designed to enhance the quality of answers provided by developers on the popular question-and-answer platform Stack Overflow. It does this by combining two key technologies:
-
Language Models: These are artificial intelligence systems that are trained on vast amounts of text data to generate human-like language. They can be used to produce responses to questions.
-
Information Retrieval: This involves searching through a database of relevant information, such as previous Stack Overflow posts, to find the most pertinent details to include in a response.
By combining these two approaches, the StackRAG Agent can generate more comprehensive and accurate answers to developer questions. The language model helps to ensure the response is fluent and coherent, while the information retrieval component pulls in relevant details from past discussions to bolster the answer.
This approach aims to improve the quality of developer answers on Stack Overflow, which can be crucial for helping programmers solve their coding problems and enhance their skills.
Technical Explanation
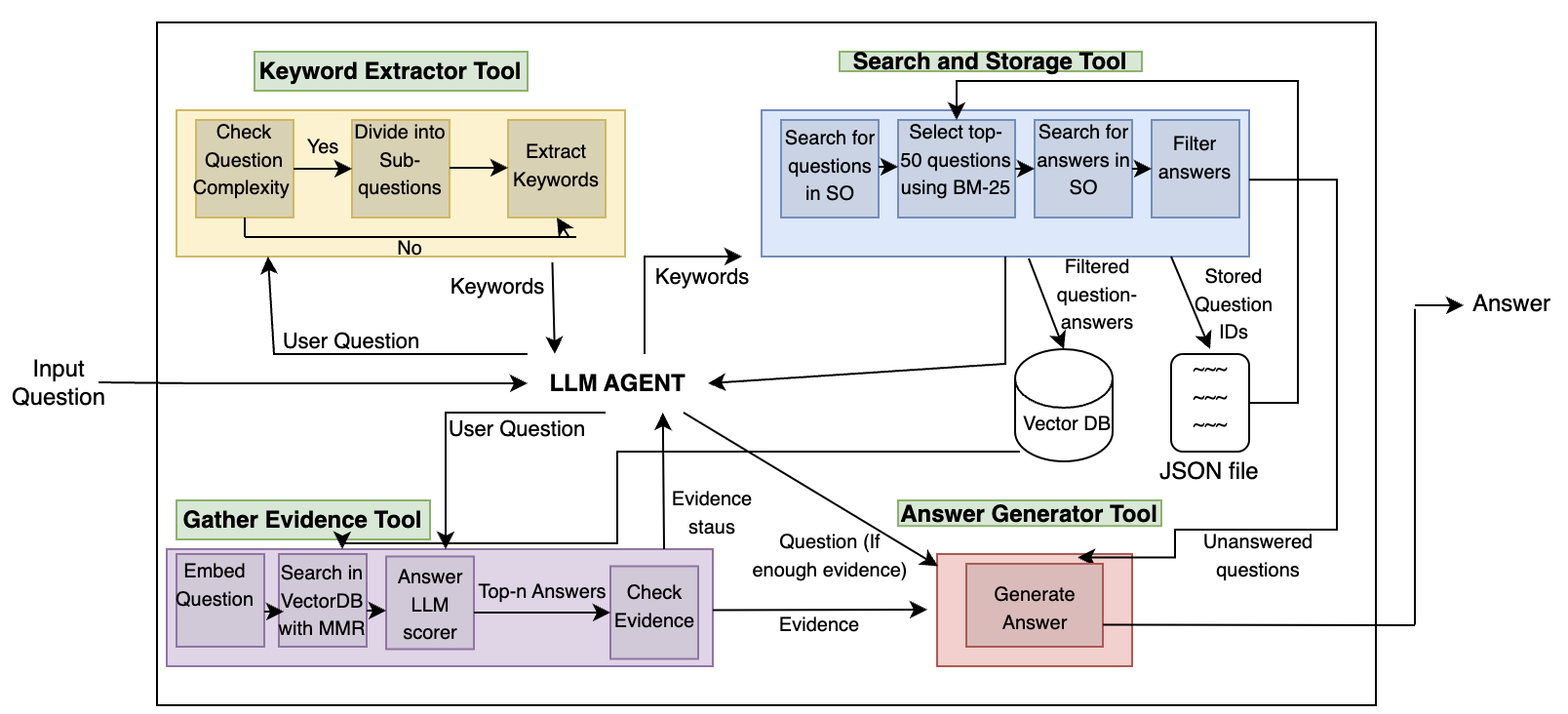
The core of the StackRAG Agent is a retrieval-augmented generation (RAG) model, which combines a language model with an information retrieval system.
The language model is trained on a large corpus of Stack Overflow discussions to learn the patterns and style of developer responses. The information retrieval component indexes the full text of previous Stack Overflow posts, allowing the system to quickly find the most relevant content to include in a new answer.
When a developer poses a question, the StackRAG Agent first uses the information retrieval system to identify the top-k most relevant past posts. It then feeds these retrieved passages, along with the original question, into the language model to generate a coherent and informative response.
The authors evaluate the StackRAG Agent on a dataset of Stack Overflow questions, comparing its performance to baseline language models and other retrieval-augmented approaches. They find that the StackRAG Agent is able to generate answers that are more accurate, detailed, and useful to developers than the alternatives.
Critical Analysis
The StackRAG Agent represents a promising step forward in leveraging retrieval-augmented generation techniques to improve question-answering systems. The combination of language modeling and information retrieval helps to overcome some of the limitations of standalone language models, which can struggle to provide comprehensive and grounded responses.
That said, the paper does not address certain potential limitations of the approach. For example, the StackRAG Agent relies on the availability of a large corpus of relevant information (i.e., past Stack Overflow posts) to retrieve from. In domains with less abundant data, the performance of the system may be diminished.
Additionally, the authors do not delve into potential biases or ethical considerations that may arise from the StackRAG Agent's responses. As an AI-powered tool influencing the information developers receive, it is important to understand and mitigate any unintended biases or harmful outputs.
Further research would be valuable to explore the robustness and generalizability of the StackRAG approach, as well as its applicability to other question-answering domains beyond Stack Overflow.
Conclusion
The StackRAG Agent represents an exciting advancement in the field of retrieval-augmented generation for conversational AI systems. By combining language modeling and information retrieval, the tool is able to generate more detailed, accurate, and useful answers to developer questions on Stack Overflow.
This approach holds promise for improving the quality of information available to programmers, which can in turn enhance their skills and productivity. As the field of AI-powered question-answering continues to evolve, the StackRAG Agent provides a compelling example of how retrieval-augmented techniques can be leveraged to create more effective and trustworthy conversational agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
StackRAG Agent: Improving Developer Answers with Retrieval-Augmented Generation
Davit Abrahamyan, Fatemeh H. Fard
Developers spend much time finding information that is relevant to their questions. Stack Overflow has been the leading resource, and with the advent of Large Language Models (LLMs), generative models such as ChatGPT are used frequently. However, there is a catch in using each one separately. Searching for answers is time-consuming and tedious, as shown by the many tools developed by researchers to address this issue. On the other, using LLMs is not reliable, as they might produce irrelevant or unreliable answers (i.e., hallucination). In this work, we present StackRAG, a retrieval-augmented Multiagent generation tool based on LLMs that combines the two worlds: aggregating the knowledge from SO to enhance the reliability of the generated answers. Initial evaluations show that the generated answers are correct, accurate, relevant, and useful.
Read more6/21/2024

0
RAG based Question-Answering for Contextual Response Prediction System
Sriram Veturi, Saurabh Vaichal, Reshma Lal Jagadheesh, Nafis Irtiza Tripto, Nian Yan
Large Language Models (LLMs) have shown versatility in various Natural Language Processing (NLP) tasks, including their potential as effective question-answering systems. However, to provide precise and relevant information in response to specific customer queries in industry settings, LLMs require access to a comprehensive knowledge base to avoid hallucinations. Retrieval Augmented Generation (RAG) emerges as a promising technique to address this challenge. Yet, developing an accurate question-answering framework for real-world applications using RAG entails several challenges: 1) data availability issues, 2) evaluating the quality of generated content, and 3) the costly nature of human evaluation. In this paper, we introduce an end-to-end framework that employs LLMs with RAG capabilities for industry use cases. Given a customer query, the proposed system retrieves relevant knowledge documents and leverages them, along with previous chat history, to generate response suggestions for customer service agents in the contact centers of a major retail company. Through comprehensive automated and human evaluations, we show that this solution outperforms the current BERT-based algorithms in accuracy and relevance. Our findings suggest that RAG-based LLMs can be an excellent support to human customer service representatives by lightening their workload.
Read more9/9/2024
🛸
0
PersonaRAG: Enhancing Retrieval-Augmented Generation Systems with User-Centric Agents
Saber Zerhoudi, Michael Granitzer
Large Language Models (LLMs) struggle with generating reliable outputs due to outdated knowledge and hallucinations. Retrieval-Augmented Generation (RAG) models address this by enhancing LLMs with external knowledge, but often fail to personalize the retrieval process. This paper introduces PersonaRAG, a novel framework incorporating user-centric agents to adapt retrieval and generation based on real-time user data and interactions. Evaluated across various question answering datasets, PersonaRAG demonstrates superiority over baseline models, providing tailored answers to user needs. The results suggest promising directions for user-adapted information retrieval systems.
Read more7/15/2024

0
The Geometry of Queries: Query-Based Innovations in Retrieval-Augmented Generation
Eric Yang, Jonathan Amar, Jong Ha Lee, Bhawesh Kumar, Yugang Jia
Digital health chatbots powered by Large Language Models (LLMs) have the potential to significantly improve personal health management for chronic conditions by providing accessible and on-demand health coaching and question-answering. However, these chatbots risk providing unverified and inaccurate information because LLMs generate responses based on patterns learned from diverse internet data. Retrieval Augmented Generation (RAG) can help mitigate hallucinations and inaccuracies in LLM responses by grounding it on reliable content. However, efficiently and accurately retrieving most relevant set of content for real-time user questions remains a challenge. In this work, we introduce Query-Based Retrieval Augmented Generation (QB-RAG), a novel approach that pre-computes a database of potential queries from a content base using LLMs. For an incoming patient question, QB-RAG efficiently matches it against this pre-generated query database using vector search, improving alignment between user questions and the content. We establish a theoretical foundation for QB-RAG and provide a comparative analysis of existing retrieval enhancement techniques for RAG systems. Finally, our empirical evaluation demonstrates that QB-RAG significantly improves the accuracy of healthcare question answering, paving the way for robust and trustworthy LLM applications in digital health.
Read more7/26/2024