Stance Detection on Social Media with Fine-Tuned Large Language Models
2404.12171
0
0
🔎
Abstract
Stance detection, a key task in natural language processing, determines an author's viewpoint based on textual analysis. This study evaluates the evolution of stance detection methods, transitioning from early machine learning approaches to the groundbreaking BERT model, and eventually to modern Large Language Models (LLMs) such as ChatGPT, LLaMa-2, and Mistral-7B. While ChatGPT's closed-source nature and associated costs present challenges, the open-source models like LLaMa-2 and Mistral-7B offers an encouraging alternative. Initially, our research focused on fine-tuning ChatGPT, LLaMa-2, and Mistral-7B using several publicly available datasets. Subsequently, to provide a comprehensive comparison, we assess the performance of these models in zero-shot and few-shot learning scenarios. The results underscore the exceptional ability of LLMs in accurately detecting stance, with all tested models surpassing existing benchmarks. Notably, LLaMa-2 and Mistral-7B demonstrate remarkable efficiency and potential for stance detection, despite their smaller sizes compared to ChatGPT. This study emphasizes the potential of LLMs in stance detection and calls for more extensive research in this field.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the use of fine-tuned large language models (LLMs) for stance detection on social media.
- Stance detection refers to the task of identifying whether an individual's opinion on a particular topic is in favor, against, or neutral.
- The researchers investigate how well LLMs like BERT and GPT-3 can be fine-tuned for this task.
- The paper also examines the impact of incorporating additional data sources, such as user profiles and social network information, to enhance model performance.
Plain English Explanation
The paper looks at how well powerful language models, like the ones used in ChatGPT and BERT, can be fine-tuned to detect people's stances or opinions on different topics when they post on social media. Stance detection is the task of figuring out whether someone is in favor of, against, or neutral about a particular issue based on what they write.
The researchers investigate how adding extra information, like a person's user profile and social network data, can improve the language models' ability to accurately detect stances. This is important because understanding people's opinions on topics like politics, social issues, or current events can provide valuable insights for businesses, governments, and researchers.
Technical Explanation
The paper explores the use of fine-tuned large language models (LLMs) for the task of stance detection on social media. Stance detection involves identifying whether an individual's opinion on a particular topic is in favor, against, or neutral.
The researchers experiment with fine-tuning models like BERT and GPT-3 on stance detection datasets. They also investigate the impact of incorporating additional data sources, such as user profiles and social network information, to enhance model performance.
The paper's key contributions include:
- Evaluating the effectiveness of fine-tuning LLMs for stance detection on social media
- Assessing the value of incorporating user-specific and network-based features to improve stance detection
- Providing insights into the strengths and limitations of using LLMs for this task
Critical Analysis
The paper presents a thorough evaluation of using fine-tuned LLMs for stance detection, and the researchers acknowledge several limitations and areas for further research. One potential concern is the reliance on self-reported user profiles and social network data, which may be noisy or biased.
Additionally, the paper does not delve into the interpretability or explainability of the fine-tuned models, which is an important consideration for real-world applications of these techniques. Further research could explore ways to enhance the interpretability of modeling decisions in the context of stance detection.
Another area for potential improvement is the handling of political entity sentiment in the social media posts, which could provide additional context for stance detection.
Conclusion
This paper demonstrates the potential of using fine-tuned large language models for stance detection on social media. The incorporation of user-specific and network-based features can enhance model performance, providing valuable insights into public opinions on various topics.
While the research has limitations, it contributes to the growing body of work on leveraging powerful language models for social media analysis. Further advancements in this area could lead to improved collaborative stance detection and more nuanced understanding of public sentiment on important issues.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Stance Detection with Collaborative Role-Infused LLM-Based Agents
Xiaochong Lan, Chen Gao, Depeng Jin, Yong Li
0
0
Stance detection automatically detects the stance in a text towards a target, vital for content analysis in web and social media research. Despite their promising capabilities, LLMs encounter challenges when directly applied to stance detection. First, stance detection demands multi-aspect knowledge, from deciphering event-related terminologies to understanding the expression styles in social media platforms. Second, stance detection requires advanced reasoning to infer authors' implicit viewpoints, as stance are often subtly embedded rather than overtly stated in the text. To address these challenges, we design a three-stage framework COLA (short for Collaborative rOle-infused LLM-based Agents) in which LLMs are designated distinct roles, creating a collaborative system where each role contributes uniquely. Initially, in the multidimensional text analysis stage, we configure the LLMs to act as a linguistic expert, a domain specialist, and a social media veteran to get a multifaceted analysis of texts, thus overcoming the first challenge. Next, in the reasoning-enhanced debating stage, for each potential stance, we designate a specific LLM-based agent to advocate for it, guiding the LLM to detect logical connections between text features and stance, tackling the second challenge. Finally, in the stance conclusion stage, a final decision maker agent consolidates prior insights to determine the stance. Our approach avoids extra annotated data and model training and is highly usable. We achieve state-of-the-art performance across multiple datasets. Ablation studies validate the effectiveness of each design role in handling stance detection. Further experiments have demonstrated the explainability and the versatility of our approach. Our approach excels in usability, accuracy, effectiveness, explainability and versatility, highlighting its value.
4/17/2024
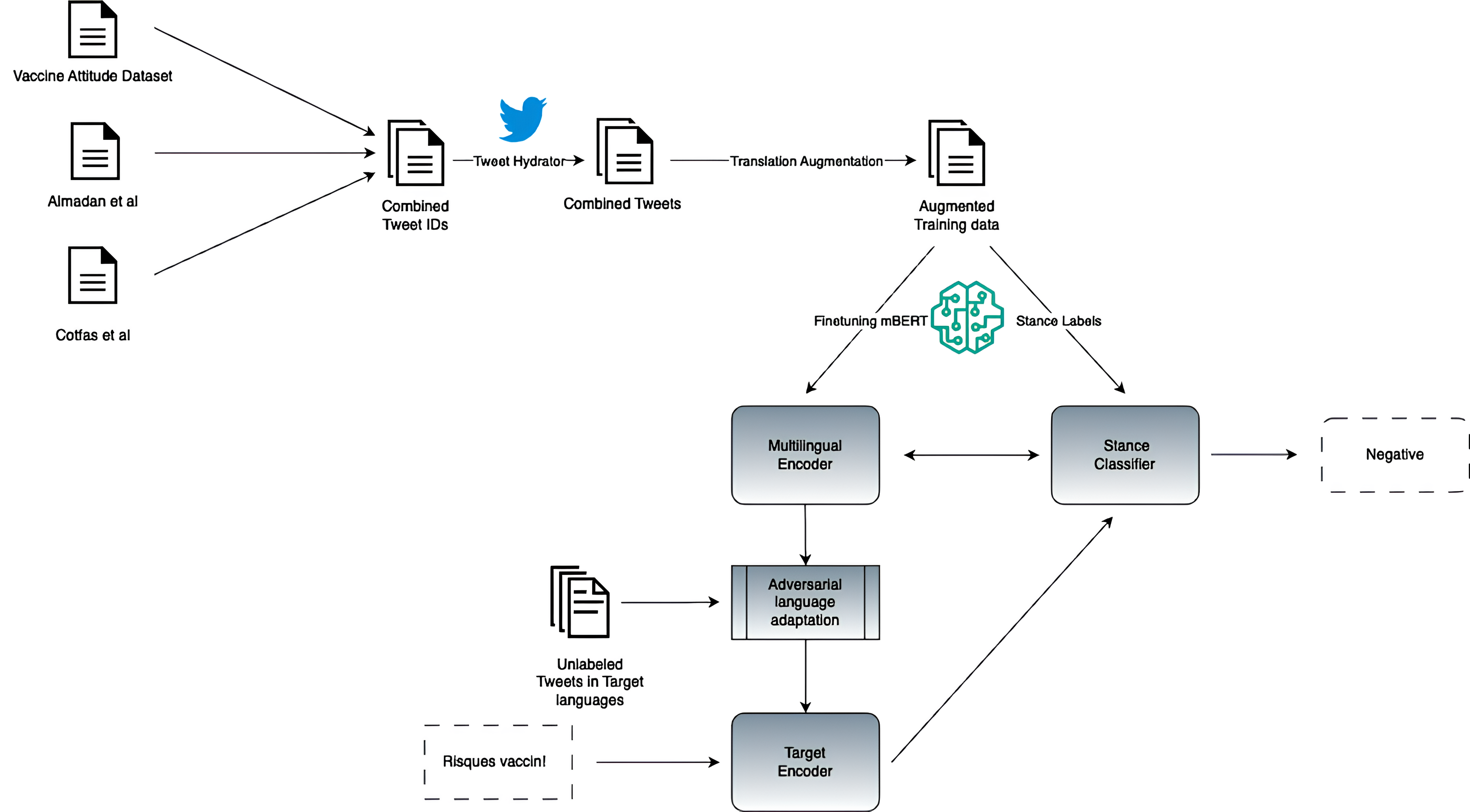
Zero-shot Cross-lingual Stance Detection via Adversarial Language Adaptation
Bharathi A, Arkaitz Zubiaga
0
0
Stance detection has been widely studied as the task of determining if a social media post is positive, negative or neutral towards a specific issue, such as support towards vaccines. Research in stance detection has however often been limited to a single language and, where more than one language has been studied, research has focused on few-shot settings, overlooking the challenges of developing a zero-shot cross-lingual stance detection model. This paper makes the first such effort by introducing a novel approach to zero-shot cross-lingual stance detection, Multilingual Translation-Augmented BERT (MTAB), aiming to enhance the performance of a cross-lingual classifier in the absence of explicit training data for target languages. Our technique employs translation augmentation to improve zero-shot performance and pairs it with adversarial learning to further boost model efficacy. Through experiments on datasets labeled for stance towards vaccines in four languages English, German, French, Italian. We demonstrate the effectiveness of our proposed approach, showcasing improved results in comparison to a strong baseline model as well as ablated versions of our model. Our experiments demonstrate the effectiveness of model components, not least the translation-augmented data as well as the adversarial learning component, to the improved performance of the model. We have made our source code accessible on GitHub.
4/23/2024
💬
Rumour Evaluation with Very Large Language Models
Dahlia Shehata, Robin Cohen, Charles Clarke
0
0
Conversational prompt-engineering-based large language models (LLMs) have enabled targeted control over the output creation, enhancing versatility, adaptability and adhoc retrieval. From another perspective, digital misinformation has reached alarming levels. The anonymity, availability and reach of social media offer fertile ground for rumours to propagate. This work proposes to leverage the advancement of prompting-dependent LLMs to combat misinformation by extending the research efforts of the RumourEval task on its Twitter dataset. To the end, we employ two prompting-based LLM variants (GPT-3.5-turbo and GPT-4) to extend the two RumourEval subtasks: (1) veracity prediction, and (2) stance classification. For veracity prediction, three classifications schemes are experimented per GPT variant. Each scheme is tested in zero-, one- and few-shot settings. Our best results outperform the precedent ones by a substantial margin. For stance classification, prompting-based-approaches show comparable performance to prior results, with no improvement over finetuning methods. Rumour stance subtask is also extended beyond the original setting to allow multiclass classification. All of the generated predictions for both subtasks are equipped with confidence scores determining their trustworthiness degree according to the LLM, and post-hoc justifications for explainability and interpretability purposes. Our primary aim is AI for social good.
4/29/2024

Auditing Large Language Models for Enhanced Text-Based Stereotype Detection and Probing-Based Bias Evaluation
Zekun Wu, Sahan Bulathwela, Maria Perez-Ortiz, Adriano Soares Koshiyama
0
0
Recent advancements in Large Language Models (LLMs) have significantly increased their presence in human-facing Artificial Intelligence (AI) applications. However, LLMs could reproduce and even exacerbate stereotypical outputs from training data. This work introduces the Multi-Grain Stereotype (MGS) dataset, encompassing 51,867 instances across gender, race, profession, religion, and stereotypical text, collected by fusing multiple previously publicly available stereotype detection datasets. We explore different machine learning approaches aimed at establishing baselines for stereotype detection, and fine-tune several language models of various architectures and model sizes, presenting in this work a series of stereotypes classifier models for English text trained on MGS. To understand whether our stereotype detectors capture relevant features (aligning with human common sense) we utilise a variety of explanainable AI tools, including SHAP, LIME, and BertViz, and analyse a series of example cases discussing the results. Finally, we develop a series of stereotype elicitation prompts and evaluate the presence of stereotypes in text generation tasks with popular LLMs, using one of our best performing previously presented stereotypes detectors. Our experiments yielded several key findings: i) Training stereotype detectors in a multi-dimension setting yields better results than training multiple single-dimension classifiers.ii) The integrated MGS Dataset enhances both the in-dataset and cross-dataset generalisation ability of stereotype detectors compared to using the datasets separately. iii) There is a reduction in stereotypes in the content generated by GPT Family LLMs with newer versions.
4/3/2024