Deciphering Political Entity Sentiment in News with Large Language Models: Zero-Shot and Few-Shot Strategies
2404.04361
0
0
Abstract
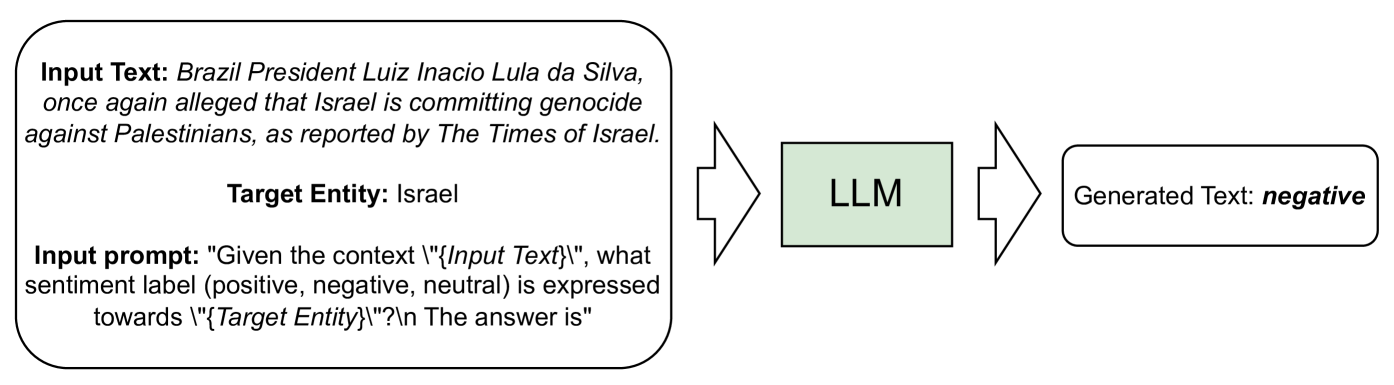
Sentiment analysis plays a pivotal role in understanding public opinion, particularly in the political domain where the portrayal of entities in news articles influences public perception. In this paper, we investigate the effectiveness of Large Language Models (LLMs) in predicting entity-specific sentiment from political news articles. Leveraging zero-shot and few-shot strategies, we explore the capability of LLMs to discern sentiment towards political entities in news content. Employing a chain-of-thought (COT) approach augmented with rationale in few-shot in-context learning, we assess whether this method enhances sentiment prediction accuracy. Our evaluation on sentiment-labeled datasets demonstrates that LLMs, outperform fine-tuned BERT models in capturing entity-specific sentiment. We find that learning in-context significantly improves model performance, while the self-consistency mechanism enhances consistency in sentiment prediction. Despite the promising results, we observe inconsistencies in the effectiveness of the COT prompting method. Overall, our findings underscore the potential of LLMs in entity-centric sentiment analysis within the political news domain and highlight the importance of suitable prompting strategies and model architectures.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the use of large language models (LLMs) to analyze the sentiment of political entities mentioned in news articles.
- The researchers investigate both zero-shot and few-shot prompting strategies to determine the sentiment toward various political figures and organizations.
- The goal is to develop methods that can effectively extract and interpret the sentiment expressed in news coverage of political topics.
Plain English Explanation
The researchers in this study looked at how well large language models (LLMs) - powerful AI systems trained on massive amounts of text data - can be used to understand the sentiment or emotional tone toward different political entities (such as politicians, political parties, or government agencies) that are mentioned in news articles.
They tested two main approaches:
- Zero-shot prompting - where the LLM is given minimal instructions and has to figure out the task on its own
- Few-shot prompting - where the LLM is given a small number of example inputs and outputs to help guide its understanding of the task
The goal was to develop techniques that could reliably extract the sentiment or "feeling" expressed in news coverage towards various political figures, organizations, and topics. This kind of analysis could be useful for understanding public discourse and opinion around political issues.
Technical Explanation
The researchers first collected a dataset of news articles containing mentions of various political entities. They then explored two main approaches for using LLMs to analyze the sentiment expressed towards these entities:
-
Zero-shot prompting: The researchers provided the LLM with a simple prompt asking it to classify the sentiment (positive, negative, or neutral) expressed towards a given political entity in a news article passage. The LLM had to determine the sentiment without any additional training or guidance.
-
Few-shot prompting: Here, the researchers provided the LLM with a small number of example inputs (news article passages) and their corresponding sentiment labels. The LLM could then use these examples to learn how to better recognize and classify the sentiment expressed in new passages.
The researchers experimented with different LLM architectures, such as BERT and GPT-3, and compared the performance of the zero-shot and few-shot approaches. They also explored ways to leverage contextual information to improve the sentiment analysis.
The results provide insights into the strengths and limitations of using LLMs for this type of political entity sentiment analysis task. The researchers discuss the implications of their findings and potential avenues for further research.
Critical Analysis
The paper provides a thorough evaluation of the zero-shot and few-shot prompting strategies for political entity sentiment analysis using LLMs. The researchers acknowledge several key limitations and areas for improvement:
- The dataset used is relatively small, and the researchers note that larger and more diverse datasets may be needed to fully capture the complexities of political sentiment in news coverage.
- The zero-shot prompting approach struggled to consistently identify sentiment, suggesting that LLMs may require more targeted training or guidance to excel at this task.
- The few-shot prompting approach performed better but still had room for improvement, particularly in distinguishing between positive and neutral sentiment.
- The researchers did not explore the potential biases that may be present in the LLMs or the news articles themselves, which could influence the sentiment analysis.
Overall, the paper makes a valuable contribution by demonstrating both the promise and the limitations of using LLMs for political entity sentiment analysis. The researchers highlight the need for further research to develop more robust and reliable techniques in this area.
Conclusion
This study explores the use of large language models (LLMs) to analyze the sentiment expressed towards political entities in news articles. The researchers tested two main approaches - zero-shot prompting and few-shot prompting - and found that while LLMs show promise for this task, there are still significant challenges to overcome.
The findings suggest that LLMs may require more targeted training or guidance to consistently and accurately identify the sentiment expressed towards political figures, organizations, and issues in news coverage. Further research with larger and more diverse datasets, as well as a deeper understanding of potential biases, will be essential for developing reliable tools for political sentiment analysis using natural language processing.
Overall, this paper provides valuable insights into the current state of the art and the path forward for leveraging powerful LLMs to better understand the dynamics of political discourse in the media.
Related Papers
💬
Large Language Models in Targeted Sentiment Analysis
Nicolay Rusnachenko, Anton Golubev, Natalia Loukachevitch
0
0
In this paper we investigate the use of decoder-based generative transformers for extracting sentiment towards the named entities in Russian news articles. We study sentiment analysis capabilities of instruction-tuned large language models (LLMs). We consider the dataset of RuSentNE-2023 in our study. The first group of experiments was aimed at the evaluation of zero-shot capabilities of LLMs with closed and open transparencies. The second covers the fine-tuning of Flan-T5 using the chain-of-thought (CoT) three-hop reasoning framework (THoR). We found that the results of the zero-shot approaches are similar to the results achieved by baseline fine-tuned encoder-based transformers (BERT-base). Reasoning capabilities of the fine-tuned Flan-T5 models with THoR achieve at least 5% increment with the base-size model compared to the results of the zero-shot experiment. The best results of sentiment analysis on RuSentNE-2023 were achieved by fine-tuned Flan-T5-xl, which surpassed the results of previous state-of-the-art transformer-based classifiers. Our CoT application framework is publicly available: https://github.com/nicolay-r/Reasoning-for-Sentiment-Analysis-Framework
4/19/2024
⚙️
Zero- and Few-Shot Prompting with LLMs: A Comparative Study with Fine-tuned Models for Bangla Sentiment Analysis
Md. Arid Hasan, Shudipta Das, Afiyat Anjum, Firoj Alam, Anika Anjum, Avijit Sarker, Sheak Rashed Haider Noori
0
0
The rapid expansion of the digital world has propelled sentiment analysis into a critical tool across diverse sectors such as marketing, politics, customer service, and healthcare. While there have been significant advancements in sentiment analysis for widely spoken languages, low-resource languages, such as Bangla, remain largely under-researched due to resource constraints. Furthermore, the recent unprecedented performance of Large Language Models (LLMs) in various applications highlights the need to evaluate them in the context of low-resource languages. In this study, we present a sizeable manually annotated dataset encompassing 33,606 Bangla news tweets and Facebook comments. We also investigate zero- and few-shot in-context learning with several language models, including Flan-T5, GPT-4, and Bloomz, offering a comparative analysis against fine-tuned models. Our findings suggest that monolingual transformer-based models consistently outperform other models, even in zero and few-shot scenarios. To foster continued exploration, we intend to make this dataset and our research tools publicly available to the broader research community.
4/8/2024
💬
Unveiling the Potential of Sentiment: Can Large Language Models Predict Chinese Stock Price Movements?
Haohan Zhang, Fengrui Hua, Chengjin Xu, Hao Kong, Ruiting Zuo, Jian Guo
0
0
The rapid advancement of Large Language Models (LLMs) has spurred discussions about their potential to enhance quantitative trading strategies. LLMs excel in analyzing sentiments about listed companies from financial news, providing critical insights for trading decisions. However, the performance of LLMs in this task varies substantially due to their inherent characteristics. This paper introduces a standardized experimental procedure for comprehensive evaluations. We detail the methodology using three distinct LLMs, each embodying a unique approach to performance enhancement, applied specifically to the task of sentiment factor extraction from large volumes of Chinese news summaries. Subsequently, we develop quantitative trading strategies using these sentiment factors and conduct back-tests in realistic scenarios. Our results will offer perspectives about the performances of Large Language Models applied to extracting sentiments from Chinese news texts.
5/7/2024
🔎
Stance Detection on Social Media with Fine-Tuned Large Language Models
.Ilker Gul, R'emi Lebret, Karl Aberer
0
0
Stance detection, a key task in natural language processing, determines an author's viewpoint based on textual analysis. This study evaluates the evolution of stance detection methods, transitioning from early machine learning approaches to the groundbreaking BERT model, and eventually to modern Large Language Models (LLMs) such as ChatGPT, LLaMa-2, and Mistral-7B. While ChatGPT's closed-source nature and associated costs present challenges, the open-source models like LLaMa-2 and Mistral-7B offers an encouraging alternative. Initially, our research focused on fine-tuning ChatGPT, LLaMa-2, and Mistral-7B using several publicly available datasets. Subsequently, to provide a comprehensive comparison, we assess the performance of these models in zero-shot and few-shot learning scenarios. The results underscore the exceptional ability of LLMs in accurately detecting stance, with all tested models surpassing existing benchmarks. Notably, LLaMa-2 and Mistral-7B demonstrate remarkable efficiency and potential for stance detection, despite their smaller sizes compared to ChatGPT. This study emphasizes the potential of LLMs in stance detection and calls for more extensive research in this field.
4/19/2024