Investigating the Robustness of Modelling Decisions for Few-Shot Cross-Topic Stance Detection: A Preregistered Study

0

Sign in to get full access
Overview
• This paper investigates the robustness of modeling decisions for few-shot cross-topic stance detection, a task where a model must determine the stance (e.g., for or against) of a given text on a topic using only a few examples.
• The authors conduct a preregistered study to systematically examine the impact of various modeling choices, such as the choice of language model, few-shot learning approach, and data augmentation techniques, on the performance and reliability of stance detection models.
Plain English Explanation
• Stance detection is the task of determining whether a piece of text, such as a social media post or news article, expresses a positive, negative, or neutral stance towards a particular topic or issue. This is an important task for understanding public opinion and sentiment.
• Few-shot learning refers to a setting where a model must learn to perform a task, like stance detection, using only a small number of training examples. This is challenging because the model has to generalize from very little data.
• The authors of this paper want to understand how different modeling choices, like the type of language model used or the data augmentation techniques employed, affect the performance and reliability of few-shot stance detection models. They conduct a carefully planned study to systematically explore these factors.
• By understanding the impact of these modeling decisions, the researchers hope to provide guidance to others working on few-shot stance detection and similar tasks, helping them build more robust and reliable models.
Technical Explanation
• The paper proposes a preregistered study to investigate the robustness of modeling decisions for few-shot cross-topic stance detection. This involves systematically evaluating the impact of choices like language model, few-shot learning approach, and data augmentation on model performance.
• The authors consider several language models, including BERT, RoBERTa, and BART, as well as few-shot learning techniques like prototypical networks and meta-learning. They also explore the use of data augmentation methods to boost performance in the low-resource setting.
• The study is conducted on several stance detection datasets covering different topics, allowing the researchers to assess the cross-topic generalization capabilities of the models. The preregistration helps ensure the validity and transparency of the experimental design and analysis.
Critical Analysis
• The preregistered study design is a notable strength of this work, as it helps mitigate potential biases and p-hacking issues that can arise in exploratory machine learning research.
• However, the paper does not provide much discussion of the limitations or potential caveats of the work. For example, it would be helpful to understand the extent to which the findings generalize beyond the specific datasets and domains studied.
• Additionally, the paper does not delve into the interpretability or explainability of the stance detection models, which could be an important consideration for real-world applications of this technology.
Conclusion
• This paper presents a systematic investigation of the robustness of modeling decisions for few-shot cross-topic stance detection, a task with important applications in understanding public opinion and sentiment.
• The preregistered study design and comprehensive evaluation across multiple datasets and modeling choices provide valuable insights into the factors that influence the performance and reliability of few-shot stance detection models.
• These findings can help guide future research and development in this area, contributing to the creation of more robust and effective models for few-shot stance detection and related tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Investigating the Robustness of Modelling Decisions for Few-Shot Cross-Topic Stance Detection: A Preregistered Study
Myrthe Reuver, Suzan Verberne, Antske Fokkens
For a viewpoint-diverse news recommender, identifying whether two news articles express the same viewpoint is essential. One way to determine same or different viewpoint is stance detection. In this paper, we investigate the robustness of operationalization choices for few-shot stance detection, with special attention to modelling stance across different topics. Our experiments test pre-registered hypotheses on stance detection. Specifically, we compare two stance task definitions (Pro/Con versus Same Side Stance), two LLM architectures (bi-encoding versus cross-encoding), and adding Natural Language Inference knowledge, with pre-trained RoBERTa models trained with shots of 100 examples from 7 different stance detection datasets. Some of our hypotheses and claims from earlier work can be confirmed, while others give more inconsistent results. The effect of the Same Side Stance definition on performance differs per dataset and is influenced by other modelling choices. We found no relationship between the number of training topics in the training shots and performance. In general, cross-encoding out-performs bi-encoding, and adding NLI training to our models gives considerable improvement, but these results are not consistent across all datasets. Our results indicate that it is essential to include multiple datasets and systematic modelling experiments when aiming to find robust modelling choices for the concept `stance'.
Read more4/8/2024
🔎
0
Stance Detection on Social Media with Fine-Tuned Large Language Models
.Ilker Gul, R'emi Lebret, Karl Aberer
Stance detection, a key task in natural language processing, determines an author's viewpoint based on textual analysis. This study evaluates the evolution of stance detection methods, transitioning from early machine learning approaches to the groundbreaking BERT model, and eventually to modern Large Language Models (LLMs) such as ChatGPT, LLaMa-2, and Mistral-7B. While ChatGPT's closed-source nature and associated costs present challenges, the open-source models like LLaMa-2 and Mistral-7B offers an encouraging alternative. Initially, our research focused on fine-tuning ChatGPT, LLaMa-2, and Mistral-7B using several publicly available datasets. Subsequently, to provide a comprehensive comparison, we assess the performance of these models in zero-shot and few-shot learning scenarios. The results underscore the exceptional ability of LLMs in accurately detecting stance, with all tested models surpassing existing benchmarks. Notably, LLaMa-2 and Mistral-7B demonstrate remarkable efficiency and potential for stance detection, despite their smaller sizes compared to ChatGPT. This study emphasizes the potential of LLMs in stance detection and calls for more extensive research in this field.
Read more4/19/2024

0
Multi-modal Stance Detection: New Datasets and Model
Bin Liang, Ang Li, Jingqian Zhao, Lin Gui, Min Yang, Yue Yu, Kam-Fai Wong, Ruifeng Xu
Stance detection is a challenging task that aims to identify public opinion from social media platforms with respect to specific targets. Previous work on stance detection largely focused on pure texts. In this paper, we study multi-modal stance detection for tweets consisting of texts and images, which are prevalent in today's fast-growing social media platforms where people often post multi-modal messages. To this end, we create five new multi-modal stance detection datasets of different domains based on Twitter, in which each example consists of a text and an image. In addition, we propose a simple yet effective Targeted Multi-modal Prompt Tuning framework (TMPT), where target information is leveraged to learn multi-modal stance features from textual and visual modalities. Experimental results on our five benchmark datasets show that the proposed TMPT achieves state-of-the-art performance in multi-modal stance detection.
Read more6/7/2024
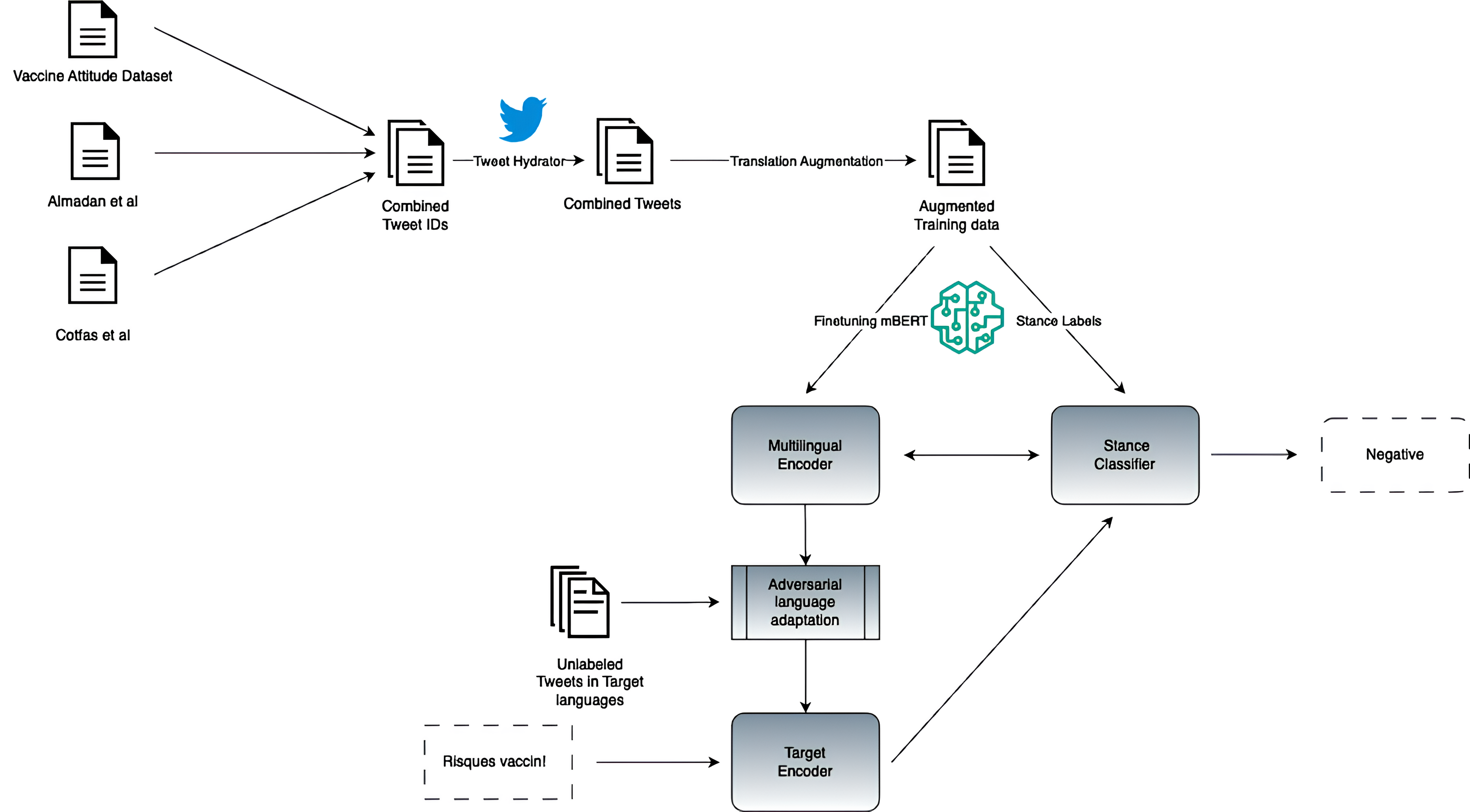
0
Zero-shot Cross-lingual Stance Detection via Adversarial Language Adaptation
Bharathi A, Arkaitz Zubiaga
Stance detection has been widely studied as the task of determining if a social media post is positive, negative or neutral towards a specific issue, such as support towards vaccines. Research in stance detection has however often been limited to a single language and, where more than one language has been studied, research has focused on few-shot settings, overlooking the challenges of developing a zero-shot cross-lingual stance detection model. This paper makes the first such effort by introducing a novel approach to zero-shot cross-lingual stance detection, Multilingual Translation-Augmented BERT (MTAB), aiming to enhance the performance of a cross-lingual classifier in the absence of explicit training data for target languages. Our technique employs translation augmentation to improve zero-shot performance and pairs it with adversarial learning to further boost model efficacy. Through experiments on datasets labeled for stance towards vaccines in four languages English, German, French, Italian. We demonstrate the effectiveness of our proposed approach, showcasing improved results in comparison to a strong baseline model as well as ablated versions of our model. Our experiments demonstrate the effectiveness of model components, not least the translation-augmented data as well as the adversarial learning component, to the improved performance of the model. We have made our source code accessible on GitHub.
Read more4/23/2024