On Stateful Value Factorization in Multi-Agent Reinforcement Learning

0
Sign in to get full access
Overview
- This paper presents a new approach called Stateful Value Factorization (SVF) for multi-agent reinforcement learning.
- SVF aims to learn a compact representation of each agent's value function that captures the dependencies between the agent's local state and the joint state of all agents.
- The method is designed to improve the sample efficiency and scalability of multi-agent reinforcement learning algorithms.
Plain English Explanation
In reinforcement learning, an agent learns to make decisions by interacting with an environment and receiving rewards. When there are multiple agents interacting in the same environment, this is known as multi-agent reinforcement learning.
The challenge in multi-agent reinforcement learning is that each agent's value function (i.e., how much future reward it expects to receive) depends not only on its own local state, but also on the states of the other agents. This makes the problem much more complex and difficult to learn efficiently.
The key idea behind Stateful Value Factorization (SVF) is to learn a compact representation of each agent's value function that captures these dependencies between the agent's local state and the joint state of all agents. By learning this compact representation, the algorithm can learn more efficiently and scale better to larger multi-agent environments.
The paper shows that SVF outperforms other state-of-the-art multi-agent reinforcement learning algorithms on a variety of benchmark tasks, demonstrating its potential for improving the sample efficiency and scalability of multi-agent reinforcement learning.
Technical Explanation
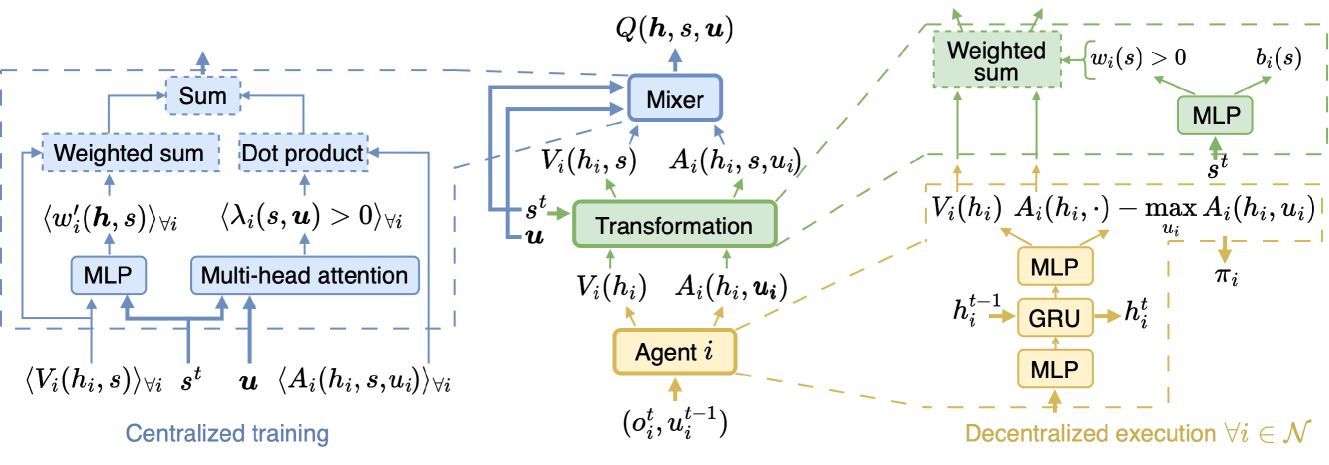
The authors propose a new algorithm called Stateful Value Factorization (SVF) for multi-agent reinforcement learning. The key idea is to learn a compact representation of each agent's value function that captures the dependencies between the agent's local state and the joint state of all agents.
Specifically, SVF learns a factorized representation of the value function that decomposes it into a set of
The authors show that SVF outperforms other state-of-the-art multi-agent reinforcement learning algorithms on a variety of benchmark tasks, including particle environments and the StarCraft multi-agent challenge. The results demonstrate the potential of SVF to improve the sample efficiency and scalability of multi-agent reinforcement learning.
Critical Analysis
The paper provides a thorough evaluation of the SVF algorithm and compares it to several baselines on a range of multi-agent reinforcement learning tasks. The results are promising and suggest that the factorized representation of the value function can indeed lead to improved sample efficiency and scalability.
However, the paper does not explicitly discuss the limitations or potential drawbacks of the SVF approach. For example, it is not clear how the factorized representation scales to very large numbers of agents or how sensitive the algorithm is to the choice of the factorization structure.
Additionally, the paper does not explore the interpretability or explainability of the learned factorized value functions. Understanding the dependencies captured by the factorization could provide valuable insights into the multi-agent dynamics, which could be useful for designing better exploration strategies or for transfer learning to related tasks.
Overall, the paper presents a novel and promising approach to multi-agent reinforcement learning, but further research is needed to fully understand its strengths, weaknesses, and potential applications.
Conclusion
This paper introduces a new algorithm called Stateful Value Factorization (SVF) for multi-agent reinforcement learning. SVF learns a compact, factorized representation of each agent's value function that captures the dependencies between the agent's local state and the joint state of all agents.
The authors demonstrate that SVF outperforms other state-of-the-art multi-agent reinforcement learning algorithms on a variety of benchmark tasks, suggesting that the factorized representation can lead to improved sample efficiency and scalability. This work represents an important step towards developing more scalable and sample-efficient multi-agent reinforcement learning algorithms, which could have significant implications for a wide range of real-world applications involving multiple autonomous agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On Stateful Value Factorization in Multi-Agent Reinforcement Learning
Enrico Marchesini, Andrea Baisero, Rupali Bhati, Christopher Amato
Value factorization is a popular paradigm for designing scalable multi-agent reinforcement learning algorithms. However, current factorization methods make choices without full justification that may limit their performance. For example, the theory in prior work uses stateless (i.e., history) functions, while the practical implementations use state information -- making the motivating theory a mismatch for the implementation. Also, methods have built off of previous approaches, inheriting their architectures without exploring other, potentially better ones. To address these concerns, we formally analyze the theory of using the state instead of the history in current methods -- reconnecting theory and practice. We then introduce DuelMIX, a factorization algorithm that learns distinct per-agent utility estimators to improve performance and achieve full expressiveness. Experiments on StarCraft II micromanagement and Box Pushing tasks demonstrate the benefits of our intuitions.
Read more9/11/2024
🤿
0
Dynamic Deep Factor Graph for Multi-Agent Reinforcement Learning
Yuchen Shi, Shihong Duan, Cheng Xu, Ran Wang, Fangwen Ye, Chau Yuen
This work introduces a novel value decomposition algorithm, termed textit{Dynamic Deep Factor Graphs} (DDFG). Unlike traditional coordination graphs, DDFG leverages factor graphs to articulate the decomposition of value functions, offering enhanced flexibility and adaptability to complex value function structures. Central to DDFG is a graph structure generation policy that innovatively generates factor graph structures on-the-fly, effectively addressing the dynamic collaboration requirements among agents. DDFG strikes an optimal balance between the computational overhead associated with aggregating value functions and the performance degradation inherent in their complete decomposition. Through the application of the max-sum algorithm, DDFG efficiently identifies optimal policies. We empirically validate DDFG's efficacy in complex scenarios, including higher-order predator-prey tasks and the StarCraft II Multi-agent Challenge (SMAC), thus underscoring its capability to surmount the limitations faced by existing value decomposition algorithms. DDFG emerges as a robust solution for MARL challenges that demand nuanced understanding and facilitation of dynamic agent collaboration. The implementation of DDFG is made publicly accessible, with the source code available at url{https://github.com/SICC-Group/DDFG}.
Read more6/10/2024

0
POWQMIX: Weighted Value Factorization with Potentially Optimal Joint Actions Recognition for Cooperative Multi-Agent Reinforcement Learning
Chang Huang, Junqiao Zhao, Shatong Zhu, Hongtu Zhou, Chen Ye, Tiantian Feng, Changjun Jiang
Value function factorization methods are commonly used in cooperative multi-agent reinforcement learning, with QMIX receiving significant attention. Many QMIX-based methods introduce monotonicity constraints between the joint action value and individual action values to achieve decentralized execution. However, such constraints limit the representation capacity of value factorization, restricting the joint action values it can represent and hindering the learning of the optimal policy. To address this challenge, we propose the Potentially Optimal joint actions Weighted QMIX (POWQMIX) algorithm, which recognizes the potentially optimal joint actions and assigns higher weights to the corresponding losses of these joint actions during training. We theoretically prove that with such a weighted training approach the optimal policy is guaranteed to be recovered. Experiments in matrix games, predator-prey, and StarCraft II Multi-Agent Challenge environments demonstrate that our algorithm outperforms the state-of-the-art value-based multi-agent reinforcement learning methods.
Read more5/16/2024

0
New!Curricula for Learning Robust Policies over Factored State Representations in Changing Environments
Panayiotis Panayiotou, Ozgur c{S}imc{s}ek
Robust policies enable reinforcement learning agents to effectively adapt to and operate in unpredictable, dynamic, and ever-changing real-world environments. Factored representations, which break down complex state and action spaces into distinct components, can improve generalization and sample efficiency in policy learning. In this paper, we explore how the curriculum of an agent using a factored state representation affects the robustness of the learned policy. We experimentally demonstrate three simple curricula, such as varying only the variable of highest regret between episodes, that can significantly enhance policy robustness, offering practical insights for reinforcement learning in complex environments.
Read more9/17/2024