POWQMIX: Weighted Value Factorization with Potentially Optimal Joint Actions Recognition for Cooperative Multi-Agent Reinforcement Learning

0

Sign in to get full access
Overview
- This paper proposes a new algorithm called POWQMIX for cooperative multi-agent reinforcement learning.
- The key ideas are: 1) a weighted value factorization method to learn individual agent values, and 2) a mechanism to recognize potentially optimal joint actions.
- The goal is to improve coordination and learning efficiency in cooperative multi-agent settings.
Plain English Explanation
The paper presents a new approach called POWQMIX for training multiple AI agents to work together effectively. In many real-world applications, such as robot teams or video game characters, we want multiple autonomous agents to cooperate and perform tasks as a group.
Link to Diverse Randomized Value Functions: A Provably Pessimistic Approach for Learning Cooperative Behaviors This is a challenge because each agent needs to learn how to act in a way that benefits the whole team, not just themselves.
POWQMIX tackles this in two key ways. First, it uses a "weighted value factorization" method to help each agent learn its own value function, which represents how good its individual actions are for the team. This allows the agents to focus on their specific roles and responsibilities.
Second, POWQMIX includes a mechanism to recognize when the agents' individual actions could potentially form an optimal joint action for the whole team. This helps the agents coordinate better and make decisions that benefit the group, rather than just pursuing their own interests.
The goal of these innovations is to improve the speed and effectiveness of training cooperative multi-agent systems, so they can learn to work together more efficiently.
Technical Explanation
The paper introduces a new algorithm called POWQMIX (Potentially Optimal Joint Action Recognition with Weighted Value Factorization for Cooperative Multi-Agent Reinforcement Learning).
Link to Equivariant Deep Learning for Mixed-Integer Optimal Control POWQMIX builds upon the QMIX algorithm, which is a popular method for learning decentralized policies in cooperative multi-agent settings. The key innovations in POWQMIX are:
-
Weighted Value Factorization: Instead of learning a single joint action-value function, POWQMIX learns individual value functions for each agent and combines them using a weighted summation. This allows each agent to focus on learning its own role and responsibilities within the team.
-
Potentially Optimal Joint Action Recognition: POWQMIX introduces a module that analyzes the individual agent values to identify potentially optimal joint actions. This helps the agents coordinate their decisions to achieve better team performance.
The paper evaluates POWQMIX on several benchmark cooperative multi-agent environments and shows that it outperforms previous state-of-the-art algorithms in terms of sample efficiency and final performance.
Link to Multi-Objective Recommendation via Multivariate Policy Learning The experiments demonstrate that the weighted value factorization and joint action recognition mechanisms in POWQMIX enable the agents to learn more effective cooperative strategies compared to other decentralized approaches.
Critical Analysis
The paper presents a compelling approach for improving coordination and learning in cooperative multi-agent reinforcement learning. The key ideas of weighted value factorization and potentially optimal joint action recognition seem well-justified and the experimental results are promising.
Link to LOQA: Learning Opponent Q-Learning Awareness However, the paper does not extensively discuss the limitations or potential drawbacks of the POWQMIX algorithm. For example, it is not clear how the method would scale to larger teams of agents or more complex environments.
Link to ROMA-IQSS: Objective Alignment Approach via State Space Additionally, the paper does not provide much analysis on the computational complexity or training time required for POWQMIX compared to other algorithms. These are important practical considerations when deploying such systems in real-world applications.
Overall, the research presented in this paper represents a valuable contribution to the field of cooperative multi-agent reinforcement learning. The proposed techniques appear to be effective, but further investigation into the limitations and scalability of the approach would be beneficial.
Conclusion
The POWQMIX algorithm introduces innovative methods for improving coordination and learning efficiency in cooperative multi-agent reinforcement learning. By using weighted value factorization and potentially optimal joint action recognition, the approach allows individual agents to focus on their own responsibilities while also considering the overall team objective.
The experimental results demonstrate that POWQMIX outperforms previous state-of-the-art algorithms on several benchmark tasks. This suggests that the proposed techniques can enable AI agents to learn more effective cooperative strategies, which has important implications for real-world applications like robotics, autonomous vehicles, and multi-player games.
While the paper does not extensively discuss the limitations of POWQMIX, the core ideas presented represent a valuable contribution to the field. Further research into scaling the approach and analyzing its practical tradeoffs would help to fully understand its potential impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
POWQMIX: Weighted Value Factorization with Potentially Optimal Joint Actions Recognition for Cooperative Multi-Agent Reinforcement Learning
Chang Huang, Junqiao Zhao, Shatong Zhu, Hongtu Zhou, Chen Ye, Tiantian Feng, Changjun Jiang
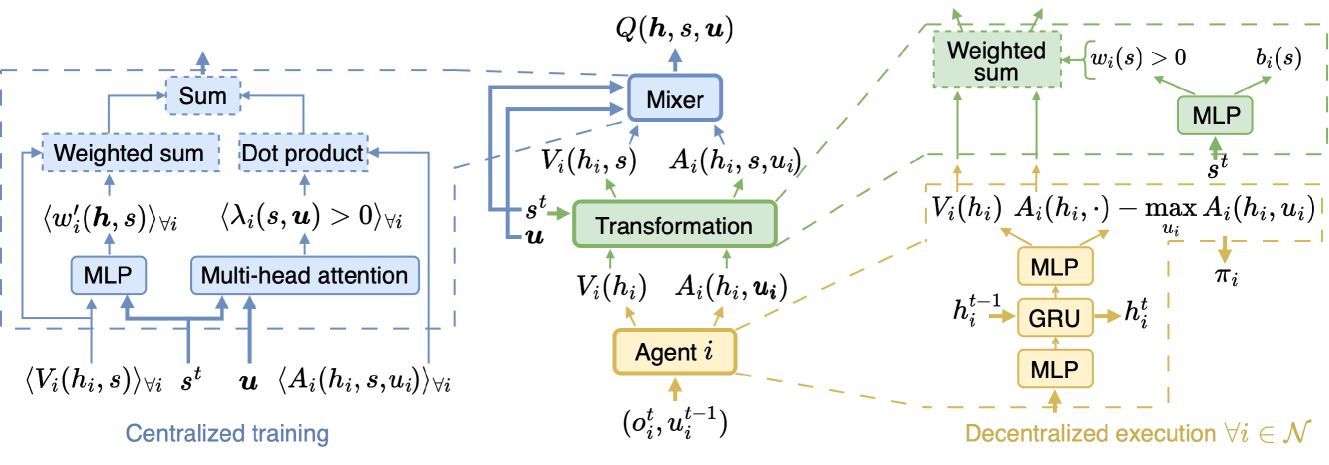
Value function factorization methods are commonly used in cooperative multi-agent reinforcement learning, with QMIX receiving significant attention. Many QMIX-based methods introduce monotonicity constraints between the joint action value and individual action values to achieve decentralized execution. However, such constraints limit the representation capacity of value factorization, restricting the joint action values it can represent and hindering the learning of the optimal policy. To address this challenge, we propose the Potentially Optimal joint actions Weighted QMIX (POWQMIX) algorithm, which recognizes the potentially optimal joint actions and assigns higher weights to the corresponding losses of these joint actions during training. We theoretically prove that with such a weighted training approach the optimal policy is guaranteed to be recovered. Experiments in matrix games, predator-prey, and StarCraft II Multi-Agent Challenge environments demonstrate that our algorithm outperforms the state-of-the-art value-based multi-agent reinforcement learning methods.
Read more5/16/2024

0
Soft-QMIX: Integrating Maximum Entropy For Monotonic Value Function Factorization
Wentse Chen, Shiyu Huang, Jeff Schneider
Multi-agent reinforcement learning (MARL) tasks often utilize a centralized training with decentralized execution (CTDE) framework. QMIX is a successful CTDE method that learns a credit assignment function to derive local value functions from a global value function, defining a deterministic local policy. However, QMIX is hindered by its poor exploration strategy. While maximum entropy reinforcement learning (RL) promotes better exploration through stochastic policies, QMIX's process of credit assignment conflicts with the maximum entropy objective and the decentralized execution requirement, making it unsuitable for maximum entropy RL. In this paper, we propose an enhancement to QMIX by incorporating an additional local Q-value learning method within the maximum entropy RL framework. Our approach constrains the local Q-value estimates to maintain the correct ordering of all actions. Due to the monotonicity of the QMIX value function, these updates ensure that locally optimal actions align with globally optimal actions. We theoretically prove the monotonic improvement and convergence of our method to an optimal solution. Experimentally, we validate our algorithm in matrix games, Multi-Agent Particle Environment and demonstrate state-of-the-art performance in SMAC-v2.
Read more6/21/2024
0
On Stateful Value Factorization in Multi-Agent Reinforcement Learning
Enrico Marchesini, Andrea Baisero, Rupali Bhati, Christopher Amato
Value factorization is a popular paradigm for designing scalable multi-agent reinforcement learning algorithms. However, current factorization methods make choices without full justification that may limit their performance. For example, the theory in prior work uses stateless (i.e., history) functions, while the practical implementations use state information -- making the motivating theory a mismatch for the implementation. Also, methods have built off of previous approaches, inheriting their architectures without exploring other, potentially better ones. To address these concerns, we formally analyze the theory of using the state instead of the history in current methods -- reconnecting theory and practice. We then introduce DuelMIX, a factorization algorithm that learns distinct per-agent utility estimators to improve performance and achieve full expressiveness. Experiments on StarCraft II micromanagement and Box Pushing tasks demonstrate the benefits of our intuitions.
Read more9/11/2024
0
QTypeMix: Enhancing Multi-Agent Cooperative Strategies through Heterogeneous and Homogeneous Value Decomposition
Songchen Fu, Shaojing Zhao, Ta Li, YongHong Yan
In multi-agent cooperative tasks, the presence of heterogeneous agents is familiar. Compared to cooperation among homogeneous agents, collaboration requires considering the best-suited sub-tasks for each agent. However, the operation of multi-agent systems often involves a large amount of complex interaction information, making it more challenging to learn heterogeneous strategies. Related multi-agent reinforcement learning methods sometimes use grouping mechanisms to form smaller cooperative groups or leverage prior domain knowledge to learn strategies for different roles. In contrast, agents should learn deeper role features without relying on additional information. Therefore, we propose QTypeMix, which divides the value decomposition process into homogeneous and heterogeneous stages. QTypeMix learns to extract type features from local historical observations through the TE loss. In addition, we introduce advanced network structures containing attention mechanisms and hypernets to enhance the representation capability and achieve the value decomposition process. The results of testing the proposed method on 14 maps from SMAC and SMACv2 show that QTypeMix achieves state-of-the-art performance in tasks of varying difficulty.
Read more8/15/2024