On Statistical Rates and Provably Efficient Criteria of Latent Diffusion Transformers (DiTs)

0
🚀
Sign in to get full access
Overview
• This paper introduces several novel techniques for improving the performance and efficiency of diffusion-based text-to-speech (TTS) models.
• The key contributions include TerDiT, a ternary diffusion model with transformers, U-DiTS, a U-shaped diffusion model that downsamples tokens, DiTTo, an efficient and scalable zero-shot TTS model, and HQ-DiT, a high-quality diffusion transformer model that uses a hybrid FP4 format.
Plain English Explanation
The paper describes several innovations in the field of text-to-speech (TTS) technology, which is the process of converting written text into human-like speech. The researchers have developed new techniques to make TTS models more efficient, scalable, and capable of producing higher-quality speech.
One key contribution is TerDiT, which uses a ternary (three-state) diffusion process along with transformer models to improve the performance of TTS. Diffusion models are a type of machine learning technique that can generate realistic-sounding speech by gradually adding and then removing noise from an input signal.
Another innovation is U-DiTS, which uses a "U-shaped" diffusion process to downsample the input text tokens, making the model more efficient and able to handle longer sequences.
The paper also introduces DiTTo, a TTS model that can generate speech for any text input, even if it hasn't been seen during training. This "zero-shot" capability makes the model more versatile and scalable.
Finally, the researchers developed HQ-DiT, a high-quality diffusion transformer model that uses a hybrid FP4 (four-bit floating-point) format to reduce the computational resources required without sacrificing speech quality.
Overall, these innovations represent significant advancements in the field of TTS, paving the way for more efficient, scalable, and high-quality speech synthesis applications.
Technical Explanation
The paper introduces several novel techniques for improving the performance and efficiency of diffusion-based text-to-speech (TTS) models:
-
TerDiT: The researchers propose a ternary diffusion model that uses transformers to better capture the complex dependencies in speech data. Ternary diffusion models, which have three possible states for each token, are shown to outperform standard binary diffusion models.
-
U-DiTS: This model uses a U-shaped diffusion process to downsample the input text tokens, reducing the computational complexity while maintaining the model's ability to generate high-quality speech. The U-shaped structure allows the model to efficiently capture both local and global information in the input sequence.
-
DiTTo: The researchers develop a zero-shot TTS model that can generate speech for any text input, even if it hasn't been seen during training. This makes the model more efficient and scalable, as it can be applied to a wide range of text without the need for additional fine-tuning.
-
HQ-DiT: This high-quality diffusion transformer model uses a hybrid FP4 (four-bit floating-point) format to reduce the computational resources required without compromising the quality of the generated speech. The FP4 format allows for more efficient hardware implementation while maintaining the model's expressive power.
The paper presents extensive experiments and comparisons with state-of-the-art TTS models, demonstrating the superior performance and efficiency of the proposed techniques across various metrics, including speech quality, inference time, and memory usage.
Critical Analysis
The paper presents a comprehensive set of innovations that address key challenges in diffusion-based TTS models. The researchers have thoughtfully designed each technique to improve different aspects of the model, such as performance, efficiency, and scalability.
One potential concern is the computational complexity of the proposed models, particularly with the introduction of ternary diffusion and the U-shaped structure. While the paper claims these techniques improve efficiency, it would be helpful to see a more detailed analysis of the computational and memory requirements of the models, especially in comparison to simpler diffusion-based TTS approaches.
Additionally, the paper does not provide much discussion on the potential limitations or failure cases of the proposed models. It would be valuable to understand the types of inputs or scenarios where the models may struggle or produce lower-quality speech, as well as any potential biases or ethical considerations that may arise.
Overall, the paper presents a significant contribution to the field of TTS, with a solid technical foundation and a clear focus on improving the practical applicability of diffusion-based models. Further research and real-world deployment of these techniques could lead to substantial advancements in speech synthesis technology.
Conclusion
This paper introduces several innovative techniques that significantly advance the field of text-to-speech (TTS) technology. The researchers have developed novel diffusion-based models, including TerDiT, U-DiTS, DiTTo, and HQ-DiT, that demonstrate improved performance, efficiency, and scalability compared to previous approaches.
These innovations have the potential to enable more accessible, high-quality, and cost-effective speech synthesis applications, with a wide range of use cases in areas such as virtual assistants, audio books, and language learning. The researchers have made significant strides in addressing the challenges of computational complexity and resource requirements, paving the way for more widespread adoption of advanced TTS technologies.
While the paper presents a strong technical foundation, further research is needed to fully understand the limitations and potential ethical considerations of these models. Nonetheless, the work described in this paper represents an important milestone in the ongoing progress of text-to-speech technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
On Statistical Rates and Provably Efficient Criteria of Latent Diffusion Transformers (DiTs)
Jerry Yao-Chieh Hu, Weimin Wu, Zhao Song, Han Liu
We investigate the statistical and computational limits of latent textbf{Di}ffusion textbf{T}ransformers (textbf{DiT}s) under the low-dimensional linear latent space assumption. Statistically, we study the universal approximation and sample complexity of the DiTs score function, as well as the distribution recovery property of the initial data. Specifically, under mild data assumptions, we derive an approximation error bound for the score network of latent DiTs, which is sub-linear in the latent space dimension. Additionally, we derive the corresponding sample complexity bound and show that the data distribution generated from the estimated score function converges toward a proximate area of the original one. Computationally, we characterize the hardness of both forward inference and backward computation of latent DiTs, assuming the Strong Exponential Time Hypothesis (SETH). For forward inference, we identify efficient criteria for all possible latent DiTs inference algorithms and showcase our theory by pushing the efficiency toward almost-linear time inference. For backward computation, we leverage the low-rank structure within the gradient computation of DiTs training for possible algorithmic speedup. Specifically, we show that such speedup achieves almost-linear time latent DiTs training by casting the DiTs gradient as a series of chained low-rank approximations with bounded error. Under the low-dimensional assumption, we show that the convergence rate and the computational efficiency are both dominated by the dimension of the subspace, suggesting that latent DiTs have the potential to bypass the challenges associated with the high dimensionality of initial data.
Read more8/23/2024
🌐
0
TerDiT: Ternary Diffusion Models with Transformers
Xudong Lu, Aojun Zhou, Ziyi Lin, Qi Liu, Yuhui Xu, Renrui Zhang, Yafei Wen, Shuai Ren, Peng Gao, Junchi Yan, Hongsheng Li
Recent developments in large-scale pre-trained text-to-image diffusion models have significantly improved the generation of high-fidelity images, particularly with the emergence of diffusion models based on transformer architecture (DiTs). Among these diffusion models, diffusion transformers have demonstrated superior image generation capabilities, boosting lower FID scores and higher scalability. However, deploying large-scale DiT models can be expensive due to their extensive parameter numbers. Although existing research has explored efficient deployment techniques for diffusion models such as model quantization, there is still little work concerning DiT-based models. To tackle this research gap, in this paper, we propose TerDiT, a quantization-aware training (QAT) and efficient deployment scheme for ternary diffusion models with transformers. We focus on the ternarization of DiT networks and scale model sizes from 600M to 4.2B. Our work contributes to the exploration of efficient deployment strategies for large-scale DiT models, demonstrating the feasibility of training extremely low-bit diffusion transformer models from scratch while maintaining competitive image generation capacities compared to full-precision models. Code will be available at https://github.com/Lucky-Lance/TerDiT.
Read more5/24/2024

0
TimeDiT: General-purpose Diffusion Transformers for Time Series Foundation Model
Defu Cao, Wen Ye, Yizhou Zhang, Yan Liu
With recent advances in building foundation models for texts and video data, there is a surge of interest in foundation models for time series. A family of models have been developed, utilizing a temporal auto-regressive generative Transformer architecture, whose effectiveness has been proven in Large Language Models. While the empirical results are promising, almost all existing time series foundation models have only been tested on well-curated ``benchmark'' datasets very similar to texts. However, real-world time series exhibit unique challenges, such as variable channel sizes across domains, missing values, and varying signal sampling intervals due to the multi-resolution nature of real-world data. Additionally, the uni-directional nature of temporally auto-regressive decoding limits the incorporation of domain knowledge, such as physical laws expressed as partial differential equations (PDEs). To address these challenges, we introduce the Time Diffusion Transformer (TimeDiT), a general foundation model for time series that employs a denoising diffusion paradigm instead of temporal auto-regressive generation. TimeDiT leverages the Transformer architecture to capture temporal dependencies and employs diffusion processes to generate high-quality candidate samples without imposing stringent assumptions on the target distribution via novel masking schemes and a channel alignment strategy. Furthermore, we propose a finetuning-free model editing strategy that allows the seamless integration of external knowledge during the sampling process without updating any model parameters. Extensive experiments conducted on a varity of tasks such as forecasting, imputation, and anomaly detection, demonstrate the effectiveness of TimeDiT.
Read more9/5/2024
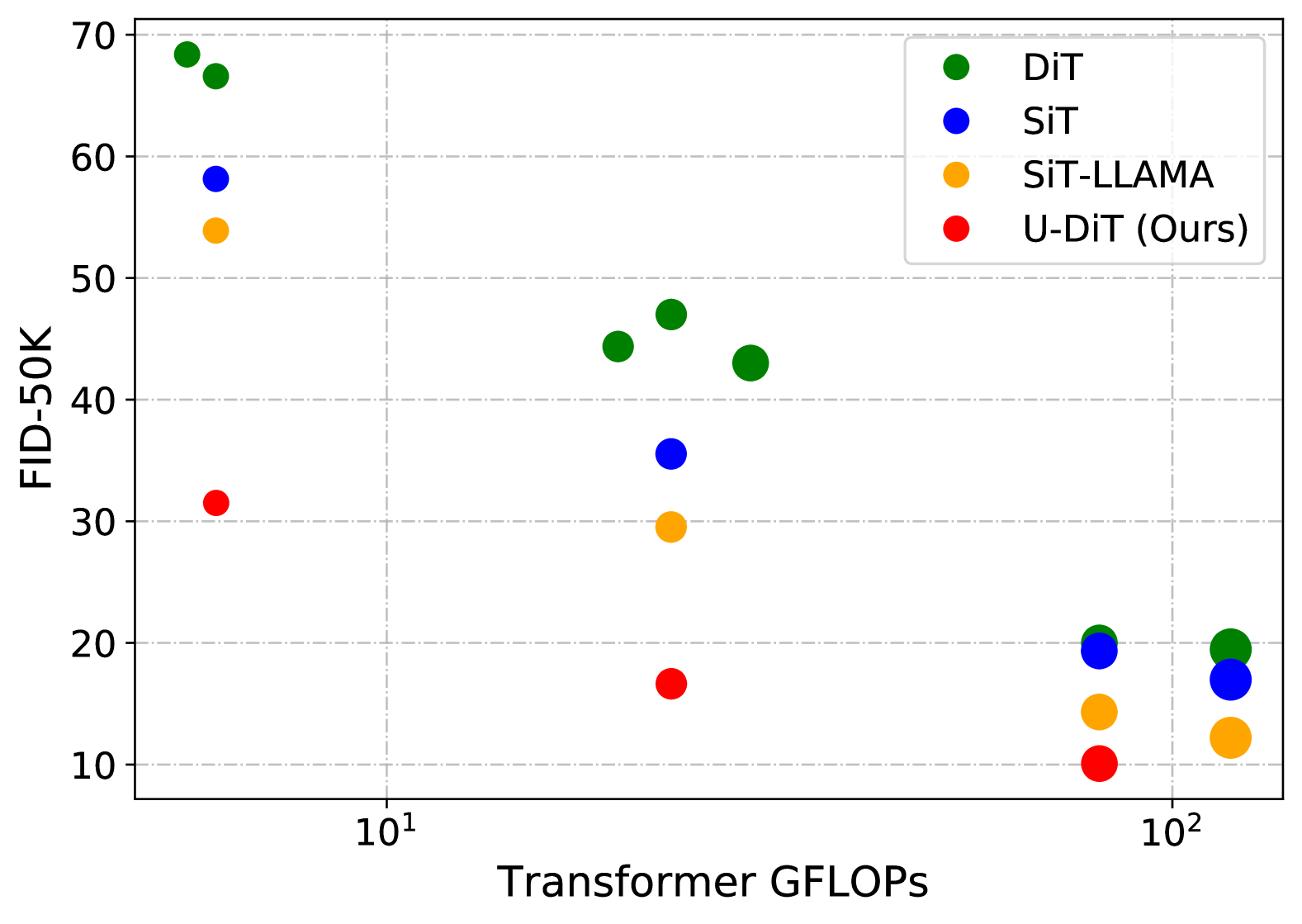
0
U-DiTs: Downsample Tokens in U-Shaped Diffusion Transformers
Yuchuan Tian, Zhijun Tu, Hanting Chen, Jie Hu, Chao Xu, Yunhe Wang
Diffusion Transformers (DiTs) introduce the transformer architecture to diffusion tasks for latent-space image generation. With an isotropic architecture that chains a series of transformer blocks, DiTs demonstrate competitive performance and good scalability; but meanwhile, the abandonment of U-Net by DiTs and their following improvements is worth rethinking. To this end, we conduct a simple toy experiment by comparing a U-Net architectured DiT with an isotropic one. It turns out that the U-Net architecture only gain a slight advantage amid the U-Net inductive bias, indicating potential redundancies within the U-Net-style DiT. Inspired by the discovery that U-Net backbone features are low-frequency-dominated, we perform token downsampling on the query-key-value tuple for self-attention that bring further improvements despite a considerable amount of reduction in computation. Based on self-attention with downsampled tokens, we propose a series of U-shaped DiTs (U-DiTs) in the paper and conduct extensive experiments to demonstrate the extraordinary performance of U-DiT models. The proposed U-DiT could outperform DiT-XL/2 with only 1/6 of its computation cost. Codes are available at https://github.com/YuchuanTian/U-DiT.
Read more6/4/2024