DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer
2406.11427
0
66

Abstract
Large-scale diffusion models have shown outstanding generative abilities across multiple modalities including images, videos, and audio. However, text-to-speech (TTS) systems typically involve domain-specific modeling factors (e.g., phonemes and phoneme-level durations) to ensure precise temporal alignments between text and speech, which hinders the efficiency and scalability of diffusion models for TTS. In this work, we present an efficient and scalable Diffusion Transformer (DiT) that utilizes off-the-shelf pre-trained text and speech encoders. Our approach addresses the challenge of text-speech alignment via cross-attention mechanisms with the prediction of the total length of speech representations. To achieve this, we enhance the DiT architecture to suit TTS and improve the alignment by incorporating semantic guidance into the latent space of speech. We scale the training dataset and the model size to 82K hours and 790M parameters, respectively. Our extensive experiments demonstrate that the large-scale diffusion model for TTS without domain-specific modeling not only simplifies the training pipeline but also yields superior or comparable zero-shot performance to state-of-the-art TTS models in terms of naturalness, intelligibility, and speaker similarity. Our speech samples are available at https://ditto-tts.github.io.
Create account to get full access
Overview
- This paper presents DiTTo-TTS, an efficient and scalable zero-shot text-to-speech (TTS) system that uses a diffusion transformer model.
- DiTTo-TTS can generate high-quality speech in multiple languages without being trained on any audio data, making it a promising approach for low-resource languages.
- The model leverages recent advancements in diffusion models and transformer architectures to achieve state-of-the-art performance on zero-shot TTS benchmarks.
Plain English Explanation
DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer is a new text-to-speech (TTS) system that can generate high-quality speech in multiple languages without requiring any audio data for training. This is known as "zero-shot" TTS, and it's an important capability for creating TTS systems for languages that have limited available data.
The key innovation in DiTTo-TTS is the use of a diffusion transformer model, which combines recent advancements in diffusion models and transformer architectures. Diffusion models are a type of generative model that can create new data by gradually adding noise to a clean input and then learning to reverse the process. Transformers are a powerful neural network architecture that excel at processing sequential data like text.
By bringing these two techniques together, the researchers were able to create a TTS system that is both efficient and scalable. It can generate high-quality speech across many languages without needing to be trained on audio recordings for each one. This makes DiTTo-TTS a promising approach for building TTS systems for low-resource languages, where audio data may be scarce.
Technical Explanation
DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer leverages recent advancements in diffusion models and transformer architectures to tackle the challenge of zero-shot text-to-speech (TTS) generation.
The core of the DiTTo-TTS model is a diffusion transformer, which consists of a text encoder based on the ViT-TTS architecture and a diffusion-based speech decoder. The text encoder maps the input text into a latent representation, which is then used by the diffusion decoder to generate the corresponding speech waveform.
The diffusion decoder is inspired by Diffusion Synthesizer, a previously proposed diffusion-based generative model for speech synthesis. It learns to iteratively add and remove noise from a random input signal to match the target speech waveform. This allows the model to generate high-quality audio without relying on autoregressive models, which can be computationally expensive.
The researchers evaluated DiTTo-TTS on several zero-shot TTS benchmarks, including the CommonVoice dataset and the VCTK corpus. They found that DiTTo-TTS outperformed previous state-of-the-art zero-shot TTS models in terms of both speech quality and inference speed. The model was also shown to be highly scalable, with the ability to generate speech in a large number of languages without retraining.
Critical Analysis
The key strength of DiTTo-TTS is its ability to generate high-quality speech in multiple languages without requiring any audio data for training. This is a significant advancement over previous zero-shot TTS approaches, which typically struggled with speech quality or were limited in the number of supported languages.
However, the paper does not provide a detailed analysis of the model's performance on low-resource languages, which is a crucial test for zero-shot TTS systems. Additionally, the authors do not discuss the potential challenges or limitations of their approach, such as the model's ability to capture fine-grained prosodic and expressive features of speech.
Further research could explore ways to improve the model's versatility and robustness, particularly for use cases with more diverse or challenging input text. Incorporating techniques like small language models with linear attention may also help to further enhance the efficiency and scalability of the DiTTo-TTS system.
Conclusion
DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer presents a promising approach to zero-shot text-to-speech generation. By leveraging diffusion models and transformer architectures, the researchers have developed a TTS system that can generate high-quality speech across multiple languages without requiring any audio data for training.
This work represents an important step forward in making text-to-speech technology more accessible and applicable to a wider range of languages and scenarios. As the field of zero-shot TTS continues to evolve, the innovations introduced in DiTTo-TTS may inspire further advancements and help to make this technology more widely available and useful for a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
ViT-TTS: Visual Text-to-Speech with Scalable Diffusion Transformer
Huadai Liu, Rongjie Huang, Xuan Lin, Wenqiang Xu, Maozong Zheng, Hong Chen, Jinzheng He, Zhou Zhao
0
0
Text-to-speech(TTS) has undergone remarkable improvements in performance, particularly with the advent of Denoising Diffusion Probabilistic Models (DDPMs). However, the perceived quality of audio depends not solely on its content, pitch, rhythm, and energy, but also on the physical environment. In this work, we propose ViT-TTS, the first visual TTS model with scalable diffusion transformers. ViT-TTS complement the phoneme sequence with the visual information to generate high-perceived audio, opening up new avenues for practical applications of AR and VR to allow a more immersive and realistic audio experience. To mitigate the data scarcity in learning visual acoustic information, we 1) introduce a self-supervised learning framework to enhance both the visual-text encoder and denoiser decoder; 2) leverage the diffusion transformer scalable in terms of parameters and capacity to learn visual scene information. Experimental results demonstrate that ViT-TTS achieves new state-of-the-art results, outperforming cascaded systems and other baselines regardless of the visibility of the scene. With low-resource data (1h, 2h, 5h), ViT-TTS achieves comparative results with rich-resource baselines.~footnote{Audio samples are available at url{https://ViT-TTS.github.io/.}}
4/23/2024
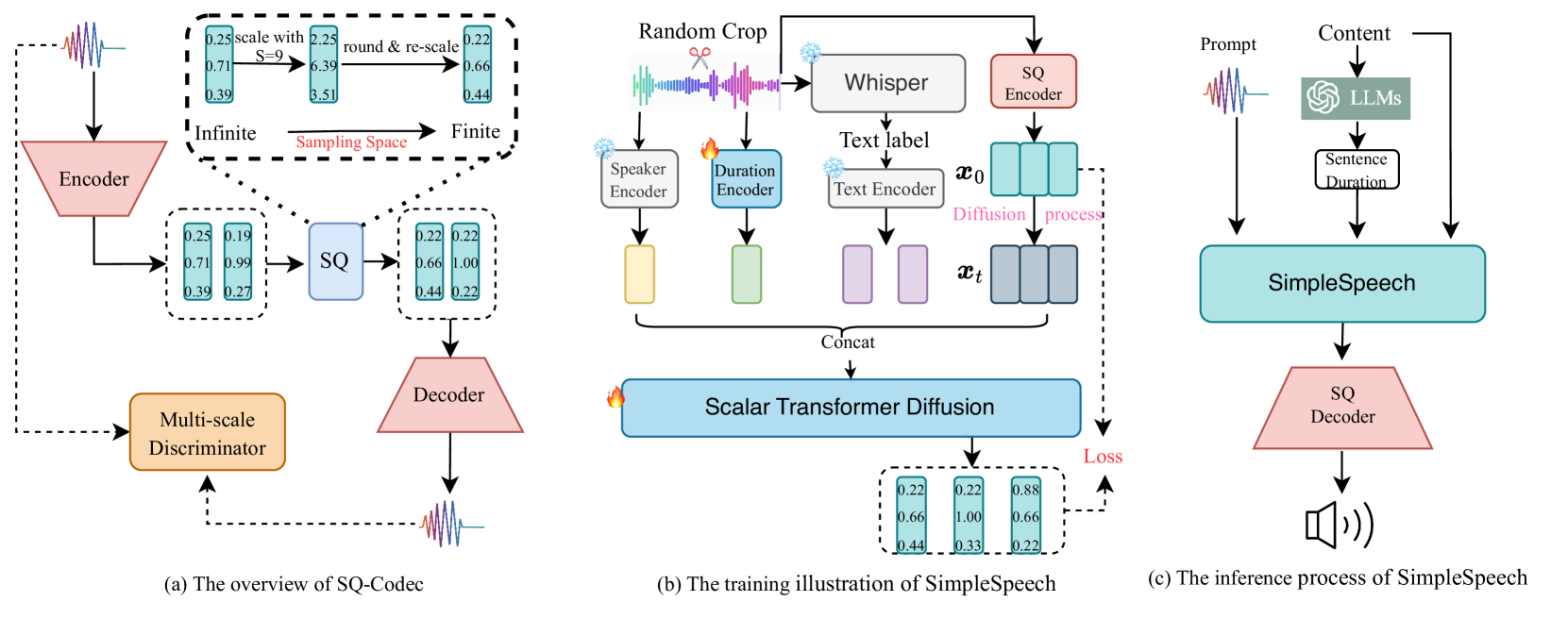
SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models
Dongchao Yang, Dingdong Wang, Haohan Guo, Xueyuan Chen, Xixin Wu, Helen Meng
0
0
In this study, we propose a simple and efficient Non-Autoregressive (NAR) text-to-speech (TTS) system based on diffusion, named SimpleSpeech. Its simpleness shows in three aspects: (1) It can be trained on the speech-only dataset, without any alignment information; (2) It directly takes plain text as input and generates speech through an NAR way; (3) It tries to model speech in a finite and compact latent space, which alleviates the modeling difficulty of diffusion. More specifically, we propose a novel speech codec model (SQ-Codec) with scalar quantization, SQ-Codec effectively maps the complex speech signal into a finite and compact latent space, named scalar latent space. Benefits from SQ-Codec, we apply a novel transformer diffusion model in the scalar latent space of SQ-Codec. We train SimpleSpeech on 4k hours of a speech-only dataset, it shows natural prosody and voice cloning ability. Compared with previous large-scale TTS models, it presents significant speech quality and generation speed improvement. Demos are released.
6/17/2024

Autoregressive Diffusion Transformer for Text-to-Speech Synthesis
Zhijun Liu, Shuai Wang, Sho Inoue, Qibing Bai, Haizhou Li
0
0
Audio language models have recently emerged as a promising approach for various audio generation tasks, relying on audio tokenizers to encode waveforms into sequences of discrete symbols. Audio tokenization often poses a necessary compromise between code bitrate and reconstruction accuracy. When dealing with low-bitrate audio codes, language models are constrained to process only a subset of the information embedded in the audio, which in turn restricts their generative capabilities. To circumvent these issues, we propose encoding audio as vector sequences in continuous space $mathbb R^d$ and autoregressively generating these sequences using a decoder-only diffusion transformer (ARDiT). Our findings indicate that ARDiT excels in zero-shot text-to-speech and exhibits performance that compares to or even surpasses that of state-of-the-art models. High-bitrate continuous speech representation enables almost flawless reconstruction, allowing our model to achieve nearly perfect speech editing. Our experiments reveal that employing Integral Kullback-Leibler (IKL) divergence for distillation at each autoregressive step significantly boosts the perceived quality of the samples. Simultaneously, it condenses the iterative sampling process of the diffusion model into a single step. Furthermore, ARDiT can be trained to predict several continuous vectors in one step, significantly reducing latency during sampling. Impressively, one of our models can generate $170$ ms of $24$ kHz speech per evaluation step with minimal degradation in performance. Audio samples are available at http://ardit-tts.github.io/ .
6/11/2024
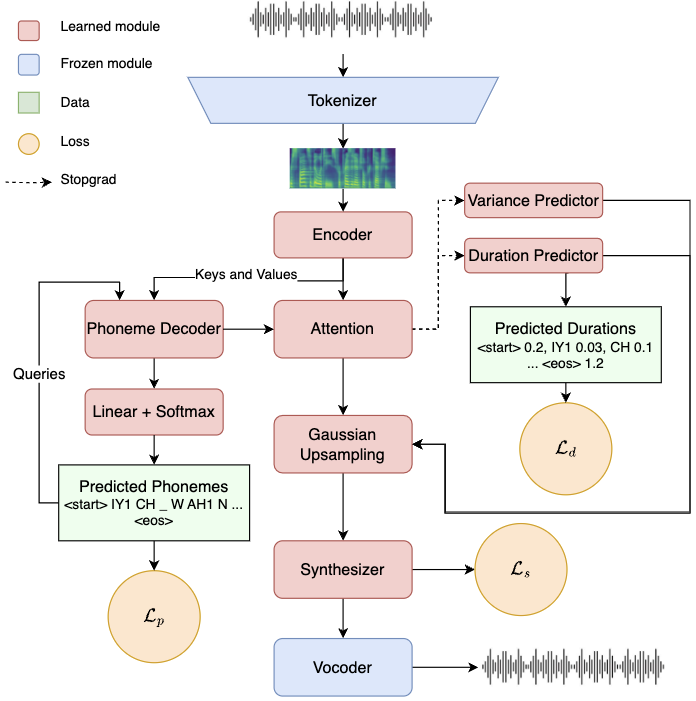
Diffusion Synthesizer for Efficient Multilingual Speech to Speech Translation
Nameer Hirschkind, Xiao Yu, Mahesh Kumar Nandwana, Joseph Liu, Eloi DuBois, Dao Le, Nicolas Thiebaut, Colin Sinclair, Kyle Spence, Charles Shang, Zoe Abrams, Morgan McGuire
0
0
We introduce DiffuseST, a low-latency, direct speech-to-speech translation system capable of preserving the input speaker's voice zero-shot while translating from multiple source languages into English. We experiment with the synthesizer component of the architecture, comparing a Tacotron-based synthesizer to a novel diffusion-based synthesizer. We find the diffusion-based synthesizer to improve MOS and PESQ audio quality metrics by 23% each and speaker similarity by 5% while maintaining comparable BLEU scores. Despite having more than double the parameter count, the diffusion synthesizer has lower latency, allowing the entire model to run more than 5$times$ faster than real-time.
6/17/2024