Steamroller Problems: An Evaluation of LLM Reasoning Capability with Automated Theorem Prover Strategies

0

Sign in to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Steamroller Problems: An Evaluation of LLM Reasoning Capability with Automated Theorem Prover Strategies
Lachlan McGinness, Peter Baumgartner
This study presents the first examination of the ability of Large Language Models (LLMs) to follow reasoning strategies that are used to guide Automated Theorem Provers (ATPs). We evaluate the performance of GPT4, GPT3.5 Turbo and Google's recent Gemini model on problems from a steamroller domain. In addition to determining accuracy we make use of the Natural Language Processing library spaCy to explore new methods of investigating LLM's reasoning capabilities. This led to one alarming result, the low correlation between correct reasoning and correct answers for any of the tested models. We found that the models' performance when using the ATP reasoning strategies was comparable to one-shot chain of thought and observe that attention to uncertainty in the accuracy results is critical when drawing conclusions about model performance. Consistent with previous speculation we confirm that LLMs have a preference for, and are best able to follow, bottom up reasoning processes. However, the reasoning strategies can still be beneficial for deriving small and relevant sets of formulas for external processing by a trusted inference engine.
Read more7/31/2024

0
Automated Theorem Provers Help Improve Large Language Model Reasoning
Lachlan McGinness, Peter Baumgartner
In this paper we demonstrate how logic programming systems and Automated first-order logic Theorem Provers (ATPs) can improve the accuracy of Large Language Models (LLMs) for logical reasoning tasks where the baseline performance is given by direct LLM solutions. We first evaluate LLM reasoning on steamroller problems using the PRONTOQA benchmark. We show how accuracy can be improved with a neuro-symbolic architecture where the LLM acts solely as a front-end for translating a given problem into a formal logic language and an automated reasoning engine is called for solving it. However, this approach critically hinges on the correctness of the LLM translation. To assess this translation correctness, we secondly define a framework of syntactic and semantic error categories. We implemented the framework and used it to identify errors that LLMs make in the benchmark domain. Based on these findings, we thirdly extended our method with capabilities for automatically correcting syntactic and semantic errors. For semantic error correction we integrate first-order logic ATPs, which is our main and novel contribution. We demonstrate that this approach reduces semantic errors significantly and further increases the accurracy of LLM logical reasoning.
Read more8/9/2024
0
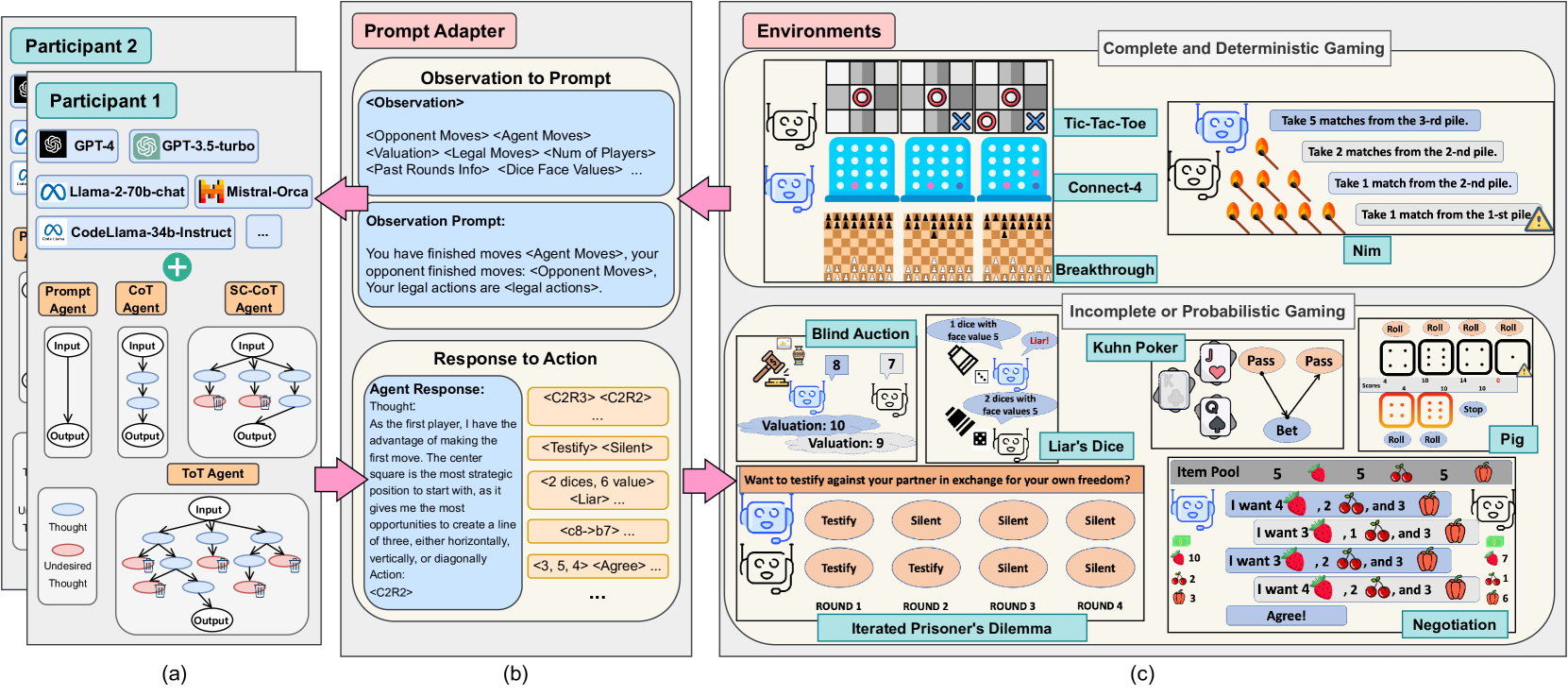
GTBench: Uncovering the Strategic Reasoning Limitations of LLMs via Game-Theoretic Evaluations
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, Kaidi Xu
As Large Language Models (LLMs) are integrated into critical real-world applications, their strategic and logical reasoning abilities are increasingly crucial. This paper evaluates LLMs' reasoning abilities in competitive environments through game-theoretic tasks, e.g., board and card games that require pure logic and strategic reasoning to compete with opponents. We first propose GTBench, a language-driven environment composing 10 widely recognized tasks, across a comprehensive game taxonomy: complete versus incomplete information, dynamic versus static, and probabilistic versus deterministic scenarios. Then, we (1) Characterize the game-theoretic reasoning of LLMs; and (2) Perform LLM-vs.-LLM competitions as reasoning evaluation. We observe that (1) LLMs have distinct behaviors regarding various gaming scenarios; for example, LLMs fail in complete and deterministic games yet they are competitive in probabilistic gaming scenarios; (2) Most open-source LLMs, e.g., CodeLlama-34b-Instruct and Llama-2-70b-chat, are less competitive than commercial LLMs, e.g., GPT-4, in complex games, yet the recently released Llama-3-70b-Instruct makes up for this shortcoming. In addition, code-pretraining greatly benefits strategic reasoning, while advanced reasoning methods such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) do not always help. We further characterize the game-theoretic properties of LLMs, such as equilibrium and Pareto Efficiency in repeated games. Detailed error profiles are provided for a better understanding of LLMs' behavior. We hope our research provides standardized protocols and serves as a foundation to spur further explorations in the strategic reasoning of LLMs.
Read more6/11/2024
0
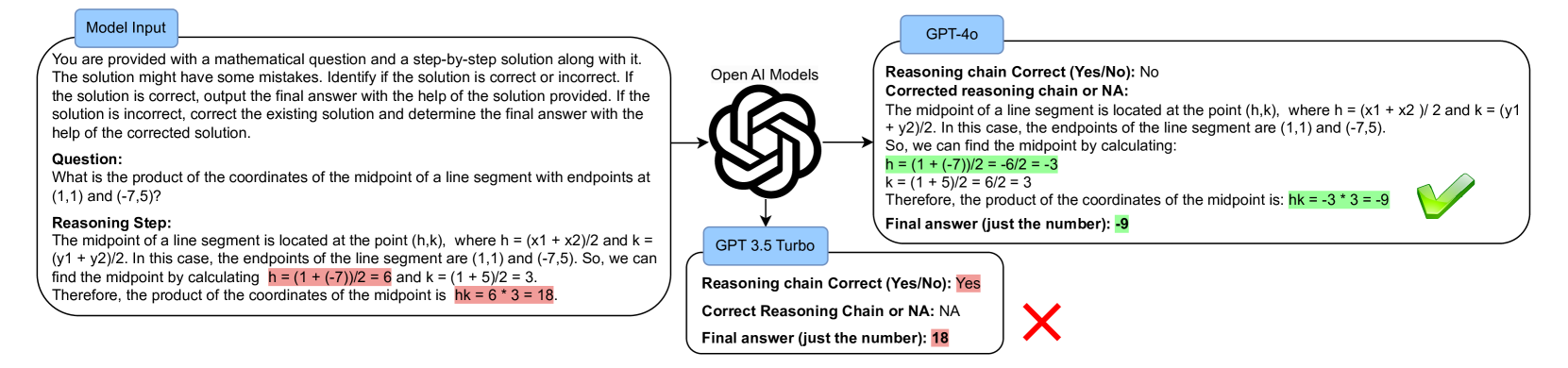
Exposing the Achilles' Heel: Evaluating LLMs Ability to Handle Mistakes in Mathematical Reasoning
Joykirat Singh, Akshay Nambi, Vibhav Vineet
Large Language Models (LLMs) have been applied to Math Word Problems (MWPs) with transformative impacts, revolutionizing how these complex problems are approached and solved in various domains including educational settings. However, the evaluation of these models often prioritizes final accuracy, overlooking the crucial aspect of reasoning capabilities. This work addresses this gap by focusing on the ability of LLMs to detect and correct reasoning mistakes. We introduce a novel dataset MWP-MISTAKE, incorporating MWPs with both correct and incorrect reasoning steps generated through rule-based methods and smaller language models. Our comprehensive benchmarking reveals significant insights into the strengths and weaknesses of state-of-the-art models, such as GPT-4o, GPT-4, GPT-3.5Turbo, and others. We highlight GPT-$o's superior performance in mistake detection and rectification and the persistent challenges faced by smaller models. Additionally, we identify issues related to data contamination and memorization, impacting the reliability of LLMs in real-world applications. Our findings emphasize the importance of rigorous evaluation of reasoning processes and propose future directions to enhance the generalization and robustness of LLMs in mathematical problem-solving.
Read more6/18/2024