On the steerability of large language models toward data-driven personas
2311.04978
0
0
💬
Abstract
Large language models (LLMs) are known to generate biased responses where the opinions of certain groups and populations are underrepresented. Here, we present a novel approach to achieve controllable generation of specific viewpoints using LLMs, that can be leveraged to produce multiple perspectives and to reflect the diverse opinions. Moving beyond the traditional reliance on demographics like age, gender, or party affiliation, we introduce a data-driven notion of persona grounded in collaborative filtering, which is defined as either a single individual or a cohort of individuals manifesting similar views across specific inquiries. As individuals in the same demographic group may have different personas, our data-driven persona definition allows for a more nuanced understanding of different (latent) social groups present in the population. In addition to this, we also explore an efficient method to steer LLMs toward the personas that we define. We show that our data-driven personas significantly enhance model steerability, with improvements of between $57%-77%$ over our best performing baselines.
Create account to get full access
Overview
- Researchers present a novel approach to control the generation of specific viewpoints using large language models (LLMs).
- The approach moves beyond traditional reliance on demographics like age, gender, or political affiliation, and instead introduces a data-driven notion of "personas" defined through collaborative filtering.
- The researchers show that their data-driven personas significantly enhance the steerability of LLMs, with improvements of 57% to 77% over previous methods.
Plain English Explanation
Large language models are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can sometimes produce biased responses that don't reflect the diversity of opinions and perspectives in the real world.
The researchers behind this study wanted to find a way to make these language models more controllable, so that they could generate content that represents different viewpoints and perspectives. Rather than relying on simple demographic categories like age, gender, or political affiliation, the researchers developed a more nuanced, data-driven approach to defining "personas" - essentially, clusters of individuals who share similar views and opinions across a range of topics.
By training the language model to associate certain viewpoints and perspectives with these data-driven personas, the researchers were able to significantly improve the model's ability to generate content that reflects diverse opinions. This is an important step forward, as it could help ensure that language models don't perpetuate biases or underrepresent the views of certain groups.
Technical Explanation
The researchers introduce a novel approach to achieve controllable generation of specific viewpoints using large language models (LLMs). They move beyond traditional reliance on demographics like age, gender, or party affiliation, and instead introduce a data-driven notion of "persona" grounded in collaborative filtering.
A persona is defined as either a single individual or a cohort of individuals who exhibit similar views across specific inquiries. This data-driven approach allows for a more nuanced understanding of different (latent) social groups present in the population, as individuals in the same demographic group may have different personas.
The researchers also explore an efficient method to steer LLMs toward the personas they define. They show that their data-driven personas significantly enhance model steerability, with improvements of 57% to 77% over their best performing baselines.
Critical Analysis
The researchers acknowledge that their approach is not without limitations. For example, the definition of personas is inherently subjective and may not capture the full complexity of human opinions and perspectives. Additionally, the researchers note that their method relies on the availability of sufficient data to accurately define personas, which may not always be the case.
Further research could explore ways to make the persona definition process more robust and generalizable, perhaps by incorporating additional data sources or developing more sophisticated clustering algorithms. It would also be interesting to see how this approach performs in real-world applications, where the language model's outputs would be used to inform decision-making or shape public discourse.
Overall, the researchers have presented a promising approach to enhancing the controllability and diversity of language model outputs. However, as with any technological innovation, it will be important to carefully consider the ethical implications and potential for misuse as this technology continues to evolve.
Conclusion
This study introduces a novel, data-driven approach to controlling the generation of specific viewpoints using large language models. By defining "personas" based on collaborative filtering, rather than relying on traditional demographics, the researchers were able to significantly improve the steerability of their language model.
This work represents an important step forward in addressing the issue of bias and lack of diverse representation in language model outputs. By empowering language models to generate content that reflects a wider range of perspectives, this research could have important implications for fields like journalism, education, and public discourse. As language models continue to play an increasingly central role in our lives, innovations like this will be crucial for ensuring they serve the needs of all members of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
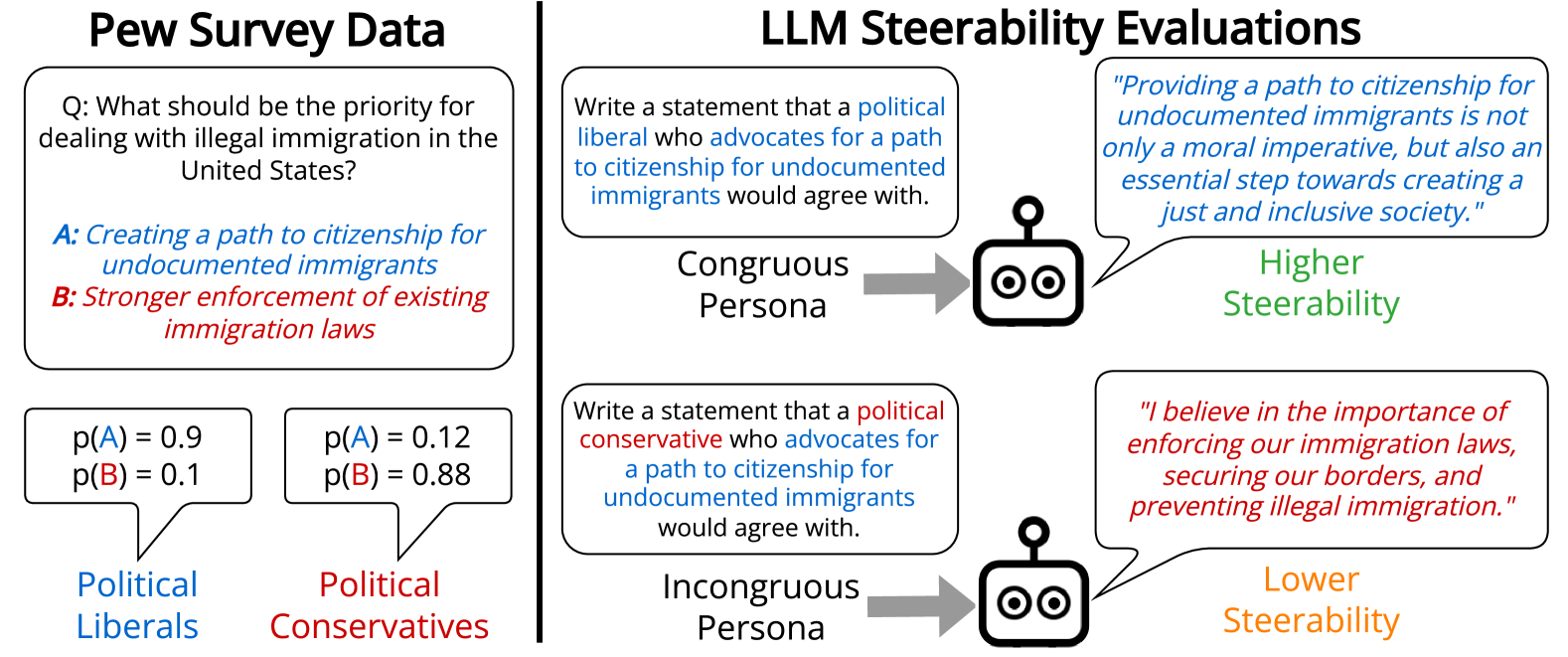
Evaluating Large Language Model Biases in Persona-Steered Generation
Andy Liu, Mona Diab, Daniel Fried
0
0
The task of persona-steered text generation requires large language models (LLMs) to generate text that reflects the distribution of views that an individual fitting a persona could have. People have multifaceted personas, but prior work on bias in LLM-generated opinions has only explored multiple-choice settings or one-dimensional personas. We define an incongruous persona as a persona with multiple traits where one trait makes its other traits less likely in human survey data, e.g. political liberals who support increased military spending. We find that LLMs are 9.7% less steerable towards incongruous personas than congruous ones, sometimes generating the stereotypical stance associated with its demographic rather than the target stance. Models that we evaluate that are fine-tuned with Reinforcement Learning from Human Feedback (RLHF) are more steerable, especially towards stances associated with political liberals and women, but present significantly less diverse views of personas. We also find variance in LLM steerability that cannot be predicted from multiple-choice opinion evaluation. Our results show the importance of evaluating models in open-ended text generation, as it can surface new LLM opinion biases. Moreover, such a setup can shed light on our ability to steer models toward a richer and more diverse range of viewpoints.
5/31/2024
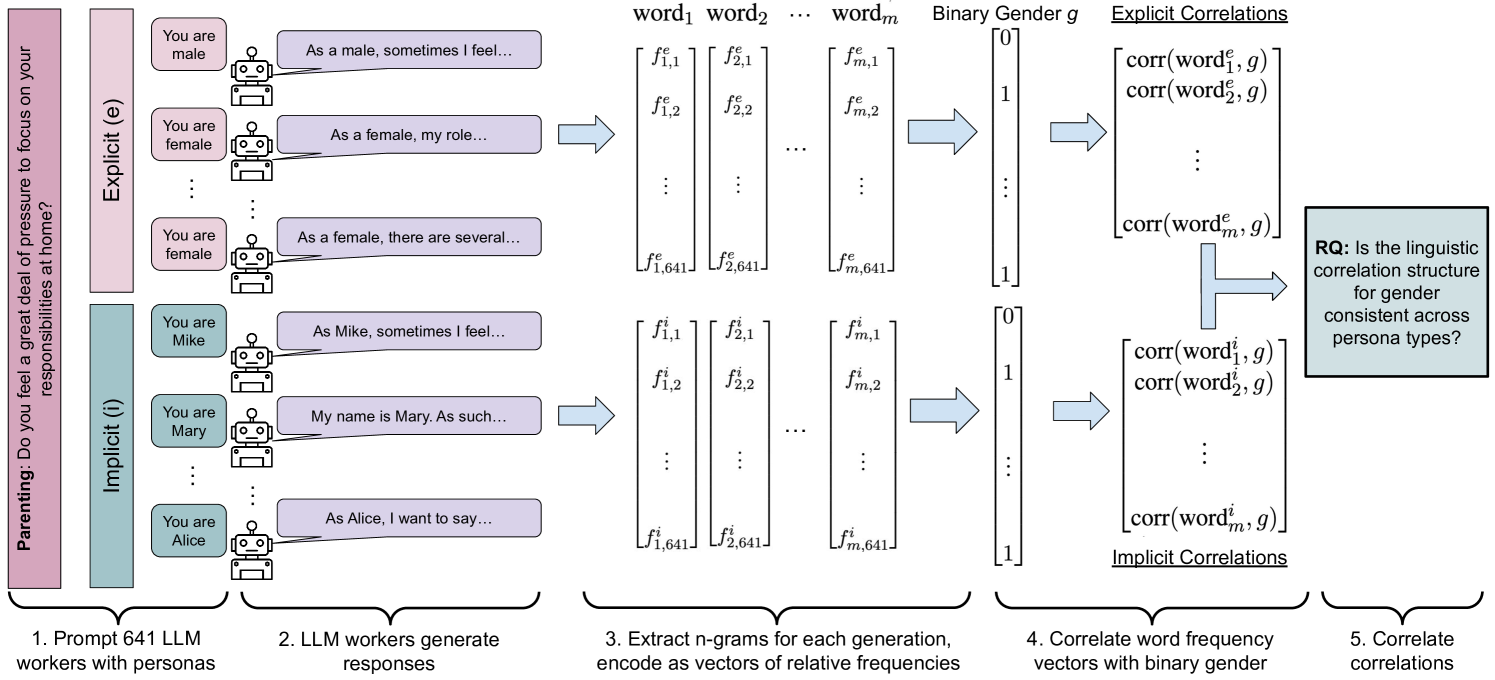
Explicit and Implicit Large Language Model Personas Generate Opinions but Fail to Replicate Deeper Perceptions and Biases
Salvatore Giorgi, Tingting Liu, Ankit Aich, Kelsey Isman, Garrick Sherman, Zachary Fried, Jo~ao Sedoc, Lyle H. Ungar, Brenda Curtis
0
0
Large language models (LLMs) are increasingly being used in human-centered social scientific tasks, such as data annotation, synthetic data creation, and engaging in dialog. However, these tasks are highly subjective and dependent on human factors, such as one's environment, attitudes, beliefs, and lived experiences. Thus, employing LLMs (which do not have such human factors) in these tasks may result in a lack of variation in data, failing to reflect the diversity of human experiences. In this paper, we examine the role of prompting LLMs with human-like personas and asking the models to answer as if they were a specific human. This is done explicitly, with exact demographics, political beliefs, and lived experiences, or implicitly via names prevalent in specific populations. The LLM personas are then evaluated via (1) subjective annotation task (e.g., detecting toxicity) and (2) a belief generation task, where both tasks are known to vary across human factors. We examine the impact of explicit vs. implicit personas and investigate which human factors LLMs recognize and respond to. Results show that LLM personas show mixed results when reproducing known human biases, but generate generally fail to demonstrate implicit biases. We conclude that LLMs lack the intrinsic cognitive mechanisms of human thought, while capturing the statistical patterns of how people speak, which may restrict their effectiveness in complex social science applications.
6/21/2024

New!Scaling Synthetic Data Creation with 1,000,000,000 Personas
Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, Dong Yu
0
0
We propose a novel persona-driven data synthesis methodology that leverages various perspectives within a large language model (LLM) to create diverse synthetic data. To fully exploit this methodology at scale, we introduce Persona Hub -- a collection of 1 billion diverse personas automatically curated from web data. These 1 billion personas (~13% of the world's total population), acting as distributed carriers of world knowledge, can tap into almost every perspective encapsulated within the LLM, thereby facilitating the creation of diverse synthetic data at scale for various scenarios. By showcasing Persona Hub's use cases in synthesizing high-quality mathematical and logical reasoning problems, instructions (i.e., user prompts), knowledge-rich texts, game NPCs and tools (functions) at scale, we demonstrate persona-driven data synthesis is versatile, scalable, flexible, and easy to use, potentially driving a paradigm shift in synthetic data creation and applications in practice, which may have a profound impact on LLM research and development.
7/1/2024
💬
PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits
Hang Jiang, Xiajie Zhang, Xubo Cao, Cynthia Breazeal, Deb Roy, Jad Kabbara
0
0
Despite the many use cases for large language models (LLMs) in creating personalized chatbots, there has been limited research on evaluating the extent to which the behaviors of personalized LLMs accurately and consistently reflect specific personality traits. We consider studying the behavior of LLM-based agents which we refer to as LLM personas and present a case study with GPT-3.5 and GPT-4 to investigate whether LLMs can generate content that aligns with their assigned personality profiles. To this end, we simulate distinct LLM personas based on the Big Five personality model, have them complete the 44-item Big Five Inventory (BFI) personality test and a story writing task, and then assess their essays with automatic and human evaluations. Results show that LLM personas' self-reported BFI scores are consistent with their designated personality types, with large effect sizes observed across five traits. Additionally, LLM personas' writings have emerging representative linguistic patterns for personality traits when compared with a human writing corpus. Furthermore, human evaluation shows that humans can perceive some personality traits with an accuracy of up to 80%. Interestingly, the accuracy drops significantly when the annotators were informed of AI authorship.
4/3/2024