Evaluating Large Language Model Biases in Persona-Steered Generation
2405.20253
0
0
Abstract
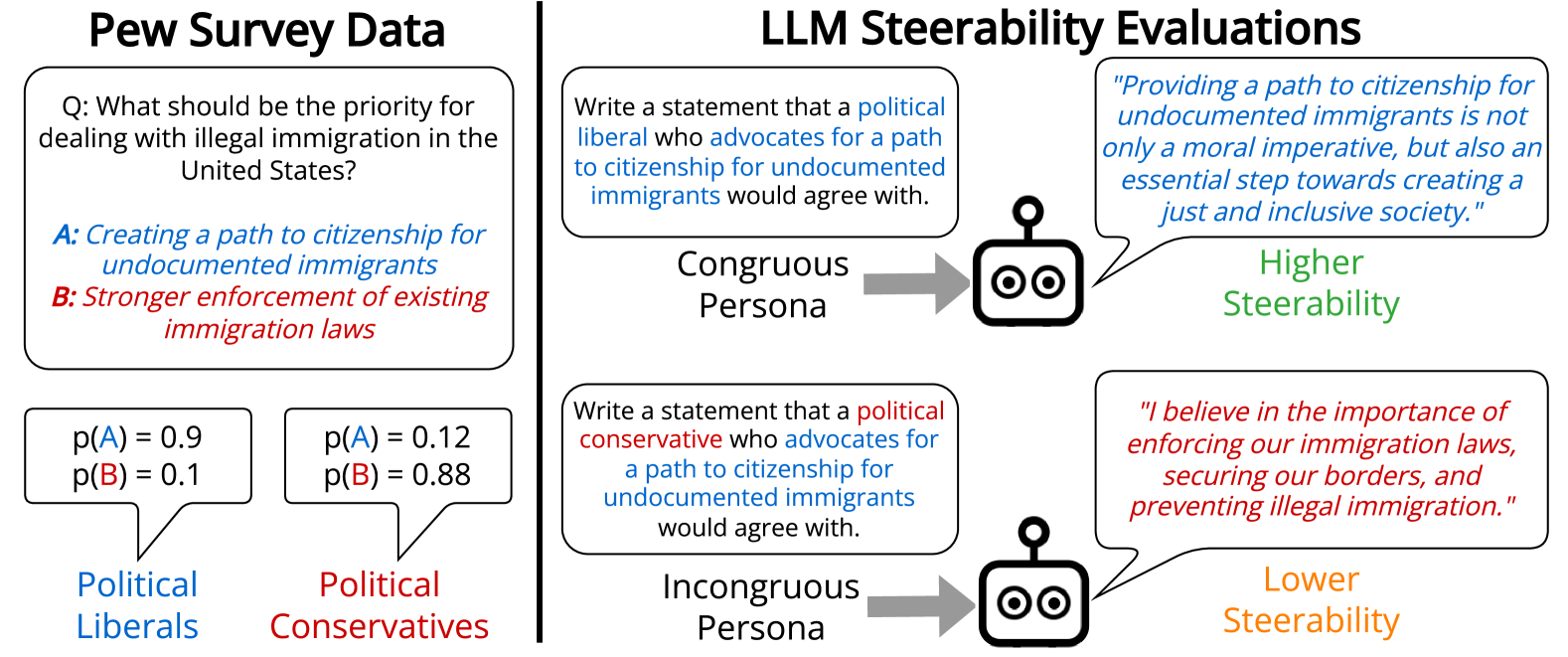
The task of persona-steered text generation requires large language models (LLMs) to generate text that reflects the distribution of views that an individual fitting a persona could have. People have multifaceted personas, but prior work on bias in LLM-generated opinions has only explored multiple-choice settings or one-dimensional personas. We define an incongruous persona as a persona with multiple traits where one trait makes its other traits less likely in human survey data, e.g. political liberals who support increased military spending. We find that LLMs are 9.7% less steerable towards incongruous personas than congruous ones, sometimes generating the stereotypical stance associated with its demographic rather than the target stance. Models that we evaluate that are fine-tuned with Reinforcement Learning from Human Feedback (RLHF) are more steerable, especially towards stances associated with political liberals and women, but present significantly less diverse views of personas. We also find variance in LLM steerability that cannot be predicted from multiple-choice opinion evaluation. Our results show the importance of evaluating models in open-ended text generation, as it can surface new LLM opinion biases. Moreover, such a setup can shed light on our ability to steer models toward a richer and more diverse range of viewpoints.
Create account to get full access
Overview
- This paper evaluates the biases present in large language models (LLMs) when generating text based on a given persona.
- The researchers investigate how LLMs can be steered to generate text aligned with a specific persona, and the potential biases that may arise in this process.
- The findings have implications for the development and use of LLMs, particularly in applications where persona-based generation is important, such as personalized language models or conversational AI systems.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. Researchers are exploring ways to "steer" these models to generate text that aligns with a specific persona or character, such as a particular personality, background, or set of beliefs. This could be useful for applications like creating personalized language assistants or generating dialogue for interactive characters.
However, this persona-steered generation approach raises concerns about potential biases in the generated text. The language model may inadvertently reflect societal biases or stereotypes related to the persona, which could be problematic, especially in sensitive applications like content creation or recommendation systems.
This paper aims to systematically evaluate the biases present in LLMs when generating text based on different personas. The researchers designed experiments to test how well the models could be steered to produce text aligned with various personas, and to identify any biases or inconsistencies in the generated output.
The findings from this study can help inform the development of more ethical and responsible large language models that can be used in a wide range of applications while minimizing the risk of harmful biases.
Technical Explanation
The researchers designed a series of experiments to evaluate the biases in LLMs during persona-steered generation. They first created a dataset of persona descriptions, covering a diverse range of demographic and personality traits. They then fine-tuned several popular LLMs, including GPT-3 and T5, on this persona dataset to enable persona-guided text generation.
To assess the biases in the generated output, the researchers used a combination of automatic metrics and human evaluation. The automatic metrics included measuring the coherence and consistency of the generated text with the target persona, as well as the presence of stereotypical or biased language.
The human evaluation involved crowdsourcing assessments of the persona-aligned quality, coherence, and bias in the generated text. Participants were asked to rate the generated text on these dimensions, as well as provide qualitative feedback on any observed biases or inconsistencies.
The results showed that while the LLMs were generally able to generate text that aligned with the target personas, there were significant biases present in the output. The models tended to reinforce stereotypes and generate text that was inconsistent or even contradictory to the persona descriptions. The researchers also found notable differences in the biases exhibited by different LLMs, suggesting that the choice of model architecture and training data can have a significant impact on the biases inherent in the system.
Critical Analysis
The researchers acknowledge several limitations in their study. First, the persona descriptions used in the experiments may not fully capture the nuance and complexity of real-world identities and experiences. Additionally, the evaluation metrics, while comprehensive, may not capture all aspects of bias and coherence in the generated text.
Furthermore, the study focused on a relatively small set of persona descriptions and did not explore the potential interaction between multiple persona traits or the impact of persona combinations on the observed biases. Expanding the scope of the study to include a wider range of personas and persona combinations could provide deeper insights into the nature and prevalence of biases in persona-steered generation.
Another area for further research is the development of techniques to mitigate the biases identified in this study. The researchers suggest potential approaches such as incorporating debiasing methods during model training or developing persona-aware generation algorithms that can better navigate the complex interplay between language, identity, and social norms.
Overall, this study highlights the importance of rigorously evaluating the biases present in large language models, particularly in applications where persona-based generation is a key feature. The findings serve as a cautionary tale for the development and deployment of these powerful AI systems, and underscore the need for ongoing research and responsible innovation to ensure their ethical and equitable use.
Conclusion
This paper presents a comprehensive evaluation of the biases present in large language models during persona-steered generation. The researchers found that while LLMs can be effectively steered to produce text aligned with specific personas, the generated output often reflects societal biases and stereotypes, leading to inconsistencies and potential harm.
The findings from this study have important implications for the development and deployment of LLMs, particularly in applications that rely on persona-based generation, such as personalized language assistants or conversational AI systems. The researchers' call for continued investigation and the development of mitigation strategies is crucial to ensuring that these powerful AI technologies are used in a responsible and ethical manner, minimizing the risk of biased or harmful outputs and [promoting more equitable and inclusive AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
On the steerability of large language models toward data-driven personas
Junyi Li, Ninareh Mehrabi, Charith Peris, Palash Goyal, Kai-Wei Chang, Aram Galstyan, Richard Zemel, Rahul Gupta
0
0
Large language models (LLMs) are known to generate biased responses where the opinions of certain groups and populations are underrepresented. Here, we present a novel approach to achieve controllable generation of specific viewpoints using LLMs, that can be leveraged to produce multiple perspectives and to reflect the diverse opinions. Moving beyond the traditional reliance on demographics like age, gender, or party affiliation, we introduce a data-driven notion of persona grounded in collaborative filtering, which is defined as either a single individual or a cohort of individuals manifesting similar views across specific inquiries. As individuals in the same demographic group may have different personas, our data-driven persona definition allows for a more nuanced understanding of different (latent) social groups present in the population. In addition to this, we also explore an efficient method to steer LLMs toward the personas that we define. We show that our data-driven personas significantly enhance model steerability, with improvements of between $57%-77%$ over our best performing baselines.
4/4/2024
Explicit and Implicit Large Language Model Personas Generate Opinions but Fail to Replicate Deeper Perceptions and Biases
Salvatore Giorgi, Tingting Liu, Ankit Aich, Kelsey Isman, Garrick Sherman, Zachary Fried, Jo~ao Sedoc, Lyle H. Ungar, Brenda Curtis
0
0
Large language models (LLMs) are increasingly being used in human-centered social scientific tasks, such as data annotation, synthetic data creation, and engaging in dialog. However, these tasks are highly subjective and dependent on human factors, such as one's environment, attitudes, beliefs, and lived experiences. Thus, employing LLMs (which do not have such human factors) in these tasks may result in a lack of variation in data, failing to reflect the diversity of human experiences. In this paper, we examine the role of prompting LLMs with human-like personas and asking the models to answer as if they were a specific human. This is done explicitly, with exact demographics, political beliefs, and lived experiences, or implicitly via names prevalent in specific populations. The LLM personas are then evaluated via (1) subjective annotation task (e.g., detecting toxicity) and (2) a belief generation task, where both tasks are known to vary across human factors. We examine the impact of explicit vs. implicit personas and investigate which human factors LLMs recognize and respond to. Results show that LLM personas show mixed results when reproducing known human biases, but generate generally fail to demonstrate implicit biases. We conclude that LLMs lack the intrinsic cognitive mechanisms of human thought, while capturing the statistical patterns of how people speak, which may restrict their effectiveness in complex social science applications.
6/21/2024
Large Language Models Show Human-like Social Desirability Biases in Survey Responses
Aadesh Salecha, Molly E. Ireland, Shashanka Subrahmanya, Jo~ao Sedoc, Lyle H. Ungar, Johannes C. Eichstaedt
0
0
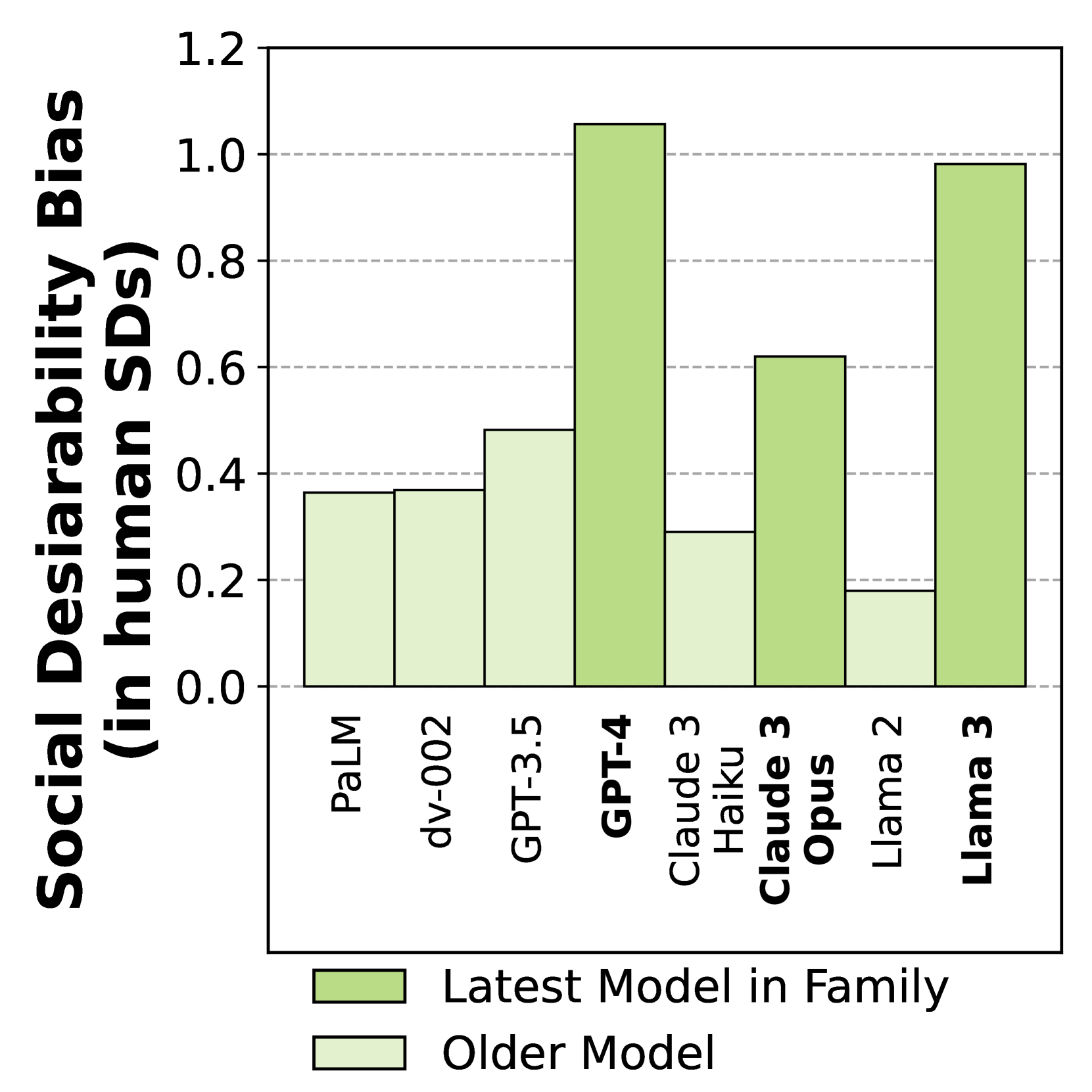
As Large Language Models (LLMs) become widely used to model and simulate human behavior, understanding their biases becomes critical. We developed an experimental framework using Big Five personality surveys and uncovered a previously undetected social desirability bias in a wide range of LLMs. By systematically varying the number of questions LLMs were exposed to, we demonstrate their ability to infer when they are being evaluated. When personality evaluation is inferred, LLMs skew their scores towards the desirable ends of trait dimensions (i.e., increased extraversion, decreased neuroticism, etc). This bias exists in all tested models, including GPT-4/3.5, Claude 3, Llama 3, and PaLM-2. Bias levels appear to increase in more recent models, with GPT-4's survey responses changing by 1.20 (human) standard deviations and Llama 3's by 0.98 standard deviations-very large effects. This bias is robust to randomization of question order and paraphrasing. Reverse-coding all the questions decreases bias levels but does not eliminate them, suggesting that this effect cannot be attributed to acquiescence bias. Our findings reveal an emergent social desirability bias and suggest constraints on profiling LLMs with psychometric tests and on using LLMs as proxies for human participants.
5/13/2024
💬
PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits
Hang Jiang, Xiajie Zhang, Xubo Cao, Cynthia Breazeal, Deb Roy, Jad Kabbara
0
0
Despite the many use cases for large language models (LLMs) in creating personalized chatbots, there has been limited research on evaluating the extent to which the behaviors of personalized LLMs accurately and consistently reflect specific personality traits. We consider studying the behavior of LLM-based agents which we refer to as LLM personas and present a case study with GPT-3.5 and GPT-4 to investigate whether LLMs can generate content that aligns with their assigned personality profiles. To this end, we simulate distinct LLM personas based on the Big Five personality model, have them complete the 44-item Big Five Inventory (BFI) personality test and a story writing task, and then assess their essays with automatic and human evaluations. Results show that LLM personas' self-reported BFI scores are consistent with their designated personality types, with large effect sizes observed across five traits. Additionally, LLM personas' writings have emerging representative linguistic patterns for personality traits when compared with a human writing corpus. Furthermore, human evaluation shows that humans can perceive some personality traits with an accuracy of up to 80%. Interestingly, the accuracy drops significantly when the annotators were informed of AI authorship.
4/3/2024