Stepping Stones: A Progressive Training Strategy for Audio-Visual Semantic Segmentation

0

Sign in to get full access
Overview
- The paper proposes a progressive training strategy called "Stepping Stones" for audio-visual semantic segmentation, a task that involves jointly understanding visual and auditory information to segment an image or video.
- The approach starts by training the model on simpler tasks and then gradually increases the complexity, allowing the model to learn step-by-step and achieve better performance on the final task.
- The authors demonstrate the effectiveness of their approach on several audio-visual segmentation benchmarks, showing improvements over existing state-of-the-art methods.
Plain English Explanation
The paper introduces a new way to train models for audio-visual semantic segmentation, which is the task of identifying and separating different objects or regions in an image or video using both visual and audio information.
The key idea is to start with simpler versions of the task and then gradually increase the difficulty as the model learns. This is like teaching a child to walk by first having them crawl, then stand, and finally take steps. The model starts by learning how to use audio and visual cues separately, and then gradually learns to combine them more effectively.
The authors show that this "stepping stones" approach leads to better performance on several benchmark datasets compared to other state-of-the-art methods. This suggests that the progressive training strategy helps the model learn the task more efficiently and effectively.
Technical Explanation
The paper proposes a "Stepping Stones" training strategy for audio-visual semantic segmentation. The approach involves a series of intermediate training steps that gradually increase the complexity of the task, rather than training the model directly on the full audio-visual segmentation problem.
The authors first train the model to perform visual-only segmentation, then audio-only segmentation, and finally audio-visual segmentation. This allows the model to learn how to utilize the individual modalities before having to combine them. The training curriculum is designed to provide "stepping stones" that guide the model towards the final objective.
The authors evaluate their approach on several audio-visual segmentation benchmarks, including [link to https://aimodels.fyi/papers/arxiv/cross-modal-cognitive-consensus-guided-audio-visual], [link to https://aimodels.fyi/papers/arxiv/save-segment-audio-visual-easy-way-using], and [link to https://aimodels.fyi/papers/arxiv/qdformer-towards-robust-audiovisual-segmentation-complex-environments]. They show that the "Stepping Stones" strategy outperforms other state-of-the-art methods, such as [link to https://aimodels.fyi/papers/arxiv/progressive-confident-masking-attention-network-audio-visual] and [link to https://aimodels.fyi/papers/arxiv/extending-segment-anything-model-into-auditory-temporal].
Critical Analysis
The paper provides a well-designed and thorough evaluation of the "Stepping Stones" training strategy, demonstrating its effectiveness on multiple audio-visual segmentation benchmarks. However, the authors do not extensively discuss the limitations or potential drawbacks of their approach.
One area that could be explored further is the generalization of the trained models. The authors show strong performance on the evaluated datasets, but it would be valuable to understand how the models perform on more diverse or challenging real-world scenarios. Additionally, the computational and memory requirements of the step-by-step training process could be analyzed in more detail.
Overall, the "Stepping Stones" approach is a promising contribution to the field of audio-visual understanding, and the authors have provided a solid foundation for further research in this direction. Encouraging readers to think critically about the research and form their own opinions is an important aspect of a comprehensive analysis.
Conclusion
The paper presents a novel "Stepping Stones" training strategy for audio-visual semantic segmentation, which involves gradually increasing the complexity of the task during the training process. The authors demonstrate that this approach leads to improved performance compared to existing state-of-the-art methods on several benchmark datasets.
The progressive training strategy is an interesting and potentially impactful contribution to the field of multimodal learning, as it suggests that carefully designed curricula can help models learn more effectively. The insights from this research could inspire further advancements in audio-visual understanding and potentially be applicable to other multimodal learning problems.
Overall, the "Stepping Stones" approach represents a valuable step forward in the quest to develop robust and efficient models for jointly understanding visual and auditory information, with implications for a wide range of applications, from autonomous vehicles to assistive technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Stepping Stones: A Progressive Training Strategy for Audio-Visual Semantic Segmentation
Juncheng Ma, Peiwen Sun, Yaoting Wang, Di Hu
Audio-Visual Segmentation (AVS) aims to achieve pixel-level localization of sound sources in videos, while Audio-Visual Semantic Segmentation (AVSS), as an extension of AVS, further pursues semantic understanding of audio-visual scenes. However, since the AVSS task requires the establishment of audio-visual correspondence and semantic understanding simultaneously, we observe that previous methods have struggled to handle this mashup of objectives in end-to-end training, resulting in insufficient learning and sub-optimization. Therefore, we propose a two-stage training strategy called textit{Stepping Stones}, which decomposes the AVSS task into two simple subtasks from localization to semantic understanding, which are fully optimized in each stage to achieve step-by-step global optimization. This training strategy has also proved its generalization and effectiveness on existing methods. To further improve the performance of AVS tasks, we propose a novel framework Adaptive Audio Visual Segmentation, in which we incorporate an adaptive audio query generator and integrate masked attention into the transformer decoder, facilitating the adaptive fusion of visual and audio features. Extensive experiments demonstrate that our methods achieve state-of-the-art results on all three AVS benchmarks. The project homepage can be accessed at https://gewu-lab.github.io/stepping_stones/.
Read more9/14/2024

0
Open-Vocabulary Audio-Visual Semantic Segmentation
Ruohao Guo, Liao Qu, Dantong Niu, Yanyu Qi, Wenzhen Yue, Ji Shi, Bowei Xing, Xianghua Ying
Audio-visual semantic segmentation (AVSS) aims to segment and classify sounding objects in videos with acoustic cues. However, most approaches operate on the close-set assumption and only identify pre-defined categories from training data, lacking the generalization ability to detect novel categories in practical applications. In this paper, we introduce a new task: open-vocabulary audio-visual semantic segmentation, extending AVSS task to open-world scenarios beyond the annotated label space. This is a more challenging task that requires recognizing all categories, even those that have never been seen nor heard during training. Moreover, we propose the first open-vocabulary AVSS framework, OV-AVSS, which mainly consists of two parts: 1) a universal sound source localization module to perform audio-visual fusion and locate all potential sounding objects and 2) an open-vocabulary classification module to predict categories with the help of the prior knowledge from large-scale pre-trained vision-language models. To properly evaluate the open-vocabulary AVSS, we split zero-shot training and testing subsets based on the AVSBench-semantic benchmark, namely AVSBench-OV. Extensive experiments demonstrate the strong segmentation and zero-shot generalization ability of our model on all categories. On the AVSBench-OV dataset, OV-AVSS achieves 55.43% mIoU on base categories and 29.14% mIoU on novel categories, exceeding the state-of-the-art zero-shot method by 41.88%/20.61% and open-vocabulary method by 10.2%/11.6%. The code is available at https://github.com/ruohaoguo/ovavss.
Read more8/1/2024

0
Cross-modal Cognitive Consensus guided Audio-Visual Segmentation
Zhaofeng Shi, Qingbo Wu, Fanman Meng, Linfeng Xu, Hongliang Li
Audio-Visual Segmentation (AVS) aims to extract the sounding object from a video frame, which is represented by a pixel-wise segmentation mask for application scenarios such as multi-modal video editing, augmented reality, and intelligent robot systems. The pioneering work conducts this task through dense feature-level audio-visual interaction, which ignores the dimension gap between different modalities. More specifically, the audio clip could only provide a Global semantic label in each sequence, but the video frame covers multiple semantic objects across different Local regions, which leads to mislocalization of the representationally similar but semantically different object. In this paper, we propose a Cross-modal Cognitive Consensus guided Network (C3N) to align the audio-visual semantics from the global dimension and progressively inject them into the local regions via an attention mechanism. Firstly, a Cross-modal Cognitive Consensus Inference Module (C3IM) is developed to extract a unified-modal label by integrating audio/visual classification confidence and similarities of modality-agnostic label embeddings. Then, we feed the unified-modal label back to the visual backbone as the explicit semantic-level guidance via a Cognitive Consensus guided Attention Module (CCAM), which highlights the local features corresponding to the interested object. Extensive experiments on the Single Sound Source Segmentation (S4) setting and Multiple Sound Source Segmentation (MS3) setting of the AVSBench dataset demonstrate the effectiveness of the proposed method, which achieves state-of-the-art performance. Code is available at https://github.com/ZhaofengSHI/AVS-C3N.
Read more7/18/2024
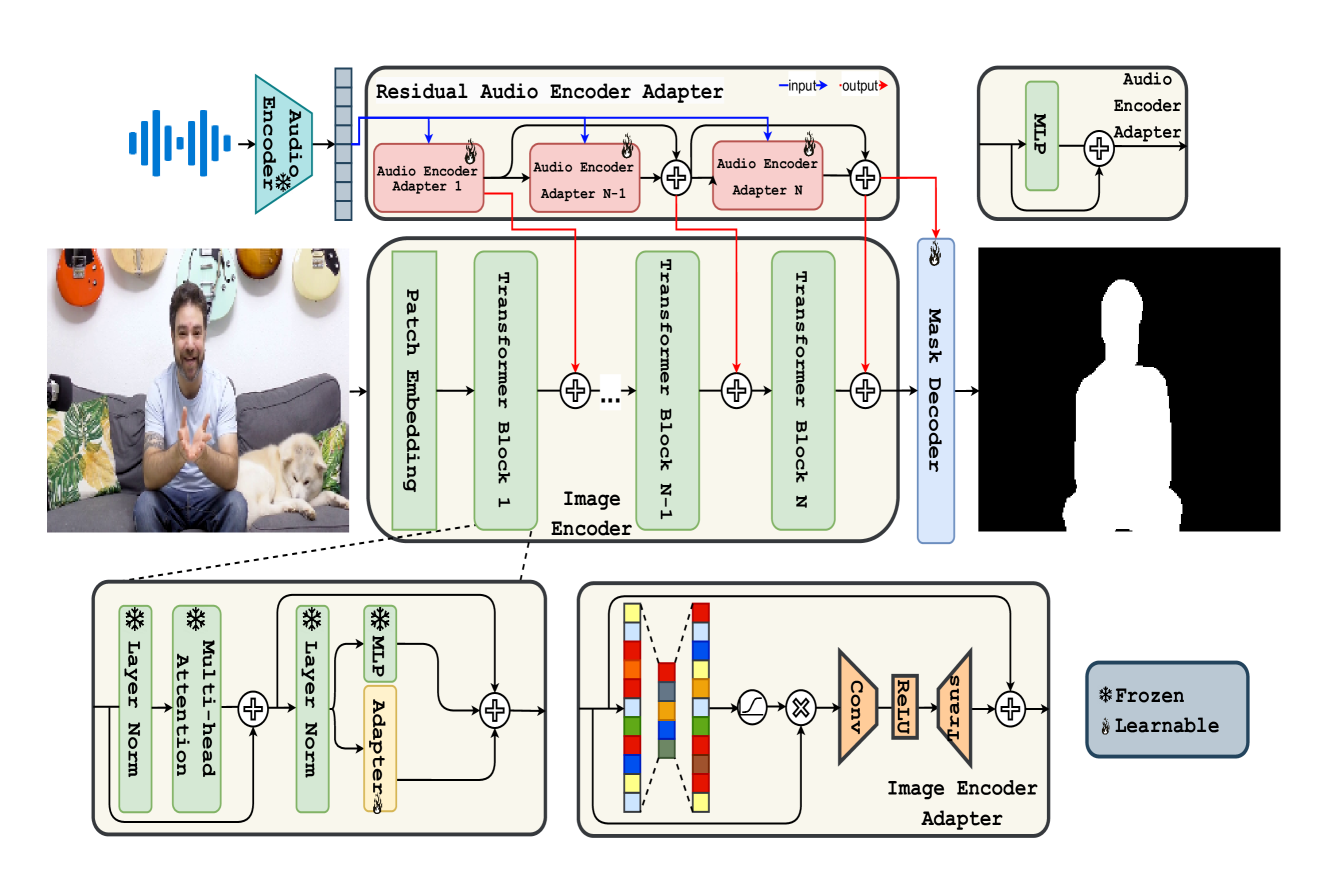
0
SAVE: Segment Audio-Visual Easy way using Segment Anything Model
Khanh-Binh Nguyen, Chae Jung Park
The primary aim of Audio-Visual Segmentation (AVS) is to precisely identify and locate auditory elements within visual scenes by accurately predicting segmentation masks at the pixel level. Achieving this involves comprehensively considering data and model aspects to address this task effectively. This study presents a lightweight approach, SAVE, which efficiently adapts the pre-trained segment anything model (SAM) to the AVS task. By incorporating an image encoder adapter into the transformer blocks to better capture the distinct dataset information and proposing a residual audio encoder adapter to encode the audio features as a sparse prompt, our proposed model achieves effective audio-visual fusion and interaction during the encoding stage. Our proposed method accelerates the training and inference speed by reducing the input resolution from 1024 to 256 pixels while achieving higher performance compared with the previous SOTA. Extensive experimentation validates our approach, demonstrating that our proposed model outperforms other SOTA methods significantly. Moreover, leveraging the pre-trained model on synthetic data enhances performance on real AVSBench data, achieving 84.59 mIoU on the S4 (V1S) subset and 70.28 mIoU on the MS3 (V1M) set with only 256 pixels for input images. This increases up to 86.16 mIoU on the S4 (V1S) and 70.83 mIoU on the MS3 (V1M) with inputs of 1024 pixels.
Read more7/8/2024