SAVE: Segment Audio-Visual Easy way using Segment Anything Model

0
Sign in to get full access
Overview
- The paper introduces SAVE, a method for segmenting audio-visual data using the Segment Anything Model (SAM)
- SAVE simplifies the process of segmenting audio-visual content compared to existing approaches
- The method leverages SAM to segment both visual and auditory elements in a unified manner
Plain English Explanation
The Segment Anything Model (SAM) is a powerful AI tool that can identify and outline objects in images. The authors of this paper had the clever idea to extend SAM to work with audio as well as video.
Their new method, called SAVE, allows users to easily segment both the visual and auditory components of multimedia content. Rather than having to use separate tools for each modality, SAVE provides a streamlined, all-in-one solution. This makes the segmentation process much more efficient and user-friendly.
By tapping into the capabilities of SAM, SAVE can accurately outline different elements within a video or audio recording. This could be useful for a variety of applications, such as video editing, sound design, or media analysis. The technique seems particularly well-suited for tasks that require separating individual components from complex, multi-faceted source material.
Technical Explanation
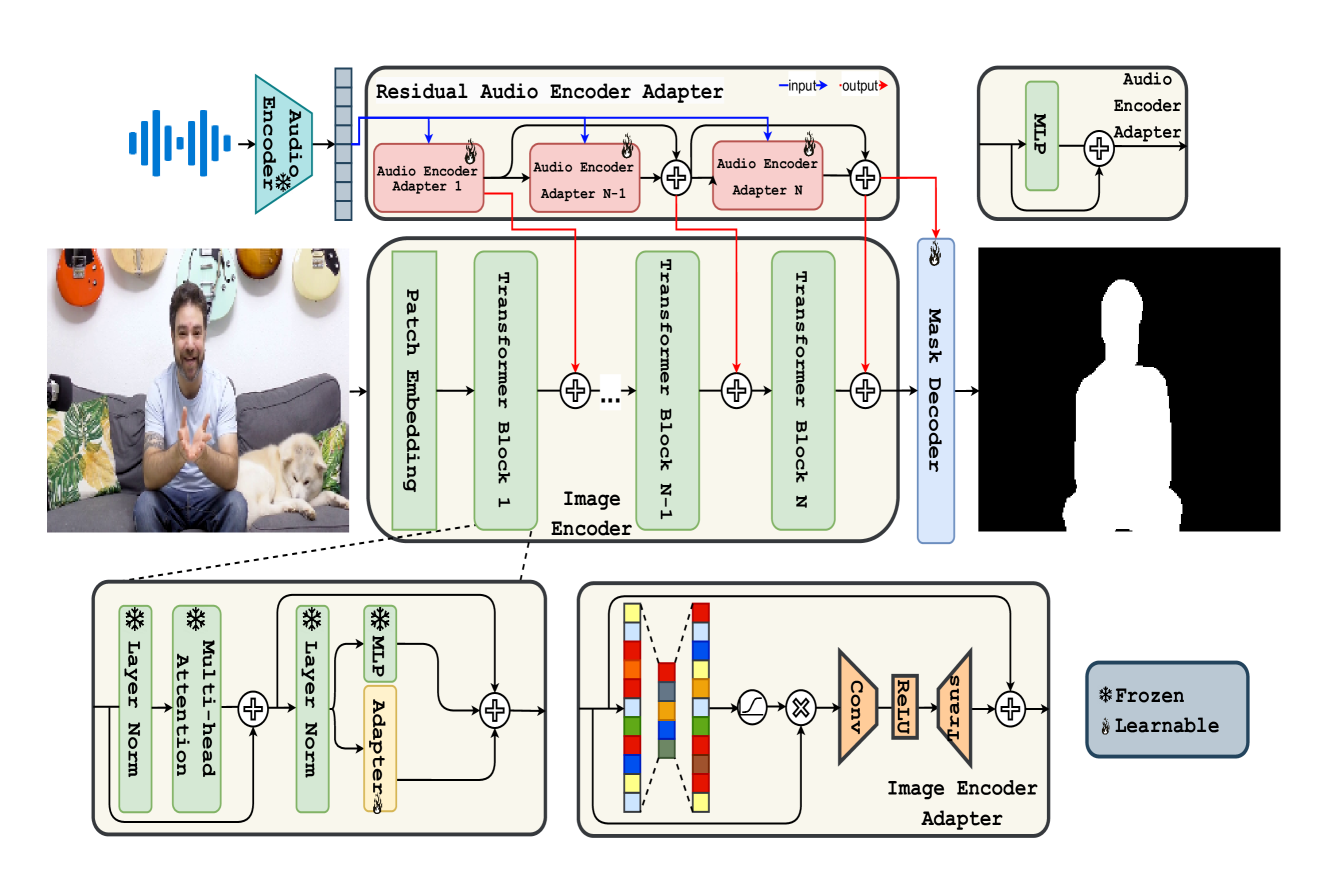
The core of SAVE is an extension of the Segment Anything Model (SAM) to handle both visual and auditory data. The authors leverage cross-modal cognitive consensus to enable joint segmentation of the audio and video streams.
SAVE uses a progressive confident masking attention network to efficiently process the multimedia content. This allows the model to focus on the most relevant areas and produce high-quality segmentation results.
The authors also introduce techniques to improve the robustness of SAVE, such as QDFormer for handling complex environments. Additionally, they explore ways to accelerate the Segment Anything Model to make SAVE more efficient and scalable.
Critical Analysis
The paper presents a compelling approach to simplifying the segmentation of audio-visual data. By integrating SAM's capabilities into a unified framework, SAVE offers a convenient solution that could streamline many multimedia-related workflows.
However, the authors do not provide much discussion on the limitations of their method. For example, it's unclear how SAVE would perform on low-quality or noisy audio/video inputs, or how it would handle complex scenes with significant occlusions or overlapping elements.
Additionally, the reliance on SAM raises questions about the overall computational efficiency and scalability of SAVE. While the authors explore techniques to accelerate the underlying model, the real-world performance and resource requirements of the complete system are not thoroughly evaluated.
Further research and testing would be needed to fully assess SAVE's strengths, weaknesses, and practical applicability across a diverse range of audio-visual segmentation scenarios.
Conclusion
The SAVE method presents a novel approach to simplifying the segmentation of audio-visual data by extending the capabilities of the Segment Anything Model. This integrated framework could streamline various multimedia-related tasks, such as video editing, sound design, and media analysis.
While the technical details suggest SAVE is a promising solution, the paper lacks a comprehensive evaluation of its limitations and real-world performance. Nonetheless, the core idea of combining cross-modal segmentation into a unified tool is compelling and could pave the way for more user-friendly audio-visual processing applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SAVE: Segment Audio-Visual Easy way using Segment Anything Model
Khanh-Binh Nguyen, Chae Jung Park
The primary aim of Audio-Visual Segmentation (AVS) is to precisely identify and locate auditory elements within visual scenes by accurately predicting segmentation masks at the pixel level. Achieving this involves comprehensively considering data and model aspects to address this task effectively. This study presents a lightweight approach, SAVE, which efficiently adapts the pre-trained segment anything model (SAM) to the AVS task. By incorporating an image encoder adapter into the transformer blocks to better capture the distinct dataset information and proposing a residual audio encoder adapter to encode the audio features as a sparse prompt, our proposed model achieves effective audio-visual fusion and interaction during the encoding stage. Our proposed method accelerates the training and inference speed by reducing the input resolution from 1024 to 256 pixels while achieving higher performance compared with the previous SOTA. Extensive experimentation validates our approach, demonstrating that our proposed model outperforms other SOTA methods significantly. Moreover, leveraging the pre-trained model on synthetic data enhances performance on real AVSBench data, achieving 84.59 mIoU on the S4 (V1S) subset and 70.28 mIoU on the MS3 (V1M) set with only 256 pixels for input images. This increases up to 86.16 mIoU on the S4 (V1S) and 70.83 mIoU on the MS3 (V1M) with inputs of 1024 pixels.
Read more7/8/2024
📈
0
Extending Segment Anything Model into Auditory and Temporal Dimensions for Audio-Visual Segmentation
Juhyeong Seon, Woobin Im, Sebin Lee, Jumin Lee, Sung-Eui Yoon
Audio-visual segmentation (AVS) aims to segment sound sources in the video sequence, requiring a pixel-level understanding of audio-visual correspondence. As the Segment Anything Model (SAM) has strongly impacted extensive fields of dense prediction problems, prior works have investigated the introduction of SAM into AVS with audio as a new modality of the prompt. Nevertheless, constrained by SAM's single-frame segmentation scheme, the temporal context across multiple frames of audio-visual data remains insufficiently utilized. To this end, we study the extension of SAM's capabilities to the sequence of audio-visual scenes by analyzing contextual cross-modal relationships across the frames. To achieve this, we propose a Spatio-Temporal, Bidirectional Audio-Visual Attention (ST-BAVA) module integrated into the middle of SAM's image encoder and mask decoder. It adaptively updates the audio-visual features to convey the spatio-temporal correspondence between the video frames and audio streams. Extensive experiments demonstrate that our proposed model outperforms the state-of-the-art methods on AVS benchmarks, especially with an 8.3% mIoU gain on a challenging multi-sources subset.
Read more6/11/2024

0
Cross-modal Cognitive Consensus guided Audio-Visual Segmentation
Zhaofeng Shi, Qingbo Wu, Fanman Meng, Linfeng Xu, Hongliang Li
Audio-Visual Segmentation (AVS) aims to extract the sounding object from a video frame, which is represented by a pixel-wise segmentation mask for application scenarios such as multi-modal video editing, augmented reality, and intelligent robot systems. The pioneering work conducts this task through dense feature-level audio-visual interaction, which ignores the dimension gap between different modalities. More specifically, the audio clip could only provide a Global semantic label in each sequence, but the video frame covers multiple semantic objects across different Local regions, which leads to mislocalization of the representationally similar but semantically different object. In this paper, we propose a Cross-modal Cognitive Consensus guided Network (C3N) to align the audio-visual semantics from the global dimension and progressively inject them into the local regions via an attention mechanism. Firstly, a Cross-modal Cognitive Consensus Inference Module (C3IM) is developed to extract a unified-modal label by integrating audio/visual classification confidence and similarities of modality-agnostic label embeddings. Then, we feed the unified-modal label back to the visual backbone as the explicit semantic-level guidance via a Cognitive Consensus guided Attention Module (CCAM), which highlights the local features corresponding to the interested object. Extensive experiments on the Single Sound Source Segmentation (S4) setting and Multiple Sound Source Segmentation (MS3) setting of the AVSBench dataset demonstrate the effectiveness of the proposed method, which achieves state-of-the-art performance. Code is available at https://github.com/ZhaofengSHI/AVS-C3N.
Read more7/18/2024

0
Open-Vocabulary Audio-Visual Semantic Segmentation
Ruohao Guo, Liao Qu, Dantong Niu, Yanyu Qi, Wenzhen Yue, Ji Shi, Bowei Xing, Xianghua Ying
Audio-visual semantic segmentation (AVSS) aims to segment and classify sounding objects in videos with acoustic cues. However, most approaches operate on the close-set assumption and only identify pre-defined categories from training data, lacking the generalization ability to detect novel categories in practical applications. In this paper, we introduce a new task: open-vocabulary audio-visual semantic segmentation, extending AVSS task to open-world scenarios beyond the annotated label space. This is a more challenging task that requires recognizing all categories, even those that have never been seen nor heard during training. Moreover, we propose the first open-vocabulary AVSS framework, OV-AVSS, which mainly consists of two parts: 1) a universal sound source localization module to perform audio-visual fusion and locate all potential sounding objects and 2) an open-vocabulary classification module to predict categories with the help of the prior knowledge from large-scale pre-trained vision-language models. To properly evaluate the open-vocabulary AVSS, we split zero-shot training and testing subsets based on the AVSBench-semantic benchmark, namely AVSBench-OV. Extensive experiments demonstrate the strong segmentation and zero-shot generalization ability of our model on all categories. On the AVSBench-OV dataset, OV-AVSS achieves 55.43% mIoU on base categories and 29.14% mIoU on novel categories, exceeding the state-of-the-art zero-shot method by 41.88%/20.61% and open-vocabulary method by 10.2%/11.6%. The code is available at https://github.com/ruohaoguo/ovavss.
Read more8/1/2024