STG-MTL: Scalable Task Grouping for Multi-Task Learning Using Data Map
2307.03374
0
0
Abstract
Multi-Task Learning (MTL) is a powerful technique that has gained popularity due to its performance improvement over traditional Single-Task Learning (STL). However, MTL is often challenging because there is an exponential number of possible task groupings, which can make it difficult to choose the best one because some groupings might produce performance degradation due to negative interference between tasks. That is why existing solutions are severely suffering from scalability issues, limiting any practical application. In our paper, we propose a new data-driven method that addresses these challenges and provides a scalable and modular solution for classification task grouping based on a re-proposed data-driven features, Data Maps, which capture the training dynamics for each classification task during the MTL training. Through a theoretical comparison with other techniques, we manage to show that our approach has the superior scalability. Our experiments show a better performance and verify the method's effectiveness, even on an unprecedented number of tasks (up to 100 tasks on CIFAR100). Being the first to work on such number of tasks, our comparisons on the resulting grouping shows similar grouping to the mentioned in the dataset, CIFAR100. Finally, we provide a modular implementation for easier integration and testing, with examples from multiple datasets and tasks.
Create account to get full access
Overview
- This paper introduces a novel multi-task learning (MTL) approach called STG-MTL (Scalable Task Grouping for Multi-Task Learning) that uses data maps to group related tasks.
- The key idea is to leverage the underlying task relationships to improve the efficiency and effectiveness of MTL, rather than treating all tasks equally.
- The authors propose a scalable algorithm to automatically discover task groups and train models for each group, leading to improved performance compared to traditional MTL methods.
Plain English Explanation
The paper focuses on a problem called "multi-task learning" (MTL). In MTL, a model is trained to solve multiple related tasks at the same time, like recognizing different types of objects in images or predicting different attributes of a person. The key insight is that by learning multiple tasks together, the model can leverage the commonalities between the tasks to perform better on each individual task.
However, traditional MTL approaches treat all tasks equally, even if some tasks are more closely related than others. The new method proposed in this paper, called STG-MTL, tries to automatically identify groups of related tasks and train separate models for each group. This allows the model to focus on the most relevant task relationships, leading to better overall performance.
The authors use the analogy of a "data map" to visualize the relationships between the tasks. Just like a geographic map shows the relative locations of different places, the data map shows how the different tasks are related to each other based on the underlying data. By clustering the tasks into groups based on this map, the STG-MTL approach can learn the tasks more efficiently.
The key innovation is the scalable algorithm the authors developed to automatically discover these task groups and train the models. This makes the approach practical for real-world applications with a large number of tasks, unlike previous methods that required manual task grouping.
Technical Explanation
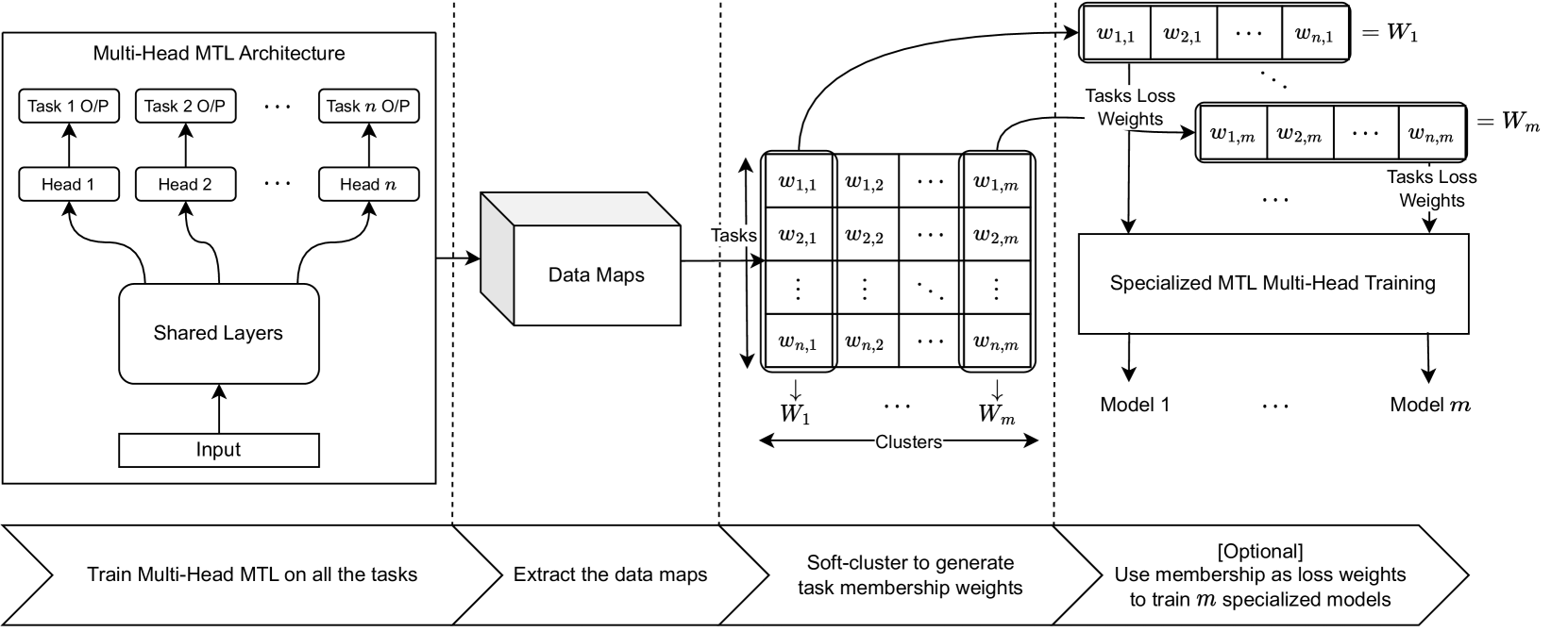
The paper presents the STG-MTL (Scalable Task Grouping for Multi-Task Learning) approach, which aims to improve the efficiency and effectiveness of multi-task learning (MTL) by exploiting the underlying relationships between tasks.
The core idea is to automatically discover task groups and train separate models for each group, rather than treating all tasks equally. The authors propose a scalable algorithm to achieve this, based on the concept of "data maps" - visual representations of the task relationships derived from the data.
The STG-MTL method consists of three main steps:
- Task Relationship Discovery: The authors construct a data map that encodes the pairwise similarities between tasks, using techniques like principal component analysis and spectral clustering.
- Task Grouping: A scalable clustering algorithm is applied to the data map to identify groups of related tasks.
- Model Training: Separate models are trained for each task group, allowing the model to focus on the most relevant task relationships.
The authors evaluate STG-MTL on several benchmark datasets and show that it outperforms traditional MTL approaches in terms of overall task performance. The key advantages are the ability to automatically discover task groups and the scalability of the algorithm, making it practical for real-world applications with a large number of tasks.
Critical Analysis
The STG-MTL paper presents a compelling approach to improving the efficiency and effectiveness of multi-task learning. The use of data maps to visualize and model the task relationships is a novel and insightful idea, and the scalable algorithm for task grouping is a valuable contribution.
However, the paper does not address several important limitations and potential issues:
- The performance of the task grouping algorithm may be sensitive to the choice of hyperparameters and the quality of the data map construction.
- The approach assumes that tasks can be neatly divided into distinct groups, but in some applications, the task relationships may be more complex and overlapping.
- The paper does not explore the interpretability of the discovered task groups or provide insights into the nature of the learned task relationships.
Additionally, the authors could have challenged their own approach more rigorously. For example, they could have compared STG-MTL to other task grouping methods or explored the impact of different data map construction techniques on the final results.
Overall, the STG-MTL paper represents a valuable contribution to the field of multi-task learning, but future research should address the limitations and explore the broader implications of the task grouping approach.
Conclusion
The STG-MTL paper introduces a scalable and effective approach to multi-task learning that leverages the underlying relationships between tasks. By automatically discovering task groups and training separate models for each group, the method can outperform traditional MTL techniques.
The key innovation is the use of "data maps" to visualize and model the task relationships, coupled with a scalable algorithm for task grouping. This allows the STG-MTL approach to be practical for real-world applications with a large number of tasks, unlike previous methods that required manual task grouping.
While the paper demonstrates the effectiveness of the STG-MTL approach, it also highlights the need for further research to address the limitations and explore the broader implications of task-based modeling in multi-task learning. As the field of MTL continues to evolve, techniques like STG-MTL will play an important role in unlocking the full potential of joint task learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras
Jun Yu, Yutong Dai, Xiaokang Liu, Jin Huang, Yishan Shen, Ke Zhang, Rong Zhou, Eashan Adhikarla, Wenxuan Ye, Yixin Liu, Zhaoming Kong, Kai Zhang, Yilong Yin, Vinod Namboodiri, Brian D. Davison, Jason H. Moore, Yong Chen
0
0
MTL is a learning paradigm that effectively leverages both task-specific and shared information to address multiple related tasks simultaneously. In contrast to STL, MTL offers a suite of benefits that enhance both the training process and the inference efficiency. MTL's key advantages encompass streamlined model architecture, performance enhancement, and cross-domain generalizability. Over the past twenty years, MTL has become widely recognized as a flexible and effective approach in various fields, including CV, NLP, recommendation systems, disease prognosis and diagnosis, and robotics. This survey provides a comprehensive overview of the evolution of MTL, encompassing the technical aspects of cutting-edge methods from traditional approaches to deep learning and the latest trend of pretrained foundation models. Our survey methodically categorizes MTL techniques into five key areas: regularization, relationship learning, feature propagation, optimization, and pre-training. This categorization not only chronologically outlines the development of MTL but also dives into various specialized strategies within each category. Furthermore, the survey reveals how the MTL evolves from handling a fixed set of tasks to embracing a more flexible approach free from task or modality constraints. It explores the concepts of task-promptable and -agnostic training, along with the capacity for ZSL, which unleashes the untapped potential of this historically coveted learning paradigm. Overall, we hope this survey provides the research community with a comprehensive overview of the advancements in MTL from its inception in 1997 to the present in 2023. We address present challenges and look ahead to future possibilities, shedding light on the opportunities and potential avenues for MTL research in a broad manner. This project is publicly available at https://github.com/junfish/Awesome-Multitask-Learning.
5/1/2024
MT2ST: Adaptive Multi-Task to Single-Task Learning
Dong Liu, Meng Jiang
0
0
The conventional training approaches often face challenges in balancing the breadth of multi-task learning (MTL) with the depth of single-task learning (STL). To address this issue, we introduce the Multi-Task to Single-Task (MT2ST) framework, a groundbreaking approach that can combine the generalizability of MTL with the precision of STL. Our work include two strategies: 'Diminish' and 'Switch'. 'Diminish' Strategy will gradually reduce the influence of auxiliary tasks, while the 'Switch' strategy involves a shift from multi-tasking to single-tasking at a specific timepoint at the training process. In this paper, we propose the Multi-Task to Single-Task (MT2ST) framework, a novel approach that significantly enhances the efficiency and accuracy of word embedding training while concurrently addressing prevalent issues such as overfitting. Our empirical studies demonstrate that MT2ST can reduce training time by 67% when contrasted with single-task learning approaches, and by 13% compared to traditional multi-task learning methods. These findings underscore MT2ST's potential to be a powerful tools for word embedding training acceleration.
6/27/2024

Interpetable Target-Feature Aggregation for Multi-Task Learning based on Bias-Variance Analysis
Paolo Bonetti, Alberto Maria Metelli, Marcello Restelli
0
0
Multi-task learning (MTL) is a powerful machine learning paradigm designed to leverage shared knowledge across tasks to improve generalization and performance. Previous works have proposed approaches to MTL that can be divided into feature learning, focused on the identification of a common feature representation, and task clustering, where similar tasks are grouped together. In this paper, we propose an MTL approach at the intersection between task clustering and feature transformation based on a two-phase iterative aggregation of targets and features. First, we propose a bias-variance analysis for regression models with additive Gaussian noise, where we provide a general expression of the asymptotic bias and variance of a task, considering a linear regression trained on aggregated input features and an aggregated target. Then, we exploit this analysis to provide a two-phase MTL algorithm (NonLinCTFA). Firstly, this method partitions the tasks into clusters and aggregates each obtained group of targets with their mean. Then, for each aggregated task, it aggregates subsets of features with their mean in a dimensionality reduction fashion. In both phases, a key aspect is to preserve the interpretability of the reduced targets and features through the aggregation with the mean, which is further motivated by applications to Earth science. Finally, we validate the algorithms on synthetic data, showing the effect of different parameters and real-world datasets, exploring the validity of the proposed methodology on classical datasets, recent baselines, and Earth science applications.
6/13/2024
🖼️
Examining Common Paradigms in Multi-Task Learning
Cathrin Elich, Lukas Kirchdorfer, Jan M. Kohler, Lukas Schott
0
0
While multi-task learning (MTL) has gained significant attention in recent years, its underlying mechanisms remain poorly understood. Recent methods did not yield consistent performance improvements over single task learning (STL) baselines, underscoring the importance of gaining more profound insights about challenges specific to MTL. In our study, we investigate paradigms in MTL in the context of STL: First, the impact of the choice of optimizer has only been mildly investigated in MTL. We show the pivotal role of common STL tools such as the Adam optimizer in MTL empirically in various experiments. To further investigate Adam's effectiveness, we theoretical derive a partial loss-scale invariance under mild assumptions. Second, the notion of gradient conflicts has often been phrased as a specific problem in MTL. We delve into the role of gradient conflicts in MTL and compare it to STL. For angular gradient alignment we find no evidence that this is a unique problem in MTL. We emphasize differences in gradient magnitude as the main distinguishing factor. Overall, we find surprising similarities between STL and MTL suggesting to consider methods from both fields in a broader context.
6/28/2024