Examining Common Paradigms in Multi-Task Learning

0
🖼️
Sign in to get full access
Overview
- The paper investigates the underlying mechanisms of multi-task learning (MTL), a machine learning technique where a model is trained to perform multiple tasks simultaneously.
- The authors explore two key aspects of MTL: the impact of the choice of optimizer, and the role of gradient conflicts.
- They find surprising similarities between MTL and single-task learning (STL), suggesting that methods from both fields should be considered in a broader context.
Plain English Explanation
In multi-task learning (MTL), a single model is trained to perform multiple tasks at once, rather than training separate models for each task. This can be more efficient and lead to better performance, but the underlying reasons for this are not well understood.
The authors of this paper investigate two important aspects of MTL. First, they look at the impact of the choice of optimizer, which is the algorithm that updates the model's parameters during training. They find that common optimizers used in single-task learning, such as the Adam optimizer, play a crucial role in the success of MTL. The authors provide a theoretical explanation for why the Adam optimizer is effective in MTL.
Second, the authors explore the concept of "gradient conflicts," which is the idea that the gradients (the direction in which the model's parameters should be updated) for different tasks might be in conflict with each other, making it difficult for the model to learn. However, the authors find that this is not a unique problem to MTL, and that the main difference between MTL and STL is actually in the magnitude (size) of the gradients, rather than their alignment.
Overall, the authors find that there are more similarities between MTL and STL than previously thought, suggesting that researchers should consider methods from both fields when working on multi-task learning problems.
Technical Explanation
The paper begins by highlighting the importance of understanding the underlying mechanisms of multi-task learning (MTL), as recent methods have not consistently outperformed single-task learning (STL) baselines.
First, the authors investigate the impact of the choice of optimizer in MTL. They show that common STL tools, such as the Adam optimizer, play a pivotal role in the success of MTL. To further understand Adam's effectiveness, the authors theoretically derive a partial loss-scale invariance under mild assumptions.
Second, the paper delves into the role of gradient conflicts in MTL and compares it to STL. The authors find no evidence that angular gradient alignment is a unique problem in MTL, but emphasize differences in gradient magnitude as the main distinguishing factor.
Overall, the authors find surprising similarities between STL and MTL, suggesting that methods from both fields should be considered in a broader context. This contrasts with the common perception of MTL as a fundamentally different paradigm from STL.
Critical Analysis
The paper provides valuable insights into the underlying mechanisms of MTL, addressing important questions that have not been well explored in previous research. The authors' findings challenge the conventional wisdom about the differences between MTL and STL, and encourage a more holistic view of these learning paradigms.
However, the paper does not address some potential limitations of the research. For example, the authors focus on a specific set of tasks and datasets, and it is unclear whether their findings would generalize to a wider range of MTL problems. Additionally, the theoretical analysis of the Adam optimizer's effectiveness in MTL may rely on certain assumptions that may not always hold in practice.
Further research is needed to explore the generalizability of the authors' findings and to investigate other factors that may contribute to the success or failure of MTL, such as the choice of task grouping strategies or the use of adaptive multi-task to single-task (MT2ST) techniques. Additionally, the role of scalable task grouping in multi-task learning and the application of MTL in natural language processing are important areas that warrant further investigation.
Conclusion
This paper provides valuable insights into the underlying mechanisms of multi-task learning, challenging the conventional wisdom about the differences between MTL and STL. The authors' findings suggest that common tools used in single-task learning, such as the Adam optimizer, play a crucial role in the success of MTL, and that gradient conflicts are not a unique problem to MTL. These insights have important implications for the development of more effective and efficient multi-task learning systems, and encourage researchers to consider methods from both the MTL and STL fields in a broader context.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Examining Common Paradigms in Multi-Task Learning
Cathrin Elich, Lukas Kirchdorfer, Jan M. Kohler, Lukas Schott
While multi-task learning (MTL) has gained significant attention in recent years, its underlying mechanisms remain poorly understood. Recent methods did not yield consistent performance improvements over single task learning (STL) baselines, underscoring the importance of gaining more profound insights about challenges specific to MTL. In our study, we investigate paradigms in MTL in the context of STL: First, the impact of the choice of optimizer has only been mildly investigated in MTL. We show the pivotal role of common STL tools such as the Adam optimizer in MTL empirically in various experiments. To further investigate Adam's effectiveness, we theoretical derive a partial loss-scale invariance under mild assumptions. Second, the notion of gradient conflicts has often been phrased as a specific problem in MTL. We delve into the role of gradient conflicts in MTL and compare it to STL. For angular gradient alignment we find no evidence that this is a unique problem in MTL. We emphasize differences in gradient magnitude as the main distinguishing factor. Overall, we find surprising similarities between STL and MTL suggesting to consider methods from both fields in a broader context.
Read more8/16/2024
0
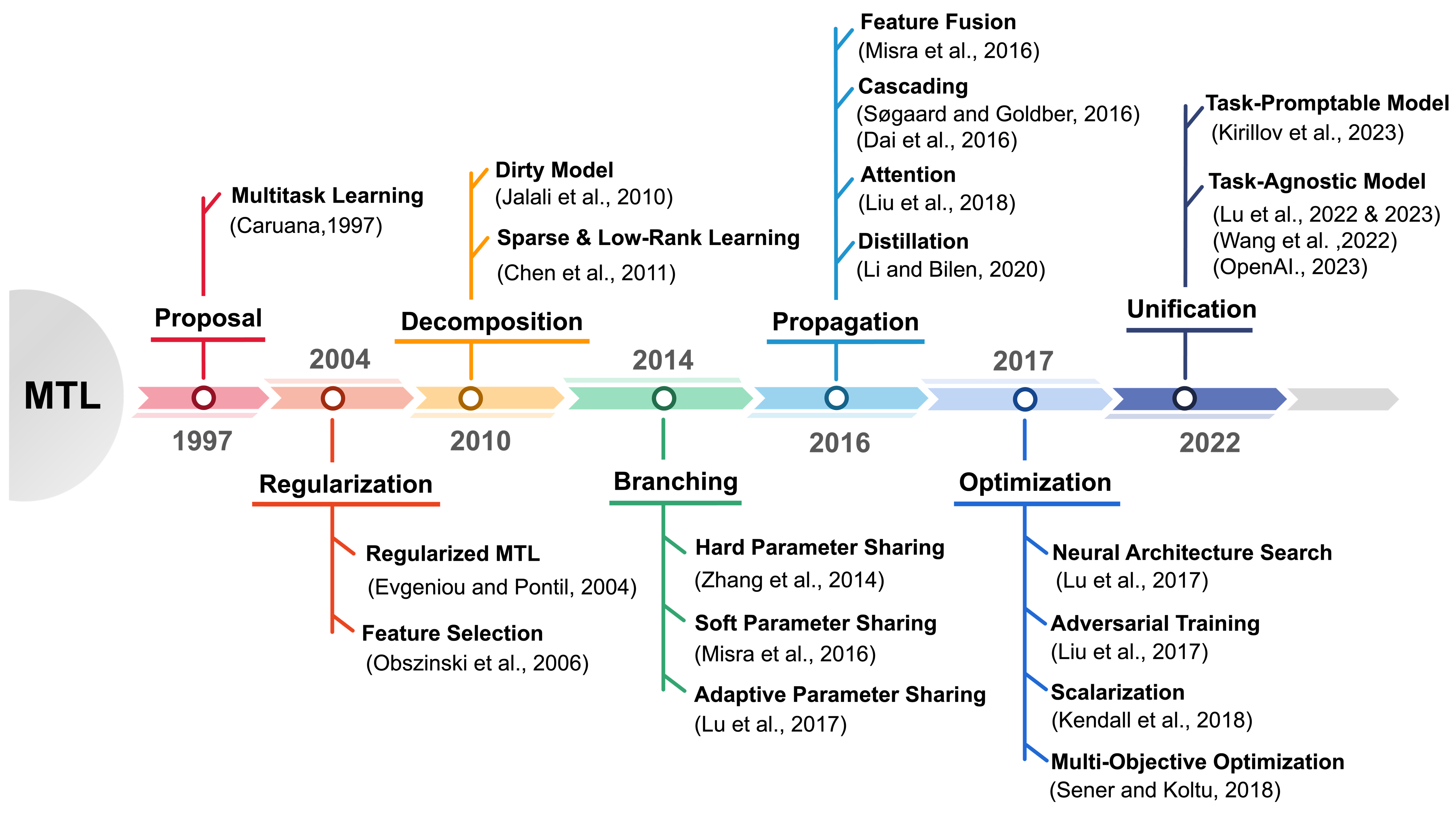
Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras
Jun Yu, Yutong Dai, Xiaokang Liu, Jin Huang, Yishan Shen, Ke Zhang, Rong Zhou, Eashan Adhikarla, Wenxuan Ye, Yixin Liu, Zhaoming Kong, Kai Zhang, Yilong Yin, Vinod Namboodiri, Brian D. Davison, Jason H. Moore, Yong Chen
MTL is a learning paradigm that effectively leverages both task-specific and shared information to address multiple related tasks simultaneously. In contrast to STL, MTL offers a suite of benefits that enhance both the training process and the inference efficiency. MTL's key advantages encompass streamlined model architecture, performance enhancement, and cross-domain generalizability. Over the past twenty years, MTL has become widely recognized as a flexible and effective approach in various fields, including CV, NLP, recommendation systems, disease prognosis and diagnosis, and robotics. This survey provides a comprehensive overview of the evolution of MTL, encompassing the technical aspects of cutting-edge methods from traditional approaches to deep learning and the latest trend of pretrained foundation models. Our survey methodically categorizes MTL techniques into five key areas: regularization, relationship learning, feature propagation, optimization, and pre-training. This categorization not only chronologically outlines the development of MTL but also dives into various specialized strategies within each category. Furthermore, the survey reveals how the MTL evolves from handling a fixed set of tasks to embracing a more flexible approach free from task or modality constraints. It explores the concepts of task-promptable and -agnostic training, along with the capacity for ZSL, which unleashes the untapped potential of this historically coveted learning paradigm. Overall, we hope this survey provides the research community with a comprehensive overview of the advancements in MTL from its inception in 1997 to the present in 2023. We address present challenges and look ahead to future possibilities, shedding light on the opportunities and potential avenues for MTL research in a broad manner. This project is publicly available at https://github.com/junfish/Awesome-Multitask-Learning.
Read more5/1/2024

0
Can Optimization Trajectories Explain Multi-Task Transfer?
David Mueller, Mark Dredze, Nicholas Andrews
Despite the widespread adoption of multi-task training in deep learning, little is understood about how multi-task learning (MTL) affects generalization. Prior work has conjectured that the negative effects of MTL are due to optimization challenges that arise during training, and many optimization methods have been proposed to improve multi-task performance. However, recent work has shown that these methods fail to consistently improve multi-task generalization. In this work, we seek to improve our understanding of these failures by empirically studying how MTL impacts the optimization of tasks, and whether this impact can explain the effects of MTL on generalization. We show that MTL results in a generalization gap-a gap in generalization at comparable training loss-between single-task and multi-task trajectories early into training. However, we find that factors of the optimization trajectory previously proposed to explain generalization gaps in single-task settings cannot explain the generalization gaps between single-task and multi-task models. Moreover, we show that the amount of gradient conflict between tasks is correlated with negative effects to task optimization, but is not predictive of generalization. Our work sheds light on the underlying causes for failures in MTL and, importantly, raises questions about the role of general purpose multi-task optimization algorithms.
Read more8/28/2024
👀
0
When Multi-Task Learning Meets Partial Supervision: A Computer Vision Review
Maxime Fontana, Michael Spratling, Miaojing Shi
Multi-Task Learning (MTL) aims to learn multiple tasks simultaneously while exploiting their mutual relationships. By using shared resources to simultaneously calculate multiple outputs, this learning paradigm has the potential to have lower memory requirements and inference times compared to the traditional approach of using separate methods for each task. Previous work in MTL has mainly focused on fully-supervised methods, as task relationships can not only be leveraged to lower the level of data-dependency of those methods but they can also improve performance. However, MTL introduces a set of challenges due to a complex optimisation scheme and a higher labeling requirement. This review focuses on how MTL could be utilised under different partial supervision settings to address these challenges. First, this review analyses how MTL traditionally uses different parameter sharing techniques to transfer knowledge in between tasks. Second, it presents the different challenges arising from such a multi-objective optimisation scheme. Third, it introduces how task groupings can be achieved by analysing task relationships. Fourth, it focuses on how partially supervised methods applied to MTL can tackle the aforementioned challenges. Lastly, this review presents the available datasets, tools and benchmarking results of such methods.
Read more8/29/2024