Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras
2404.18961
0
0
Abstract
MTL is a learning paradigm that effectively leverages both task-specific and shared information to address multiple related tasks simultaneously. In contrast to STL, MTL offers a suite of benefits that enhance both the training process and the inference efficiency. MTL's key advantages encompass streamlined model architecture, performance enhancement, and cross-domain generalizability. Over the past twenty years, MTL has become widely recognized as a flexible and effective approach in various fields, including CV, NLP, recommendation systems, disease prognosis and diagnosis, and robotics. This survey provides a comprehensive overview of the evolution of MTL, encompassing the technical aspects of cutting-edge methods from traditional approaches to deep learning and the latest trend of pretrained foundation models. Our survey methodically categorizes MTL techniques into five key areas: regularization, relationship learning, feature propagation, optimization, and pre-training. This categorization not only chronologically outlines the development of MTL but also dives into various specialized strategies within each category. Furthermore, the survey reveals how the MTL evolves from handling a fixed set of tasks to embracing a more flexible approach free from task or modality constraints. It explores the concepts of task-promptable and -agnostic training, along with the capacity for ZSL, which unleashes the untapped potential of this historically coveted learning paradigm. Overall, we hope this survey provides the research community with a comprehensive overview of the advancements in MTL from its inception in 1997 to the present in 2023. We address present challenges and look ahead to future possibilities, shedding light on the opportunities and potential avenues for MTL research in a broad manner. This project is publicly available at https://github.com/junfish/Awesome-Multitask-Learning.
Get summaries of the top AI research delivered straight to your inbox:
Overview
• This paper provides a comprehensive survey of multi-task learning in natural language processing, spanning traditional, deep, and large-scale pretrained foundation model approaches.
• It explores how multi-task learning can enable more general-purpose AI models that can handle a diverse set of tasks, improving upon specialized models.
• The paper delves into how multi-task training affects the inner workings of transformers, a key architecture underlying many state-of-the-art language models.
• It also examines the emergence of large-scale multi-modal pretrained models that can be further fine-tuned for a variety of tasks.
Plain English Explanation
Multi-task learning is an approach in artificial intelligence where a single model is trained to perform multiple different tasks, rather than having a separate model for each task. This allows the model to develop more general capabilities that can be applied across a wider range of applications.
Traditional AI models tended to be highly specialized, designed to excel at a specific task like language translation or image recognition. But by training a model on multiple related tasks simultaneously, it can learn patterns and features that are useful for a broader set of applications. This makes the model more "general-purpose" and adaptable.
The paper looks at how this multi-task training approach has evolved over time, from earlier neural network models to the powerful transformer architectures that underpin many of today's state-of-the-art language models. It also explores the latest developments in large-scale multi-modal pretrained models that can handle a diverse array of tasks across different data modalities like text, images, and video.
The key insight is that by training models on multiple tasks simultaneously, they can develop more flexible and generally applicable capabilities, rather than being narrowly specialized. This could lead to more versatile and powerful AI systems that can adapt to a wide range of real-world applications.
Technical Explanation
The paper provides a comprehensive survey of multi-task learning approaches in natural language processing, tracing the evolution from traditional machine learning models to the current era of deep learning and large-scale pretrained foundation models.
Traditional multi-task learning involved training a single model to perform multiple related tasks simultaneously, leveraging shared representations and knowledge transfer between tasks. This was seen as a way to enable more general-purpose AI systems, rather than narrowly specialized models.
The advent of deep learning, and particularly the transformer architecture, has significantly advanced the multi-task learning paradigm. The paper examines how multi-task training affects the inner workings of transformers, leading to more robust and adaptable language models.
More recently, the emergence of large-scale multi-modal pretrained models has further expanded the possibilities of multi-task learning. These models are trained on vast amounts of diverse data, allowing them to develop broad capabilities that can be fine-tuned for a wide range of downstream tasks.
Critical Analysis
The paper provides a comprehensive and insightful overview of the evolution of multi-task learning in natural language processing. However, it also acknowledges some potential limitations and areas for further research.
One caveat mentioned is the challenge of effectively training large multi-task models, as the increased complexity can lead to optimization difficulties and potential negative transfer between tasks. The paper suggests that further advancements in multi-task learning algorithms and training techniques may be needed to address these challenges.
Additionally, the paper notes that while large-scale pretrained models have shown impressive versatility, their performance on individual tasks may not always match that of specialized models. This raises questions about the tradeoffs between generalization and task-specific optimization.
Further research could also explore the societal implications of increasingly general-purpose AI systems, such as their impact on the job market and the need for responsible development and deployment of these technologies.
Conclusion
This paper provides a comprehensive overview of the evolution of multi-task learning in natural language processing, tracing the journey from traditional machine learning approaches to the current era of deep learning and large-scale pretrained foundation models.
The key insight is that by training models to handle multiple tasks simultaneously, they can develop more flexible and generally applicable capabilities, rather than being narrowly specialized. This could lead to the emergence of more versatile and powerful AI systems that can adapt to a wide range of real-world applications.
However, the paper also acknowledges the challenges and potential tradeoffs involved in this pursuit, highlighting the need for continued research and advancements in multi-task learning techniques and algorithms. As these technologies continue to evolve, it will be important to consider their broader societal implications and ensure their responsible development and deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
Multi-Task Learning in Natural Language Processing: An Overview
Shijie Chen, Yu Zhang, Qiang Yang
0
0
Deep learning approaches have achieved great success in the field of Natural Language Processing (NLP). However, directly training deep neural models often suffer from overfitting and data scarcity problems that are pervasive in NLP tasks. In recent years, Multi-Task Learning (MTL), which can leverage useful information of related tasks to achieve simultaneous performance improvement on these tasks, has been used to handle these problems. In this paper, we give an overview of the use of MTL in NLP tasks. We first review MTL architectures used in NLP tasks and categorize them into four classes, including parallel architecture, hierarchical architecture, modular architecture, and generative adversarial architecture. Then we present optimization techniques on loss construction, gradient regularization, data sampling, and task scheduling to properly train a multi-task model. After presenting applications of MTL in a variety of NLP tasks, we introduce some benchmark datasets. Finally, we make a conclusion and discuss several possible research directions in this field.
4/30/2024
❗
Multi-Task Learning as enabler for General-Purpose AI-native RAN
Hasan Farooq, Julien Forgeat, Shruti Bothe, Kristijonas Cyras, Md Moin
0
0
The realization of data-driven AI-native architecture envisioned for 6G and beyond networks can eventually lead to multiple machine learning (ML) workloads distributed at the network edges driving downstream tasks like secondary carrier prediction, positioning, channel prediction etc. The independent life-cycle management of these edge-distributed independent multiple workloads sharing a resource-constrained compute node e.g., base station (BS) is a challenge that will scale with denser deployments. This study explores the effectiveness of multi-task learning (MTL) approaches in facilitating a general-purpose AI native Radio Access Network (RAN). The investigation focuses on four RAN tasks: (i) secondary carrier prediction, (ii) user location prediction, (iii) indoor link classification, and (iv) line-of-sight link classification. We validate the performance using realistic simulations considering multi-faceted design aspects of MTL including model architecture, loss and gradient balancing strategies, distributed learning topology, data sparsity and task groupings. The quantification and insights from simulations reveal that for the four RAN tasks considered (i) adoption of customized gate control-based expert architecture with uncertainty-based weighting makes MTL perform either best among all or at par with single task learning (STL) (ii) LoS classification task in MTL setting helps other tasks but its own performance is degraded (iii) for sparse training data, training a single global MTL model is helpful but MTL performance is on par with STL (iv) optimal set of group pairing exists for each task and (v) partial federation is much better than full model federation in MTL setting.
4/24/2024
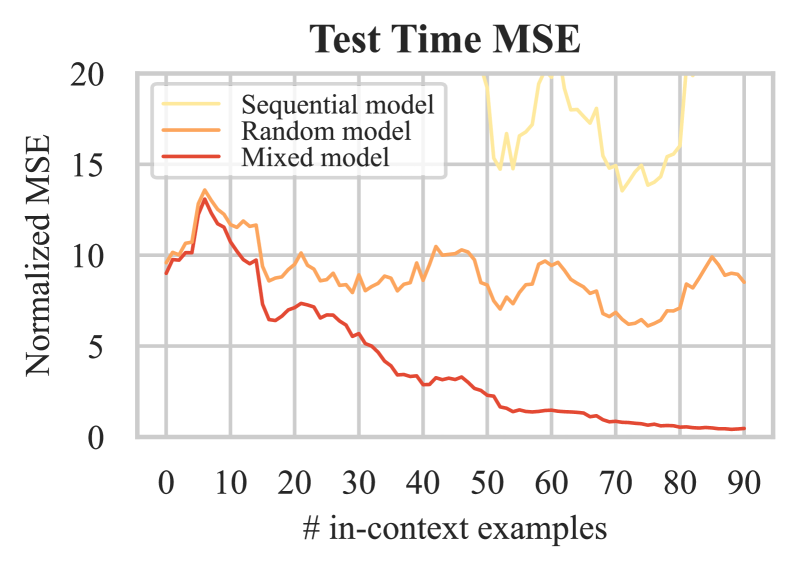
How does Multi-Task Training Affect Transformer In-Context Capabilities? Investigations with Function Classes
Harmon Bhasin, Timothy Ossowski, Yiqiao Zhong, Junjie Hu
0
0
Large language models (LLM) have recently shown the extraordinary ability to perform unseen tasks based on few-shot examples provided as text, also known as in-context learning (ICL). While recent works have attempted to understand the mechanisms driving ICL, few have explored training strategies that incentivize these models to generalize to multiple tasks. Multi-task learning (MTL) for generalist models is a promising direction that offers transfer learning potential, enabling large parameterized models to be trained from simpler, related tasks. In this work, we investigate the combination of MTL with ICL to build models that efficiently learn tasks while being robust to out-of-distribution examples. We propose several effective curriculum learning strategies that allow ICL models to achieve higher data efficiency and more stable convergence. Our experiments reveal that ICL models can effectively learn difficult tasks by training on progressively harder tasks while mixing in prior tasks, denoted as mixed curriculum in this work. Our code and models are available at https://github.com/harmonbhasin/curriculum_learning_icl .
4/5/2024
➖
Large-scale Multi-Modal Pre-trained Models: A Comprehensive Survey
Xiao Wang, Guangyao Chen, Guangwu Qian, Pengcheng Gao, Xiao-Yong Wei, Yaowei Wang, Yonghong Tian, Wen Gao
0
0
With the urgent demand for generalized deep models, many pre-trained big models are proposed, such as BERT, ViT, GPT, etc. Inspired by the success of these models in single domains (like computer vision and natural language processing), the multi-modal pre-trained big models have also drawn more and more attention in recent years. In this work, we give a comprehensive survey of these models and hope this paper could provide new insights and helps fresh researchers to track the most cutting-edge works. Specifically, we firstly introduce the background of multi-modal pre-training by reviewing the conventional deep learning, pre-training works in natural language process, computer vision, and speech. Then, we introduce the task definition, key challenges, and advantages of multi-modal pre-training models (MM-PTMs), and discuss the MM-PTMs with a focus on data, objectives, network architectures, and knowledge enhanced pre-training. After that, we introduce the downstream tasks used for the validation of large-scale MM-PTMs, including generative, classification, and regression tasks. We also give visualization and analysis of the model parameters and results on representative downstream tasks. Finally, we point out possible research directions for this topic that may benefit future works. In addition, we maintain a continuously updated paper list for large-scale pre-trained multi-modal big models: https://github.com/wangxiao5791509/MultiModal_BigModels_Survey. This paper has been published by the journal Machine Intelligence Research (MIR), https://link.springer.com/article/10.1007/s11633-022-1410-8, DOI: 10.1007/s11633-022-1410-8, vol. 20, no. 4, pp. 447-482, 2023.
4/11/2024