STMT: A Spatial-Temporal Mesh Transformer for MoCap-Based Action Recognition

0
👁️
Sign in to get full access
Overview
- The researchers propose a novel Spatial-Temporal Mesh Transformer (STMT) model for human action recognition using motion capture (MoCap) sequences.
- Unlike existing techniques that require multiple manual steps to derive standardized skeleton representations, STMT directly models the mesh sequences.
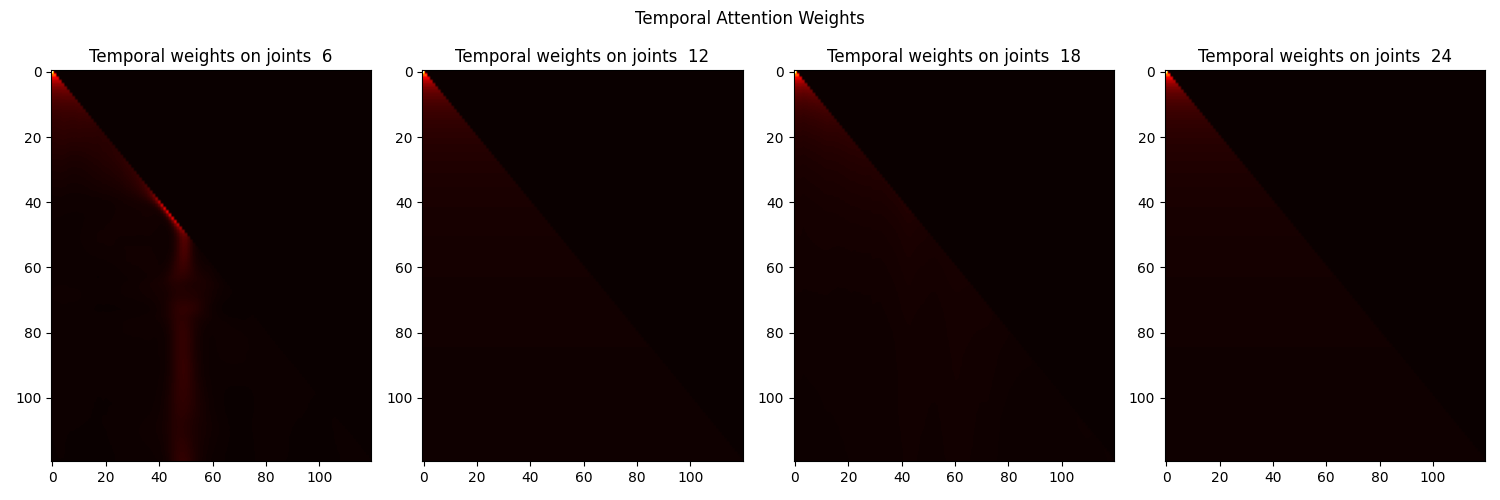
- The model uses a hierarchical transformer with intra-frame offset attention and inter-frame self-attention to learn spatial-temporal relationships.
- Masked vertex modeling and future frame prediction are used as self-supervised tasks to fully activate the bi-directional and auto-regressive attention.
- The proposed method achieves state-of-the-art performance on common MoCap benchmarks compared to skeleton-based and point-cloud-based models.
Plain English Explanation
Motion capture (MoCap) is a technology used to record human movement by tracking the positions of various points on the body over time. This data can be used for a variety of applications, such as creating realistic animations or recognizing human actions.
Traditionally, techniques for action recognition from MoCap data have involved several manual steps to extract a standardized skeleton representation from the raw data. This can be a time-consuming and error-prone process. The researchers behind this paper wanted to find a way to directly model the MoCap data without needing to go through these intermediate steps.
Their solution is a deep learning model called the Spatial-Temporal Mesh Transformer (STMT). This model uses a hierarchical transformer architecture to learn the spatial and temporal relationships in the MoCap data. The transformer has two key attention mechanisms:
- Intra-frame offset attention: This allows the model to learn how the different parts of the body are related to each other within a single frame of MoCap data.
- Inter-frame self-attention: This allows the model to understand how the body's movement changes over time between frames.
The researchers also used two self-supervised training tasks to help the model learn even better representations of the MoCap data:
- Masked vertex modeling: The model has to predict the positions of some "hidden" vertices in the mesh, forcing it to learn the underlying spatial relationships.
- Future frame prediction: The model has to predict the positions of vertices in future frames, forcing it to learn the temporal dynamics of the movement.
By using this novel architecture and training approach, the STMT model was able to achieve state-of-the-art performance on standard MoCap benchmarks, outperforming previous techniques that relied on extracting skeleton representations.
Technical Explanation
The proposed Spatial-Temporal Mesh Transformer (STMT) model directly takes 3D mesh sequences as input, without the need for intermediate skeleton representation extraction. The model uses a hierarchical transformer architecture with two key attention mechanisms:
- Intra-frame offset attention: This attention module learns the spatial relationships between different vertex patches within a single frame of the MoCap data. It allows the model to attend to any two vertex patches and learn their relative offsets.
- Inter-frame self-attention: This attention module learns the temporal relationships between frames. It allows the model to attend to any two frames and understand how the body's movement changes over time.
The hierarchical transformer structure consists of multiple layers, each with these two attention mechanisms. This enables the model to learn multi-scale spatial-temporal representations of the input mesh sequences.
To further improve the model's learning of the underlying spatial-temporal structure, the researchers employed two self-supervised tasks:
- Masked vertex modeling: The model is trained to predict the positions of randomly masked vertices in the mesh, forcing it to learn the spatial relationships between different parts of the body.
- Future frame prediction: The model is trained to predict the positions of vertices in future frames, forcing it to learn the temporal dynamics of the movement.
These self-supervised tasks help the model fully activate its bi-directional and auto-regressive attention capabilities, leading to better representations of the input MoCap data.
The proposed STMT model was evaluated on common MoCap benchmarks, such as NTU RGB+D and BABEL, and was found to outperform existing skeleton-based and point-cloud-based approaches for human action recognition.
Critical Analysis
The researchers provide a thorough evaluation of their STMT model, comparing it to various state-of-the-art methods on multiple MoCap datasets. The results demonstrate the effectiveness of their approach in directly modeling mesh sequences, without the need for intermediate skeleton representation extraction.
One potential limitation of the study is the reliance on MoCap data, which may not be as readily available as other data sources, such as video. While the researchers mention the model's ability to handle noise and outliers in the MoCap data, it would be interesting to see how the STMT model performs on less controlled, real-world data sources.
Additionally, the researchers do not provide much discussion on the computational complexity or inference time of their model, which could be an important consideration for real-world applications. A more comprehensive analysis of the model's efficiency and deployment feasibility would be valuable.
Overall, the STMT model presents a novel and promising approach to human action recognition, leveraging the spatial-temporal structure of MoCap data through a hierarchical transformer architecture and self-supervised training tasks. Further research could explore the model's performance on more diverse and challenging datasets, as well as investigate its practical deployment considerations.
Conclusion
The Spatial-Temporal Mesh Transformer (STMT) model proposed in this paper offers a novel solution for human action recognition using motion capture (MoCap) data. By directly modeling the 3D mesh sequences, the model avoids the need for manual extraction of standardized skeleton representations, which can be a tedious and error-prone process.
The hierarchical transformer architecture with its intra-frame offset attention and inter-frame self-attention mechanisms allows the STMT model to learn rich spatial-temporal representations of the input MoCap data. The self-supervised training tasks of masked vertex modeling and future frame prediction further enhance the model's ability to capture the underlying structure of human movement.
The researchers have demonstrated the effectiveness of their approach by achieving state-of-the-art performance on common MoCap benchmarks, outperforming both skeleton-based and point-cloud-based models. This work presents an exciting advancement in the field of human action recognition and could have significant implications for a wide range of applications, from 3D human pose estimation to animation and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
STMT: A Spatial-Temporal Mesh Transformer for MoCap-Based Action Recognition
Xiaoyu Zhu, Po-Yao Huang, Junwei Liang, Celso M. de Melo, Alexander Hauptmann
We study the problem of human action recognition using motion capture (MoCap) sequences. Unlike existing techniques that take multiple manual steps to derive standardized skeleton representations as model input, we propose a novel Spatial-Temporal Mesh Transformer (STMT) to directly model the mesh sequences. The model uses a hierarchical transformer with intra-frame off-set attention and inter-frame self-attention. The attention mechanism allows the model to freely attend between any two vertex patches to learn non-local relationships in the spatial-temporal domain. Masked vertex modeling and future frame prediction are used as two self-supervised tasks to fully activate the bi-directional and auto-regressive attention in our hierarchical transformer. The proposed method achieves state-of-the-art performance compared to skeleton-based and point-cloud-based models on common MoCap benchmarks. Code is available at https://github.com/zgzxy001/STMT.
Read more7/30/2024

0
A Semantic and Motion-Aware Spatiotemporal Transformer Network for Action Detection
Matthew Korban, Peter Youngs, Scott T. Acton
This paper presents a novel spatiotemporal transformer network that introduces several original components to detect actions in untrimmed videos. First, the multi-feature selective semantic attention model calculates the correlations between spatial and motion features to model spatiotemporal interactions between different action semantics properly. Second, the motion-aware network encodes the locations of action semantics in video frames utilizing the motion-aware 2D positional encoding algorithm. Such a motion-aware mechanism memorizes the dynamic spatiotemporal variations in action frames that current methods cannot exploit. Third, the sequence-based temporal attention model captures the heterogeneous temporal dependencies in action frames. In contrast to standard temporal attention used in natural language processing, primarily aimed at finding similarities between linguistic words, the proposed sequence-based temporal attention is designed to determine both the differences and similarities between video frames that jointly define the meaning of actions. The proposed approach outperforms the state-of-the-art solutions on four spatiotemporal action datasets: AVA 2.2, AVA 2.1, UCF101-24, and EPIC-Kitchens.
Read more5/15/2024

0
SpATr: MoCap 3D Human Action Recognition based on Spiral Auto-encoder and Transformer Network
Hamza Bouzid, Lahoucine Ballihi
Recent technological advancements have significantly expanded the potential of human action recognition through harnessing the power of 3D data. This data provides a richer understanding of actions, including depth information that enables more accurate analysis of spatial and temporal characteristics. In this context, We study the challenge of 3D human action recognition.Unlike prior methods, that rely on sampling 2D depth images, skeleton points, or point clouds, often leading to substantial memory requirements and the ability to handle only short sequences, we introduce a novel approach for 3D human action recognition, denoted as SpATr (Spiral Auto-encoder and Transformer Network), specifically designed for fixed-topology mesh sequences. The SpATr model disentangles space and time in the mesh sequences. A lightweight auto-encoder, based on spiral convolutions, is employed to extract spatial geometrical features from each 3D mesh. These convolutions are lightweight and specifically designed for fix-topology mesh data. Subsequently, a temporal transformer, based on self-attention, captures the temporal context within the feature sequence. The self-attention mechanism enables long-range dependencies capturing and parallel processing, ensuring scalability for long sequences. The proposed method is evaluated on three prominent 3D human action datasets: Babel, MoVi, and BMLrub, from the Archive of Motion Capture As Surface Shapes (AMASS). Our results analysis demonstrates the competitive performance of our SpATr model in 3D human action recognition while maintaining efficient memory usage. The code and the training results will soon be made publicly available at https://github.com/h-bouzid/spatr.
Read more5/31/2024
0
A Mixture of Experts Approach to 3D Human Motion Prediction
Edmund Shieh, Joshua Lee Franco, Kang Min Bae, Tej Lalvani
This project addresses the challenge of human motion prediction, a critical area for applications such as au- tonomous vehicle movement detection. Previous works have emphasized the need for low inference times to provide real time performance for applications like these. Our primary objective is to critically evaluate existing model ar- chitectures, identifying their advantages and opportunities for improvement by replicating the state-of-the-art (SOTA) Spatio-Temporal Transformer model as best as possible given computational con- straints. These models have surpassed the limitations of RNN-based models and have demonstrated the ability to generate plausible motion sequences over both short and long term horizons through the use of spatio-temporal rep- resentations. We also propose a novel architecture to ad- dress challenges of real time inference speed by incorpo- rating a Mixture of Experts (MoE) block within the Spatial- Temporal (ST) attention layer. The particular variation that is used is Soft MoE, a fully-differentiable sparse Transformer that has shown promising ability to enable larger model capacity at lower inference cost. We make out code publicly available at https://github.com/edshieh/motionprediction
Read more5/13/2024