Stochastic Two Points Method for Deep Model Zeroth-order Optimization

0
🤿
Sign in to get full access
Overview
- Large language models have shown impressive performance in various applications, but building or fine-tuning them is often prohibitively expensive.
- Zeroth-order optimization methods, which only require forward passes and not backpropagation, offer a promising solution to this challenge.
- This paper introduces an efficient Stochastic Two-Point (S2P) approach within the gradient-free regime and explores its theoretical and empirical properties.
Plain English Explanation
Large language models like those used in AI chatbots and text generation have been incredibly successful at many tasks. However, creating or fine-tuning these models from scratch can be extremely expensive, often requiring specialized hardware and extensive training time.
The researchers in this paper explore an alternative approach called "zeroth-order optimization." This method only requires running the model forward, without the need for the complex backpropagation step that is typically used to update the model's parameters. This can make training much more efficient and accessible, especially for smaller organizations or individuals without access to powerful computing resources.
The paper introduces a specific zeroth-order method called Stochastic Two-Point (S2P) and analyzes its theoretical properties. They also present a variant of S2P that aims to better capture the dynamics of training deep neural networks. The empirical results show that this variant, called VS2P, is highly effective at optimizing objectives for deep models, matching or outperforming standard training methods across a variety of model types and scales.
Technical Explanation
The paper introduces an efficient Stochastic Two-Point (S2P) approach within the gradient-free regime. S2P only requires forward passes of the model, without the need for backpropagation to compute gradients.
The researchers present the theoretical convergence properties of S2P under general and relaxed smoothness assumptions. These theoretical results help connect two popular types of zeroth-order methods: basic random search and stochastic three-point methods.
The paper also introduces a Variant of S2P (VS2P) that exploits the new convergence properties to better represent the dynamics of deep models during training. The comprehensive empirical evaluation shows that VS2P outperforms or achieves competitive performance compared to standard methods across various model types and scales.
Critical Analysis
The paper provides a thorough theoretical and empirical analysis of the proposed S2P and VS2P methods, offering valuable insights into the capabilities of zeroth-order optimization for training large models. However, the authors acknowledge that their methods may still struggle with complex, high-dimensional optimization problems, as is common with gradient-free techniques.
Additionally, the paper does not address potential issues around the stability or generalization of models trained using these zeroth-order approaches. Further research would be needed to understand how the learned models perform on out-of-distribution data or in real-world deployment scenarios.
It would also be interesting to see comparisons between the zeroth-order methods explored in this paper and other gradient-based techniques or variance reduction methods that aim to improve the efficiency of model training. Understanding the trade-offs between these different approaches could help researchers and practitioners choose the most appropriate optimization strategy for their specific use cases.
Conclusion
This paper introduces a promising zeroth-order optimization method called Stochastic Two-Point (S2P) and its variant, VS2P, which can effectively train large deep learning models without the need for backpropagation. The theoretical analysis and empirical results demonstrate the potential of these gradient-free techniques to make advanced AI models more accessible and cost-effective to develop. While there are still some limitations to address, this work represents an important step forward in addressing the challenges of training large foundation models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Stochastic Two Points Method for Deep Model Zeroth-order Optimization
Yijiang Pang, Jiayu Zhou
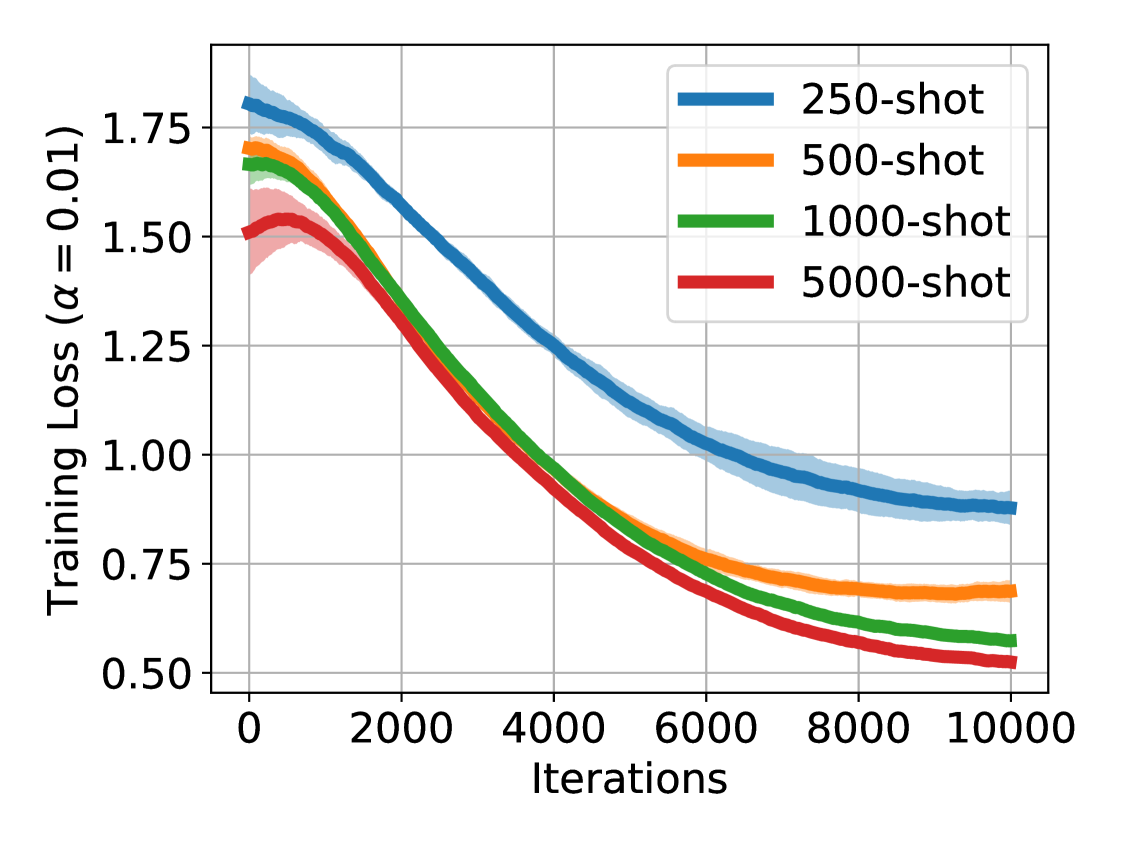
Large foundation models, such as large language models, have performed exceptionally well in various application scenarios. Building or fully fine-tuning such large models is usually prohibitive due to either hardware budget or lack of access to backpropagation. The zeroth-order methods offer a promising direction for tackling this challenge, where only forward passes are needed to update the model. This paper introduces an efficient Stochastic Two-Point (S2P) approach within the gradient-free regime. We present the theoretical convergence properties of S2P under the general and relaxed smoothness assumptions, and the derived results help understand and inherently connect the two popular types of zeroth-order methods, basic random search and stochastic three-point method. The theoretical properties also shed light on a Variant of S2P (VS2P), through exploiting our new convergence properties that better represent the dynamics of deep models in training. Our comprehensive empirical results show that VS2P is highly effective in optimizing objectives for deep models. It outperforms or achieves competitive performance compared to standard methods across various model types and scales.
Read more5/28/2024
0
Private Fine-tuning of Large Language Models with Zeroth-order Optimization
Xinyu Tang, Ashwinee Panda, Milad Nasr, Saeed Mahloujifar, Prateek Mittal
Differentially private stochastic gradient descent (DP-SGD) allows models to be trained in a privacy-preserving manner, but has proven difficult to scale to the era of foundation models. We introduce DP-ZO, a private fine-tuning framework for large language models by privatizing zeroth order optimization methods. A key insight into the design of our method is that the direction of the gradient in the zeroth-order optimization we use is random and the only information from training data is the step size, i.e., a scalar. Therefore, we only need to privatize the scalar step size, which is memory-efficient. DP-ZO provides a strong privacy-utility trade-off across different tasks, and model sizes that are comparable to DP-SGD in $(varepsilon,delta)$-DP. Notably, DP-ZO possesses significant advantages over DP-SGD in memory efficiency, and obtains higher utility in $varepsilon$-DP when using the Laplace mechanism.
Read more8/13/2024
💬
0
Differentially Private Zeroth-Order Methods for Scalable Large Language Model Finetuning
Z Liu, J Lou, W Bao, Y Hu, B Li, Z Qin, K Ren
Fine-tuning on task-specific datasets is a widely-embraced paradigm of harnessing the powerful capability of pretrained LLMs for various downstream tasks. Due to the popularity of LLMs fine-tuning and its accompanying privacy concerns, differentially private (DP) fine-tuning of pretrained LLMs has been widely used to safeguarding the privacy of task-specific datasets. Lying at the design core of DP LLM fine-tuning methods is the satisfactory tradeoff among privacy, utility, and scalability. Most existing methods build upon the seminal work of DP-SGD. Despite pushing the scalability of DP-SGD to its limit, DP-SGD-based fine-tuning methods are unfortunately limited by the inherent inefficiency of SGD. In this paper, we investigate the potential of DP zeroth-order methods for LLM pretraining, which avoids the scalability bottleneck of SGD by approximating the gradient with the more efficient zeroth-order gradient. Rather than treating the zeroth-order method as a drop-in replacement for SGD, this paper presents a comprehensive study both theoretically and empirically. First, we propose the stagewise DP zeroth-order method (DP-ZOSO) that dynamically schedules key hyperparameters. This design is grounded on the synergy between DP random perturbation and the gradient approximation error of the zeroth-order method, and its effect on fine-tuning trajectory. We provide theoretical analysis for both proposed methods. We conduct extensive empirical analysis on both encoder-only masked language model and decoder-only autoregressive language model, achieving impressive results in terms of scalability and utility (compared with DPZero, DP-ZOPO improves 4.5% on SST-5, 5.5% on MNLI with RoBERTa-Large and 9.2% on CB, 3.9% on BoolQ with OPT-2.7B when $epsilon=4$).
Read more5/10/2024
🏅
0
Fast Two-Time-Scale Stochastic Gradient Method with Applications in Reinforcement Learning
Sihan Zeng, Thinh T. Doan
Two-time-scale optimization is a framework introduced in Zeng et al. (2024) that abstracts a range of policy evaluation and policy optimization problems in reinforcement learning (RL). Akin to bi-level optimization under a particular type of stochastic oracle, the two-time-scale optimization framework has an upper level objective whose gradient evaluation depends on the solution of a lower level problem, which is to find the root of a strongly monotone operator. In this work, we propose a new method for solving two-time-scale optimization that achieves significantly faster convergence than the prior arts. The key idea of our approach is to leverage an averaging step to improve the estimates of the operators in both lower and upper levels before using them to update the decision variables. These additional averaging steps eliminate the direct coupling between the main variables, enabling the accelerated performance of our algorithm. We characterize the finite-time convergence rates of the proposed algorithm under various conditions of the underlying objective function, including strong convexity, convexity, Polyak-Lojasiewicz condition, and general non-convexity. These rates significantly improve over the best-known complexity of the standard two-time-scale stochastic approximation algorithm. When applied to RL, we show how the proposed algorithm specializes to novel online sample-based methods that surpass or match the performance of the existing state of the art. Finally, we support our theoretical results with numerical simulations in RL.
Read more6/11/2024