Straggler-Resilient Differentially-Private Decentralized Learning

0
🛸
Sign in to get full access
Overview
- The paper addresses the "straggler problem" in decentralized learning, where some nodes in a network take longer to complete their computations, slowing down the overall training process.
- It extends a previous framework called "differential privacy (DP) amplification by decentralization" to include the impact of both computation and communication latency on the overall training time.
- The paper analyzes the trade-off between training latency, accuracy, and privacy, using a "skipping scheme" that ignores stragglers after a timeout, and a baseline scheme that waits for all nodes to finish.
- Experiments are conducted on logistic regression and image classification tasks using real-world datasets.
Plain English Explanation
When training machine learning models in a decentralized network, some nodes (or devices) may take longer than others to complete their computations, a problem known as the "straggler problem." This can slow down the overall training process.
The researchers in this paper have extended a previous method called "differential privacy (DP) amplification by decentralization" to address this issue. Their approach considers not only the computational time but also the communication time between nodes, which can be a significant factor in decentralized settings.
The paper explores two schemes: a "skipping scheme" that ignores stragglers after a certain timeout, and a baseline scheme that waits for all nodes to finish before continuing the training. The researchers analyze the trade-offs between the overall training time, the accuracy of the final model, and the level of privacy (using differential privacy) that can be achieved with each scheme.
Through experiments on logistic regression and image classification tasks, the researchers show that the skipping scheme can effectively balance these competing factors, allowing for faster training times without sacrificing too much accuracy or privacy.
Technical Explanation
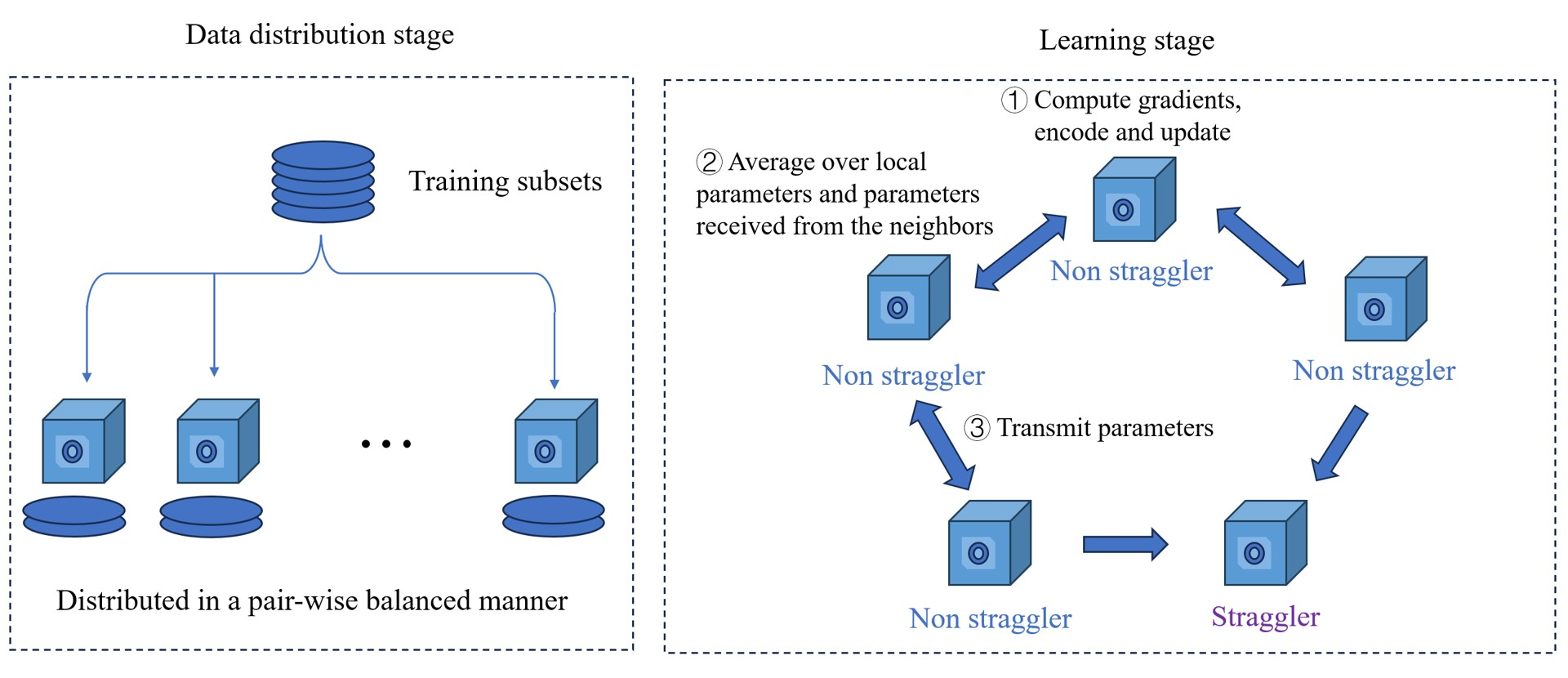
The paper extends the "differential privacy (DP) amplification by decentralization" framework to include the impact of both computation and communication latency on the overall training time in a decentralized learning setting over a logical ring topology.
The authors derive analytical results on the convergence speed and the DP level for both the "skipping scheme" (which ignores stragglers after a timeout) and a baseline scheme that waits for each node to finish before the training continues. These results are then empirically validated using logistic regression on a real-world dataset and image classification on the MNIST and CIFAR-10 datasets.
The key insights from the technical analysis are:
- The skipping scheme can effectively balance the trade-off between overall training latency, accuracy, and privacy, with the timeout parameter controlling this balance.
- Compared to the baseline scheme, the skipping scheme can achieve significant reductions in training time without sacrificing too much accuracy or privacy.
- The analytical results provide a principled way to choose the timeout parameter in the skipping scheme to achieve the desired trade-off.
Critical Analysis
The paper provides a thorough analysis of the straggler problem in decentralized learning and presents a practical solution that considers both computation and communication latency. The authors have built upon previous work on "differential privacy (DP) amplification by decentralization" and "scale-robust and timely asynchronous decentralized learning" to address this important challenge.
One potential limitation of the research is that it focuses on a logical ring topology, which may not be representative of all real-world decentralized learning scenarios. It would be valuable to see how the skipping scheme performs in other network topologies, such as random graphs or small-world networks.
Additionally, the paper does not explore the impact of node failures or the potential for adversarial attacks on the decentralized system. While the differential privacy guarantees provide some level of robustness, further research is needed to understand the resilience of the approach in the face of more sophisticated threats.
Overall, the paper presents a promising solution to the straggler problem in decentralized learning and offers a blueprint for future research in this important area. Readers are encouraged to critically evaluate the findings and consider how the techniques might be applied or extended in their own work.
Conclusion
This paper addresses a key challenge in decentralized learning - the "straggler problem" - where some nodes in the network take longer to complete their computations, slowing down the overall training process. By extending a previous framework for "differential privacy (DP) amplification by decentralization", the researchers have developed a skipping scheme that can effectively balance the trade-off between training time, accuracy, and privacy.
The analytical and empirical results demonstrate the effectiveness of this approach, particularly in scenarios where communication latency is a significant factor. This work contributes to the growing body of research on "scale-robust and timely asynchronous decentralized learning" and "privacy-preserving and dropout-resilient aggregation in decentralized learning", providing valuable insights for the development of robust and efficient decentralized machine learning systems.
As decentralized learning becomes increasingly important in areas like federated learning and edge computing, this research highlights the importance of addressing the straggler problem and the potential benefits of the skipping scheme approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Straggler-Resilient Differentially-Private Decentralized Learning
Yauhen Yakimenka, Chung-Wei Weng, Hsuan-Yin Lin, Eirik Rosnes, Jorg Kliewer
We consider the straggler problem in decentralized learning over a logical ring while preserving user data privacy. Especially, we extend the recently proposed framework of differential privacy (DP) amplification by decentralization by Cyffers and Bellet to include overall training latency--comprising both computation and communication latency. Analytical results on both the convergence speed and the DP level are derived for both a skipping scheme (which ignores the stragglers after a timeout) and a baseline scheme that waits for each node to finish before the training continues. A trade-off between overall training latency, accuracy, and privacy, parameterized by the timeout of the skipping scheme, is identified and empirically validated for logistic regression on a real-world dataset and for image classification using the MNIST and CIFAR-10 datasets.
Read more7/1/2024

0
Straggler-Resilient Decentralized Learning via Adaptive Asynchronous Updates
Guojun Xiong, Gang Yan, Shiqiang Wang, Jian Li
With the increasing demand for large-scale training of machine learning models, fully decentralized optimization methods have recently been advocated as alternatives to the popular parameter server framework. In this paradigm, each worker maintains a local estimate of the optimal parameter vector, and iteratively updates it by waiting and averaging all estimates obtained from its neighbors, and then corrects it on the basis of its local dataset. However, the synchronization phase is sensitive to stragglers. An efficient way to mitigate this effect is to consider asynchronous updates, where each worker computes stochastic gradients and communicates with other workers at its own pace. Unfortunately, fully asynchronous updates suffer from staleness of stragglers' parameters. To address these limitations, we propose a fully decentralized algorithm DSGD-AAU with adaptive asynchronous updates via adaptively determining the number of neighbor workers for each worker to communicate with. We show that DSGD-AAU achieves a linear speedup for convergence and demonstrate its effectiveness via extensive experiments.
Read more7/10/2024
0
Gradient Coding in Decentralized Learning for Evading Stragglers
Chengxi Li, Mikael Skoglund
In this paper, we consider a decentralized learning problem in the presence of stragglers. Although gradient coding techniques have been developed for distributed learning to evade stragglers, where the devices send encoded gradients with redundant training data, it is difficult to apply those techniques directly to decentralized learning scenarios. To deal with this problem, we propose a new gossip-based decentralized learning method with gradient coding (GOCO). In the proposed method, to avoid the negative impact of stragglers, the parameter vectors are updated locally using encoded gradients based on the framework of stochastic gradient coding and then averaged in a gossip-based manner. We analyze the convergence performance of GOCO for strongly convex loss functions. And we also provide simulation results to demonstrate the superiority of the proposed method in terms of learning performance compared with the baseline methods.
Read more6/17/2024
🏅
0
Locally Differentially Private Distributed Online Learning with Guaranteed Optimality
Ziqin Chen, Yongqiang Wang
Distributed online learning is gaining increased traction due to its unique ability to process large-scale datasets and streaming data. To address the growing public awareness and concern on privacy protection, plenty of algorithms have been proposed to enable differential privacy in distributed online optimization and learning. However, these algorithms often face the dilemma of trading learning accuracy for privacy. By exploiting the unique characteristics of online learning, this paper proposes an approach that tackles the dilemma and ensures both differential privacy and learning accuracy in distributed online learning. More specifically, while ensuring a diminishing expected instantaneous regret, the approach can simultaneously ensure a finite cumulative privacy budget, even in the infinite time horizon. To cater for the fully distributed setting, we adopt the local differential-privacy framework, which avoids the reliance on a trusted data curator that is required in the classic centralized (global) differential-privacy framework. To the best of our knowledge, this is the first algorithm that successfully ensures both rigorous local differential privacy and learning accuracy. The effectiveness of the proposed algorithm is evaluated using machine learning tasks, including logistic regression on the the mushrooms datasets and CNN-based image classification on the MNIST and CIFAR-10 datasets.
Read more8/27/2024