xLSTMTime : Long-term Time Series Forecasting With xLSTM

628
⛏️
Sign in to get full access
Overview
- Transformer-based models have gained prominence in multivariate long-term time series forecasting (LTSF), but face challenges like high computational demands and difficulty capturing temporal dynamics.
- LTSF-Linear, a model with a straightforward linear architecture, has outperformed transformer-based counterparts, prompting a reevaluation of transformers in time series forecasting.
- This paper presents an adaptation of the extended LSTM (xLSTM) architecture, called xLSTMTime, for LTSF tasks.
- xLSTMTime incorporates exponential gating and a revised memory structure to improve performance on LTSF.
Plain English Explanation
Time series forecasting is the task of predicting future values based on past data. It's an important problem with applications in fields like finance, energy, and logistics. In recent years, transformer-based models have become popular for this task, but they can be computationally intensive and struggle to capture long-term patterns in the data.
Interestingly, a simpler model called LTSF-Linear [https://aimodels.fyi/papers/arxiv/boosting-x-formers-structured-matrix-long-sequence] has been shown to outperform these more complex transformer-based approaches. This suggests that the transformer architecture may not be the best fit for time series forecasting after all.
In response, the researchers in this paper propose a modified version of a recurrent neural network called the extended LSTM (xLSTM) [https://aimodels.fyi/papers/arxiv/xlstm-extended-long-short-term-memory, https://aimodels.fyi/papers/arxiv/vision-lstm-xlstm-as-generic-vision-backbone]. The key changes are the addition of exponential gating and a revised memory structure, which the researchers believe will help the model better capture the temporal dynamics in time series data.
The resulting model, called xLSTMTime, is evaluated on several real-world datasets and shown to outperform state-of-the-art transformer-based and recurrent models. This suggests that refined recurrent architectures like xLSTMTime can be competitive alternatives to transformers for time series forecasting tasks.
Technical Explanation
The paper starts by highlighting the challenges that transformer-based models face in multivariate long-term time series forecasting (LTSF), including high computational demands and difficulty capturing temporal dynamics and long-term dependencies. The authors note that the emergence of the LTSF-Linear model, with its straightforward linear architecture, has outperformed transformer-based counterparts, motivating a reevaluation of the transformer's utility in this domain.
In response, the researchers propose an adaptation of the extended LSTM (xLSTM) architecture, termed xLSTMTime, for LTSF tasks. xLSTM incorporates exponential gating and a revised memory structure that the authors believe has good potential for LTSF [https://aimodels.fyi/papers/arxiv/understanding-different-design-choices-training-large-time, https://aimodels.fyi/papers/arxiv/leveraging-2d-information-long-term-time-series].
The paper presents a detailed comparison of xLSTMTime's performance against various state-of-the-art models, including transformer-based and recurrent approaches, across multiple real-world datasets. The results demonstrate that xLSTMTime outperforms these existing methods, suggesting that refined recurrent architectures can offer competitive alternatives to transformers in LTSF tasks.
Critical Analysis
The paper provides a compelling case for the potential of refined recurrent models like xLSTMTime in the domain of long-term time series forecasting. By incorporating specific architectural changes, the authors have been able to develop a model that can outperform more complex transformer-based approaches.
However, the paper does not delve into the potential limitations or caveats of the xLSTMTime model. It would be helpful to understand the computational requirements of the model, as well as any potential trade-offs in terms of training time or model complexity. Additionally, the researchers could have explored the interpretability of the xLSTMTime architecture and how it compares to the black-box nature of transformer models.
Further research could also investigate the performance of xLSTMTime on a wider range of time series datasets, including those with different characteristics, to better understand the model's generalizability. Exploring the model's robustness to missing data or handling of multivariate inputs could also be valuable avenues for future work.
Conclusion
This paper presents a promising adaptation of the extended LSTM (xLSTM) architecture, called xLSTMTime, for the task of multivariate long-term time series forecasting. By incorporating exponential gating and a revised memory structure, the authors have developed a model that outperforms state-of-the-art transformer-based and recurrent approaches across multiple real-world datasets.
The findings suggest that refined recurrent models can offer competitive alternatives to transformer-based architectures in time series forecasting tasks, potentially redefining the landscape of this important field. As the research community continues to explore the strengths and limitations of different modeling approaches, the xLSTMTime architecture could serve as a valuable contribution to the ongoing advancements in time series forecasting.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
628
xLSTMTime : Long-term Time Series Forecasting With xLSTM
Musleh Alharthi, Ausif Mahmood
In recent years, transformer-based models have gained prominence in multivariate long-term time series forecasting (LTSF), demonstrating significant advancements despite facing challenges such as high computational demands, difficulty in capturing temporal dynamics, and managing long-term dependencies. The emergence of LTSF-Linear, with its straightforward linear architecture, has notably outperformed transformer-based counterparts, prompting a reevaluation of the transformer's utility in time series forecasting. In response, this paper presents an adaptation of a recent architecture termed extended LSTM (xLSTM) for LTSF. xLSTM incorporates exponential gating and a revised memory structure with higher capacity that has good potential for LTSF. Our adopted architecture for LTSF termed as xLSTMTime surpasses current approaches. We compare xLSTMTime's performance against various state-of-the-art models across multiple real-world da-tasets, demonstrating superior forecasting capabilities. Our findings suggest that refined recurrent architectures can offer competitive alternatives to transformer-based models in LTSF tasks, po-tentially redefining the landscape of time series forecasting.
Read more8/13/2024

1
Unlocking the Power of LSTM for Long Term Time Series Forecasting
Yaxuan Kong, Zepu Wang, Yuqi Nie, Tian Zhou, Stefan Zohren, Yuxuan Liang, Peng Sun, Qingsong Wen
Traditional recurrent neural network architectures, such as long short-term memory neural networks (LSTM), have historically held a prominent role in time series forecasting (TSF) tasks. While the recently introduced sLSTM for Natural Language Processing (NLP) introduces exponential gating and memory mixing that are beneficial for long term sequential learning, its potential short memory issue is a barrier to applying sLSTM directly in TSF. To address this, we propose a simple yet efficient algorithm named P-sLSTM, which is built upon sLSTM by incorporating patching and channel independence. These modifications substantially enhance sLSTM's performance in TSF, achieving state-of-the-art results. Furthermore, we provide theoretical justifications for our design, and conduct extensive comparative and analytical experiments to fully validate the efficiency and superior performance of our model.
Read more8/20/2024
🏷️
136
xLSTM: Extended Long Short-Term Memory
Maximilian Beck, Korbinian Poppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, Gunter Klambauer, Johannes Brandstetter, Sepp Hochreiter
In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerous deep learning success stories, in particular they constituted the first Large Language Models (LLMs). However, the advent of the Transformer technology with parallelizable self-attention at its core marked the dawn of a new era, outpacing LSTMs at scale. We now raise a simple question: How far do we get in language modeling when scaling LSTMs to billions of parameters, leveraging the latest techniques from modern LLMs, but mitigating known limitations of LSTMs? Firstly, we introduce exponential gating with appropriate normalization and stabilization techniques. Secondly, we modify the LSTM memory structure, obtaining: (i) sLSTM with a scalar memory, a scalar update, and new memory mixing, (ii) mLSTM that is fully parallelizable with a matrix memory and a covariance update rule. Integrating these LSTM extensions into residual block backbones yields xLSTM blocks that are then residually stacked into xLSTM architectures. Exponential gating and modified memory structures boost xLSTM capabilities to perform favorably when compared to state-of-the-art Transformers and State Space Models, both in performance and scaling.
Read more5/8/2024
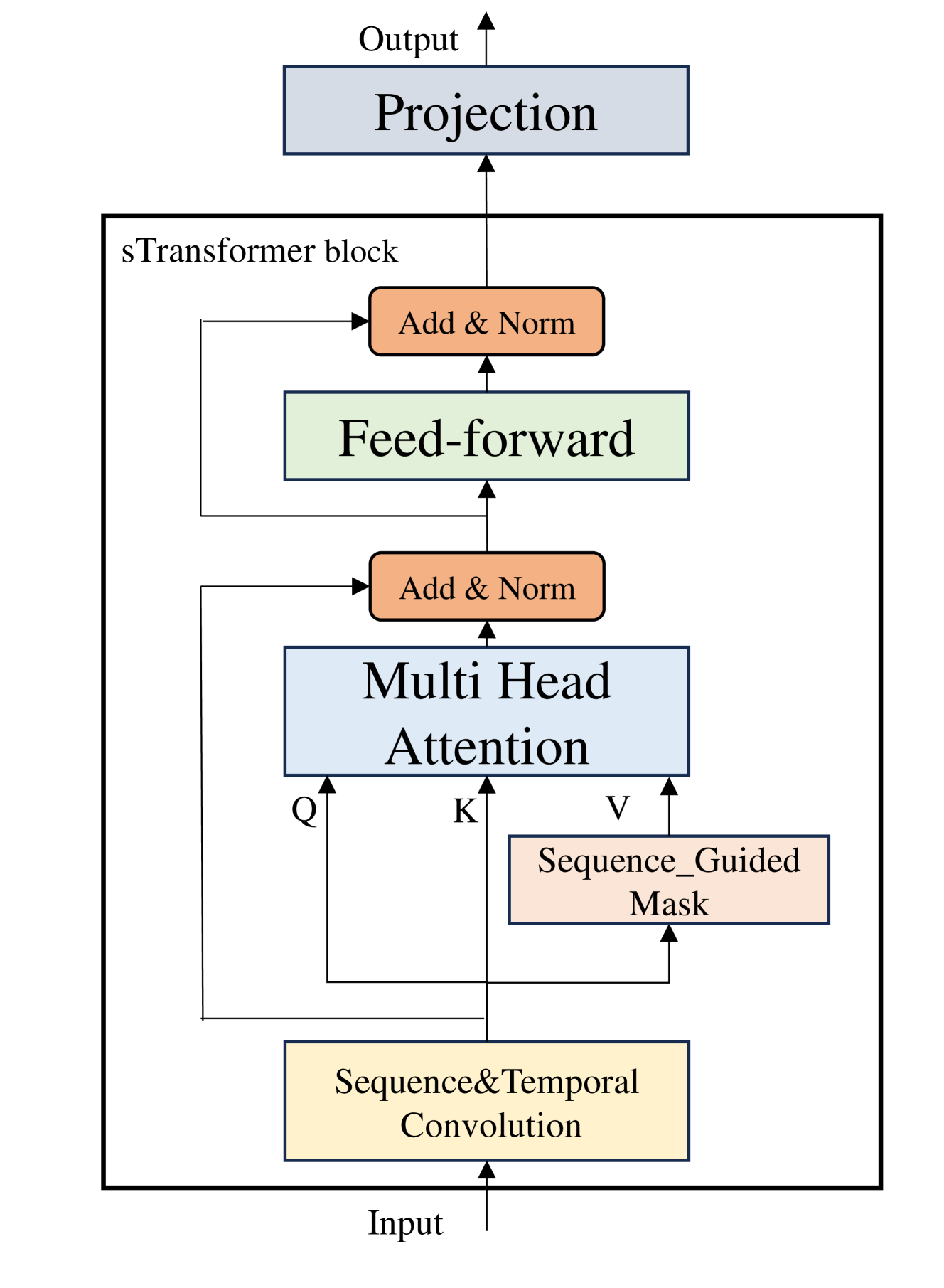
0
sTransformer: A Modular Approach for Extracting Inter-Sequential and Temporal Information for Time-Series Forecasting
Jiaheng Yin, Zhengxin Shi, Jianshen Zhang, Xiaomin Lin, Yulin Huang, Yongzhi Qi, Wei Qi
In recent years, numerous Transformer-based models have been applied to long-term time-series forecasting (LTSF) tasks. However, recent studies with linear models have questioned their effectiveness, demonstrating that simple linear layers can outperform sophisticated Transformer-based models. In this work, we review and categorize existing Transformer-based models into two main types: (1) modifications to the model structure and (2) modifications to the input data. The former offers scalability but falls short in capturing inter-sequential information, while the latter preprocesses time-series data but is challenging to use as a scalable module. We propose $textbf{sTransformer}$, which introduces the Sequence and Temporal Convolutional Network (STCN) to fully capture both sequential and temporal information. Additionally, we introduce a Sequence-guided Mask Attention mechanism to capture global feature information. Our approach ensures the capture of inter-sequential information while maintaining module scalability. We compare our model with linear models and existing forecasting models on long-term time-series forecasting, achieving new state-of-the-art results. We also conducted experiments on other time-series tasks, achieving strong performance. These demonstrate that Transformer-based structures remain effective and our model can serve as a viable baseline for time-series tasks.
Read more8/20/2024