Stratified Prediction-Powered Inference for Hybrid Language Model Evaluation

0

Sign in to get full access
Overview
- This paper presents a novel approach called "Stratified Prediction-Powered Inference" for evaluating hybrid language models.
- The method combines predictive modeling and statistical inference to provide a more robust and accurate assessment of language model performance.
- Key contributions include a stratified sampling strategy and the integration of prediction-powered techniques to enable valid statistical inferences.
Plain English Explanation
The paper introduces a new way to evaluate the performance of language models that combine different techniques, such as neural networks and traditional statistical methods. These "hybrid" language models are becoming increasingly common, but evaluating their effectiveness can be challenging.
The researchers propose a approach called "Stratified Prediction-Powered Inference" that addresses this challenge. The key idea is to use predictive modeling to guide the statistical analysis, rather than relying solely on traditional inference methods. This allows the researchers to make more accurate and reliable assessments of the language models' capabilities.
The method involves dividing the data into different "strata" or subgroups, and then using machine learning models to make predictions about the language model's performance on each stratum. This stratified approach helps to capture the nuances and complexities of language model behavior. The predictions are then used to inform the statistical analysis, providing a more robust and informative evaluation.
By combining predictive modeling and statistical inference, the researchers are able to overcome some of the limitations of traditional language model evaluation techniques. This allows them to gain deeper insights into the strengths and weaknesses of hybrid language models, which can inform the development of more effective and reliable systems.
Technical Explanation
The paper presents a novel approach called "Stratified Prediction-Powered Inference" for evaluating hybrid language models. The key elements of the method are:
-
Stratified Sampling: The researchers divide the data into different "strata" or subgroups based on relevant characteristics, such as the complexity or difficulty of the language tasks.
-
Predictive Modeling: They then use machine learning models to make predictions about the language model's performance on each stratum. This could involve, for example, predicting the accuracy or perplexity of the language model on different types of texts.
-
Prediction-Powered Inference: The researchers use the predictions from the machine learning models to inform the statistical analysis of the language model's performance. This allows them to make more accurate and reliable inferences about the language model's capabilities.
The paper demonstrates the effectiveness of this approach through experiments on various language tasks and datasets. The results show that the Stratified Prediction-Powered Inference method outperforms traditional evaluation techniques, providing a more nuanced and informative assessment of hybrid language models.
Critical Analysis
The paper presents a well-designed and rigorous approach to evaluating hybrid language models. The key strengths of the Stratified Prediction-Powered Inference method are its ability to capture the nuances of language model behavior and its use of predictive modeling to enhance the statistical analysis.
However, the paper does acknowledge some limitations and areas for further research. For example, the performance of the predictive models may be affected by the quality and representativeness of the training data, and the choice of stratification criteria could also influence the results.
Additionally, while the paper demonstrates the effectiveness of the method on a range of language tasks, it would be valuable to see how it performs on even more diverse and challenging datasets. Further exploration of the method's generalizability and its ability to handle different types of language models would strengthen the research.
Overall, the Stratified Prediction-Powered Inference approach is a promising and innovative contribution to the field of language model evaluation. By integrating predictive modeling and statistical inference, the researchers have developed a more robust and informative way to assess the capabilities of hybrid language models.
Conclusion
This paper presents a novel approach called "Stratified Prediction-Powered Inference" for evaluating hybrid language models. The key idea is to combine predictive modeling and statistical inference to provide a more nuanced and accurate assessment of language model performance.
The method involves dividing the data into different strata or subgroups, using machine learning models to make predictions about the language model's performance on each stratum, and then using those predictions to inform the statistical analysis. This stratified approach and the integration of predictive modeling enable the researchers to overcome some of the limitations of traditional language model evaluation techniques.
The paper demonstrates the effectiveness of this approach through experiments on various language tasks and datasets, showing that the Stratified Prediction-Powered Inference method outperforms traditional evaluation methods. While the paper acknowledges some limitations and areas for further research, the overall contribution represents a significant advancement in the field of language model evaluation, with potential implications for the development of more effective and reliable hybrid language systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Stratified Prediction-Powered Inference for Hybrid Language Model Evaluation
Adam Fisch, Joshua Maynez, R. Alex Hofer, Bhuwan Dhingra, Amir Globerson, William W. Cohen
Prediction-powered inference (PPI) is a method that improves statistical estimates based on limited human-labeled data. PPI achieves this by combining small amounts of human-labeled data with larger amounts of data labeled by a reasonably accurate -- but potentially biased -- automatic system, in a way that results in tighter confidence intervals for certain parameters of interest (e.g., the mean performance of a language model). In this paper, we propose a method called Stratified Prediction-Powered Inference (StratPPI), in which we show that the basic PPI estimates can be considerably improved by employing simple data stratification strategies. Without making any assumptions on the underlying automatic labeling system or data distribution, we derive an algorithm for computing provably valid confidence intervals for population parameters (such as averages) that is based on stratified sampling. In particular, we show both theoretically and empirically that, with appropriate choices of stratification and sample allocation, our approach can provide substantially tighter confidence intervals than unstratified approaches. Specifically, StratPPI is expected to improve in cases where the performance of the autorater varies across different conditional distributions of the target data.
Read more6/7/2024
🤯
0
Bayesian Prediction-Powered Inference
R. Alex Hofer, Joshua Maynez, Bhuwan Dhingra, Adam Fisch, Amir Globerson, William W. Cohen
Prediction-powered inference (PPI) is a method that improves statistical estimates based on limited human-labeled data. Specifically, PPI methods provide tighter confidence intervals by combining small amounts of human-labeled data with larger amounts of data labeled by a reasonably accurate, but potentially biased, automatic system. We propose a framework for PPI based on Bayesian inference that allows researchers to develop new task-appropriate PPI methods easily. Exploiting the ease with which we can design new metrics, we propose improved PPI methods for several importantcases, such as autoraters that give discrete responses (e.g., prompted LLM ``judges'') and autoraters with scores that have a non-linear relationship to human scores.
Read more5/13/2024
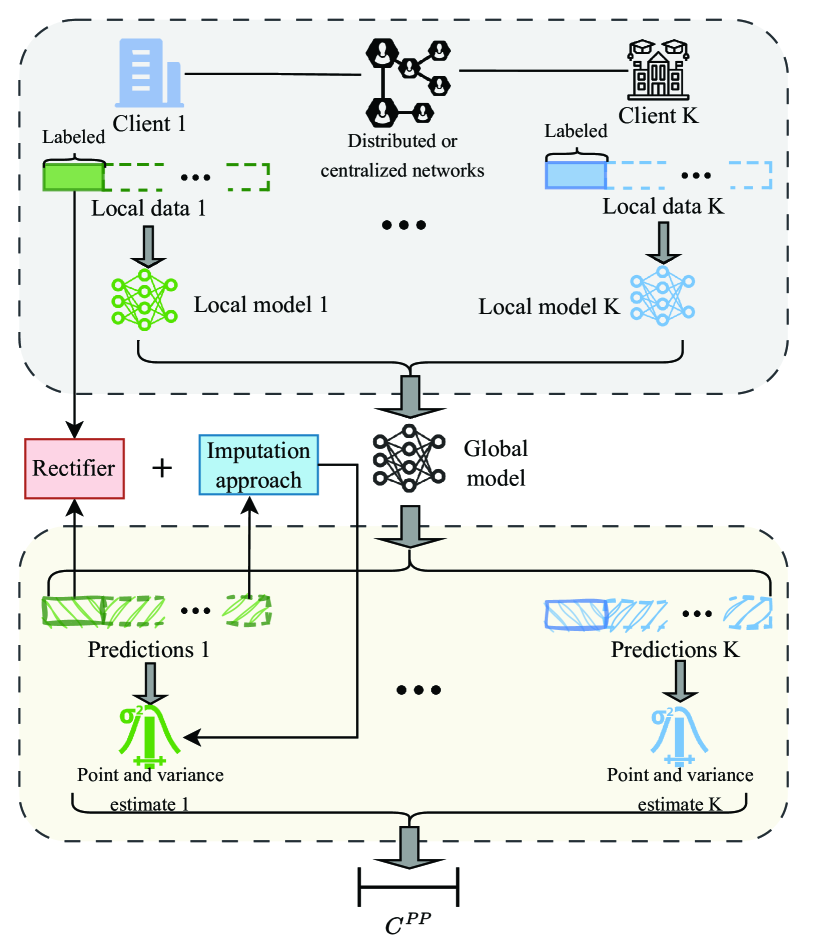
0
Federated Prediction-Powered Inference from Decentralized Data
Ping Luo, Xiaoge Deng, Ziqing Wen, Tao Sun, Dongsheng Li
In various domains, the increasing application of machine learning allows researchers to access inexpensive predictive data, which can be utilized as auxiliary data for statistical inference. Although such data are often unreliable compared to gold-standard datasets, Prediction-Powered Inference (PPI) has been proposed to ensure statistical validity despite the unreliability. However, the challenge of `data silos' arises when the private gold-standard datasets are non-shareable for model training, leading to less accurate predictive models and invalid inferences. In this paper, we introduces the Federated Prediction-Powered Inference (Fed-PPI) framework, which addresses this challenge by enabling decentralized experimental data to contribute to statistically valid conclusions without sharing private information. The Fed-PPI framework involves training local models on private data, aggregating them through Federated Learning (FL), and deriving confidence intervals using PPI computation. The proposed framework is evaluated through experiments, demonstrating its effectiveness in producing valid confidence intervals.
Read more9/4/2024
🤯
0
New!Local Prediction-Powered Inference
Yanwu Gu, Dong Xia
To infer a function value on a specific point $x$, it is essential to assign higher weights to the points closer to $x$, which is called local polynomial / multivariable regression. In many practical cases, a limited sample size may ruin this method, but such conditions can be improved by the Prediction-Powered Inference (PPI) technique. This paper introduced a specific algorithm for local multivariable regression using PPI, which can significantly reduce the variance of estimations without enlarge the error. The confidence intervals, bias correction, and coverage probabilities are analyzed and proved the correctness and superiority of our algorithm. Numerical simulation and real-data experiments are applied and show these conclusions. Another contribution compared to PPI is the theoretical computation efficiency and explainability by taking into account the dependency of the dependent variable.
Read more9/30/2024