Street TryOn: Learning In-the-Wild Virtual Try-On from Unpaired Person Images
2311.16094
0
0
Abstract
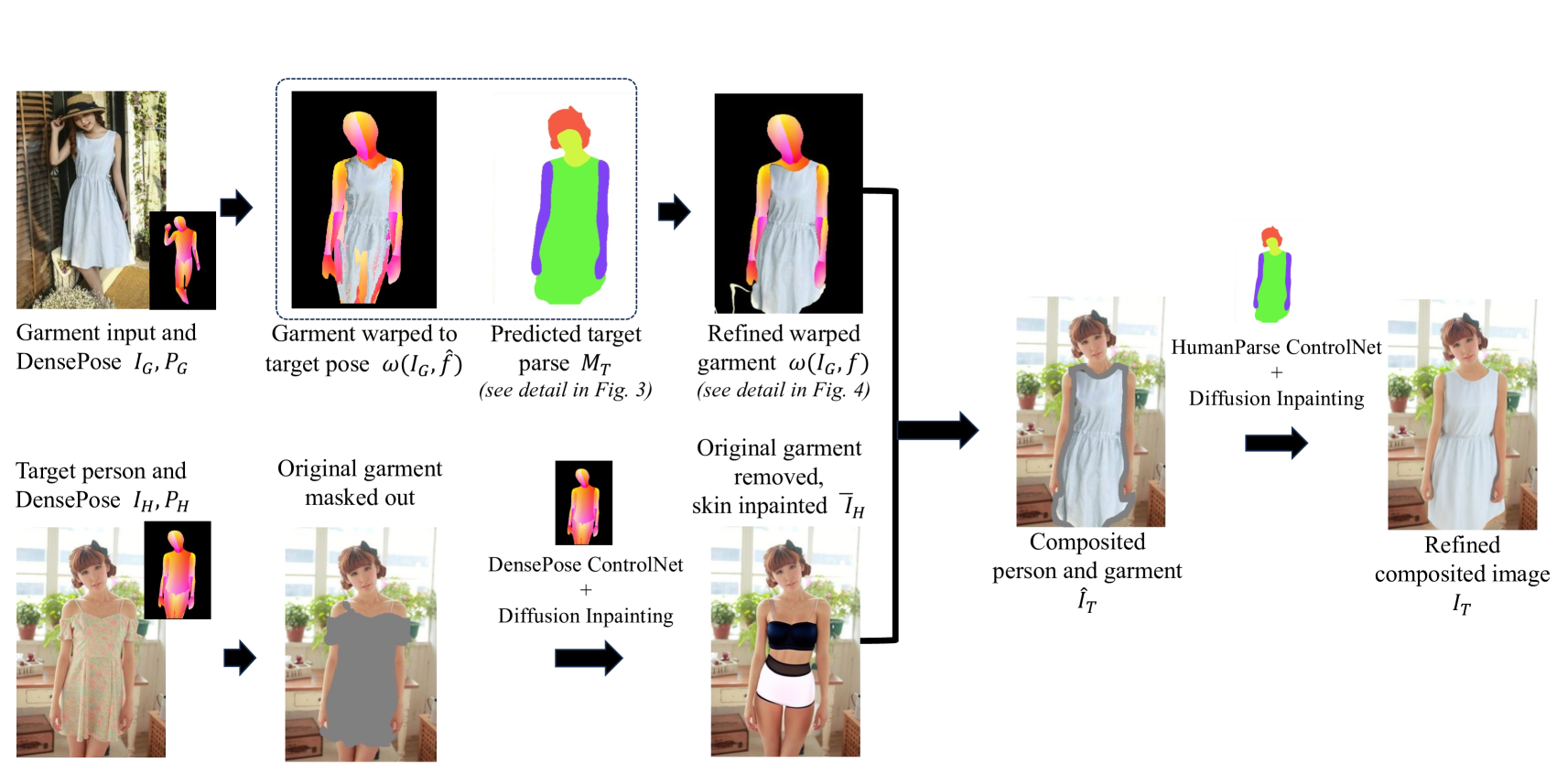
Most existing methods for virtual try-on focus on studio person images with a limited range of poses and clean backgrounds. They can achieve plausible results for this studio try-on setting by learning to warp a garment image to fit a person's body from paired training data, i.e., garment images paired with images of people wearing the same garment. Such data is often collected from commercial websites, where each garment is demonstrated both by itself and on several models. By contrast, it is hard to collect paired data for in-the-wild scenes, and therefore, virtual try-on for casual images of people with more diverse poses against cluttered backgrounds is rarely studied. In this work, we fill the gap by introducing a StreetTryOn benchmark to evaluate in-the-wild virtual try-on performance and proposing a novel method that can learn it without paired data, from a set of in-the-wild person images directly. Our method achieves robust performance across shop and street domains using a novel DensePose warping correction method combined with diffusion-based conditional inpainting. Our experiments show competitive performance for standard studio try-on tasks and SOTA performance for street try-on and cross-domain try-on tasks.
Create account to get full access
Overview
- This paper presents "StreetTryOn", a novel virtual try-on system that allows users to try on clothing from unpaired person images in the wild.
- The system uses a generative adversarial network (GAN) to transfer garments from a reference image to a target person image, while preserving the person's identity and clothing details.
- The researchers introduce the StreetTryOn benchmark, a large-scale dataset of in-the-wild person images, to train and evaluate their virtual try-on system.
Plain English Explanation
The researchers have developed a way for people to virtually try on clothes without having to physically wear them. Their system, called "StreetTryOn", takes an image of a person and an image of a piece of clothing, and then puts the clothing onto the person in the image. This is done using a type of artificial intelligence called a generative adversarial network (GAN), which learns to transfer the clothing from one image to the other while keeping the person's identity and other details intact.
To train and test their system, the researchers created a new dataset called the "StreetTryOn benchmark". This dataset contains a large number of real-world images of people and clothing, which the researchers use to teach their AI system how to do the virtual try-on. [This is similar to the approach used in other computer vision tasks, like 3D human reconstruction from the wild and 3D reconstruction of interacting multi-person clothing.]
The key innovation of StreetTryOn is that it can work with any pair of person and clothing images, without needing any special setup or markers. This makes it much more practical for real-world use, where people can simply take photos of themselves and the clothes they want to try on, and the system will do the rest.
Technical Explanation
The StreetTryOn system uses a conditional GAN architecture to transfer garments from a reference clothing image to a target person image. The generator network learns to synthesize the person with the transferred garment, while the discriminator network learns to distinguish real from generated images.
To enable this, the researchers introduce several key technical contributions:
- Unpaired Image-to-Image Translation: StreetTryOn can perform virtual try-on between any pair of person and clothing images, without requiring them to be matched beforehand.
- Geometry-Aware Garment Transfer: The system preserves the person's body shape and pose when transferring the garment, ensuring a realistic try-on result.
- Identity-Preserving Synthesis: The generated images maintain the person's identity and facial features, even when transferring prominent garments like hats or sunglasses.
The StreetTryOn benchmark dataset contains over 200,000 in-the-wild person images and over 20,000 clothing images, providing a diverse and challenging testbed for virtual try-on systems. Experiments show that StreetTryOn outperforms previous state-of-the-art methods on both qualitative and quantitative metrics.
Critical Analysis
The StreetTryOn system represents a significant advancement in virtual try-on technology, as it can work with unpaired images captured in the real world, rather than requiring specialized setups or markers. This makes it much more practical for consumer-facing applications, where users can simply take photos of themselves and the clothes they want to try on.
However, the paper does not address some potential limitations of the system. For example, it is unclear how well StreetTryOn would handle highly occluded or partially visible persons, or how it would perform on more complex garments like dresses or suits. Additionally, the system may struggle with accurately transferring the appearance and details of certain fabrics or patterns.
Further research could explore ways to improve the system's robustness, such as by incorporating more advanced 3D modeling techniques like those used in ShoeModel or leveraging additional data sources beyond the StreetTryOn benchmark. It would also be interesting to see how the system could be extended to handle dynamic try-on, where users could virtually see the clothing in motion.
Conclusion
The StreetTryOn system represents a significant step forward in virtual try-on technology, enabling users to try on clothes from unpaired person and clothing images captured in the real world. By introducing a novel GAN-based architecture and a large-scale benchmark dataset, the researchers have laid the groundwork for more practical and accessible virtual try-on experiences. While the system has some limitations, the techniques developed in this paper could have widespread applications in the fashion and e-commerce industries, as well as broader implications for computer vision and image synthesis tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
Image-Based Virtual Try-On: A Survey
Dan Song, Xuanpu Zhang, Juan Zhou, Weizhi Nie, Ruofeng Tong, Mohan Kankanhalli, An-An Liu
0
0
Image-based virtual try-on aims to synthesize a naturally dressed person image with a clothing image, which revolutionizes online shopping and inspires related topics within image generation, showing both research significance and commercial potential. However, there is a gap between current research progress and commercial applications and an absence of comprehensive overview of this field to accelerate the development. In this survey, we provide a comprehensive analysis of the state-of-the-art techniques and methodologies in aspects of pipeline architecture, person representation and key modules such as try-on indication, clothing warping and try-on stage. We propose a new semantic criteria with CLIP, and evaluate representative methods with uniformly implemented evaluation metrics on the same dataset. In addition to quantitative and qualitative evaluation of current open-source methods, unresolved issues are highlighted and future research directions are prospected to identify key trends and inspire further exploration. The uniformly implemented evaluation metrics, dataset and collected methods will be made public available at https://github.com/little-misfit/Survey-Of-Virtual-Try-On.
5/2/2024
✨
Single Stage Warped Cloth Learning and Semantic-Contextual Attention Feature Fusion for Virtual TryOn
Sanhita Pathak, Vinay Kaushik, Brejesh Lall
0
0
Image-based virtual try-on aims to fit an in-shop garment onto a clothed person image. Garment warping, which aligns the target garment with the corresponding body parts in the person image, is a crucial step in achieving this goal. Existing methods often use multi-stage frameworks to handle clothes warping, person body synthesis and tryon generation separately or rely on noisy intermediate parser-based labels. We propose a novel single-stage framework that implicitly learns the same without explicit multi-stage learning. Our approach utilizes a novel semantic-contextual fusion attention module for garment-person feature fusion, enabling efficient and realistic cloth warping and body synthesis from target pose keypoints. By introducing a lightweight linear attention framework that attends to garment regions and fuses multiple sampled flow fields, we also address misalignment and artifacts present in previous methods. To achieve simultaneous learning of warped garment and try-on results, we introduce a Warped Cloth Learning Module. Our proposed approach significantly improves the quality and efficiency of virtual try-on methods, providing users with a more reliable and realistic virtual try-on experience.
5/28/2024
👀
ViViD: Video Virtual Try-on using Diffusion Models
Zixun Fang, Wei Zhai, Aimin Su, Hongliang Song, Kai Zhu, Mao Wang, Yu Chen, Zhiheng Liu, Yang Cao, Zheng-Jun Zha
0
0
Video virtual try-on aims to transfer a clothing item onto the video of a target person. Directly applying the technique of image-based try-on to the video domain in a frame-wise manner will cause temporal-inconsistent outcomes while previous video-based try-on solutions can only generate low visual quality and blurring results. In this work, we present ViViD, a novel framework employing powerful diffusion models to tackle the task of video virtual try-on. Specifically, we design the Garment Encoder to extract fine-grained clothing semantic features, guiding the model to capture garment details and inject them into the target video through the proposed attention feature fusion mechanism. To ensure spatial-temporal consistency, we introduce a lightweight Pose Encoder to encode pose signals, enabling the model to learn the interactions between clothing and human posture and insert hierarchical Temporal Modules into the text-to-image stable diffusion model for more coherent and lifelike video synthesis. Furthermore, we collect a new dataset, which is the largest, with the most diverse types of garments and the highest resolution for the task of video virtual try-on to date. Extensive experiments demonstrate that our approach is able to yield satisfactory video try-on results. The dataset, codes, and weights will be publicly available. Project page: https://becauseimbatman0.github.io/ViViD.
5/29/2024

Masked Extended Attention for Zero-Shot Virtual Try-On In The Wild
Nadav Orzech, Yotam Nitzan, Ulysse Mizrahi, Dov Danon, Amit H. Bermano
0
0
Virtual Try-On (VTON) is a highly active line of research, with increasing demand. It aims to replace a piece of garment in an image with one from another, while preserving person and garment characteristics as well as image fidelity. Current literature takes a supervised approach for the task, impairing generalization and imposing heavy computation. In this paper, we present a novel zero-shot training-free method for inpainting a clothing garment by reference. Our approach employs the prior of a diffusion model with no additional training, fully leveraging its native generalization capabilities. The method employs extended attention to transfer image information from reference to target images, overcoming two significant challenges. We first initially warp the reference garment over the target human using deep features, alleviating texture sticking. We then leverage the extended attention mechanism with careful masking, eliminating leakage of reference background and unwanted influence. Through a user study, qualitative, and quantitative comparison to state-of-the-art approaches, we demonstrate superior image quality and garment preservation compared unseen clothing pieces or human figures.
6/24/2024