Strictly-ID-Preserved and Controllable Accessory Advertising Image Generation
2404.04828
0
0

Abstract
Customized generative text-to-image models have the ability to produce images that closely resemble a given subject. However, in the context of generating advertising images for e-commerce scenarios, it is crucial that the generated subject's identity aligns perfectly with the product being advertised. In order to address the need for strictly-ID preserved advertising image generation, we have developed a Control-Net based customized image generation pipeline and have taken earring model advertising as an example. Our approach facilitates a seamless interaction between the earrings and the model's face, while ensuring that the identity of the earrings remains intact. Furthermore, to achieve a diverse and controllable display, we have proposed a multi-branch cross-attention architecture, which allows for control over the scale, pose, and appearance of the model, going beyond the limitations of text prompts. Our method manages to achieve fine-grained control of the generated model's face, resulting in controllable and captivating advertising effects.
Create account to get full access
Overview
- This paper presents a method for generating accessory advertising images that strictly preserve the identity of the target individual while allowing for controllable changes to the accessories.
- The proposed approach leverages a combination of generative models and control mechanisms to enable fine-grained control over the accessory elements in the generated images.
- The authors demonstrate the capabilities of their method through extensive experiments and user studies, showcasing its potential applications in personalized advertising and content creation.
Plain English Explanation
This research paper describes a new way to generate images of people with different accessories, such as jewelry, hats, or bags, while still keeping the person's identity clearly recognizable. The key idea is to use a combination of advanced machine learning models to give the creators of these images more control over the specific accessories that are shown, without changing the person's face or overall appearance.
This could be useful for applications like personalized advertising, where companies want to show you ads with products that are tailored to your individual style and preferences. It could also help with creating custom clothing or accessory designs that look natural on a specific person.
The researchers tested their method extensively and found that it was able to generate high-quality images where the person's identity was clearly preserved, while also allowing for a good degree of control over the accessory elements. This suggests that their approach could be a valuable tool for various multimedia and content creation applications that require this kind of fine-grained control and personalization.
Technical Explanation
The core of the proposed method is a generative model that can produce accessory-augmented images of a target individual, while strictly preserving their identity. This is achieved through a combination of techniques, including Control-Net and Strictly-ID-Preserved components.
The Control-Net module allows for fine-grained control over the generated accessories, enabling the user to specify the desired attributes and placement of the accessory elements. This is combined with a Strictly-ID-Preserved component that ensures the target individual's identity is maintained throughout the image generation process.
The authors evaluate their method through extensive experiments, including user studies and comparisons to state-of-the-art approaches. The results demonstrate the effectiveness of their technique in generating high-quality, identity-preserving accessory-augmented images with a high degree of controllability.
Critical Analysis
The paper presents a compelling approach to the challenge of generating personalized accessory-augmented images while preserving individual identity. However, some potential limitations and areas for further research are worth considering:
-
The method's performance and generalization capabilities may be influenced by the diversity and quality of the training data used. Further exploration of dataset curation and augmentation techniques could help improve the model's robustness.
-
The paper does not delve into potential ethical considerations, such as the implications of using such technology for personalized advertising or content creation. Addressing these concerns could strengthen the overall contribution of the research.
-
While the authors demonstrate the controllability of the accessory elements, the extent to which users can customize the appearance and placement of these accessories could be further investigated. Incorporating more advanced control mechanisms, such as multimodal adaptation, may enhance the user experience and versatility of the system.
Overall, the paper presents a compelling technical solution to a relevant problem in the field of generative modeling and personalized content creation. Addressing the identified limitations and ethical considerations could further strengthen the impact and real-world applicability of this research.
Conclusion
This paper introduces a novel approach for generating accessory-augmented images that strictly preserve the identity of the target individual while allowing for a high degree of control over the accessory elements. The proposed method, which combines generative models and control mechanisms, demonstrates promising results in terms of image quality, identity preservation, and customizability.
The potential applications of this technology span various domains, including personalized advertising, virtual try-on, and content creation. By enabling fine-grained control over accessory elements while maintaining individual identity, this research contributes to the ongoing efforts to develop more personalized and user-centric multimedia experiences.
As the field of generative modeling continues to evolve, this work highlights the importance of balancing identity preservation with creative expression and control. Further exploration of the ethical implications and user experience aspects of such technologies could help ensure their responsible development and deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Towards a Simultaneous and Granular Identity-Expression Control in Personalized Face Generation
Renshuai Liu, Bowen Ma, Wei Zhang, Zhipeng Hu, Changjie Fan, Tangjie Lv, Yu Ding, Xuan Cheng
0
0
In human-centric content generation, the pre-trained text-to-image models struggle to produce user-wanted portrait images, which retain the identity of individuals while exhibiting diverse expressions. This paper introduces our efforts towards personalized face generation. To this end, we propose a novel multi-modal face generation framework, capable of simultaneous identity-expression control and more fine-grained expression synthesis. Our expression control is so sophisticated that it can be specialized by the fine-grained emotional vocabulary. We devise a novel diffusion model that can undertake the task of simultaneously face swapping and reenactment. Due to the entanglement of identity and expression, it's nontrivial to separately and precisely control them in one framework, thus has not been explored yet. To overcome this, we propose several innovative designs in the conditional diffusion model, including balancing identity and expression encoder, improved midpoint sampling, and explicitly background conditioning. Extensive experiments have demonstrated the controllability and scalability of the proposed framework, in comparison with state-of-the-art text-to-image, face swapping, and face reenactment methods.
4/9/2024

VirtualModel: Generating Object-ID-retentive Human-object Interaction Image by Diffusion Model for E-commerce Marketing
Binghui Chen, Chongyang Zhong, Wangmeng Xiang, Yifeng Geng, Xuansong Xie
0
0
Due to the significant advances in large-scale text-to-image generation by diffusion model (DM), controllable human image generation has been attracting much attention recently. Existing works, such as Controlnet [36], T2I-adapter [20] and HumanSD [10] have demonstrated good abilities in generating human images based on pose conditions, they still fail to meet the requirements of real e-commerce scenarios. These include (1) the interaction between the shown product and human should be considered, (2) human parts like face/hand/arm/foot and the interaction between human model and product should be hyper-realistic, and (3) the identity of the product shown in advertising should be exactly consistent with the product itself. To this end, in this paper, we first define a new human image generation task for e-commerce marketing, i.e., Object-ID-retentive Human-object Interaction image Generation (OHG), and then propose a VirtualModel framework to generate human images for product shown, which supports displays of any categories of products and any types of human-object interaction. As shown in Figure 1, VirtualModel not only outperforms other methods in terms of accurate pose control and image quality but also allows for the display of user-specified product objects by maintaining the product-ID consistency and enhancing the plausibility of human-object interaction. Codes and data will be released.
5/17/2024
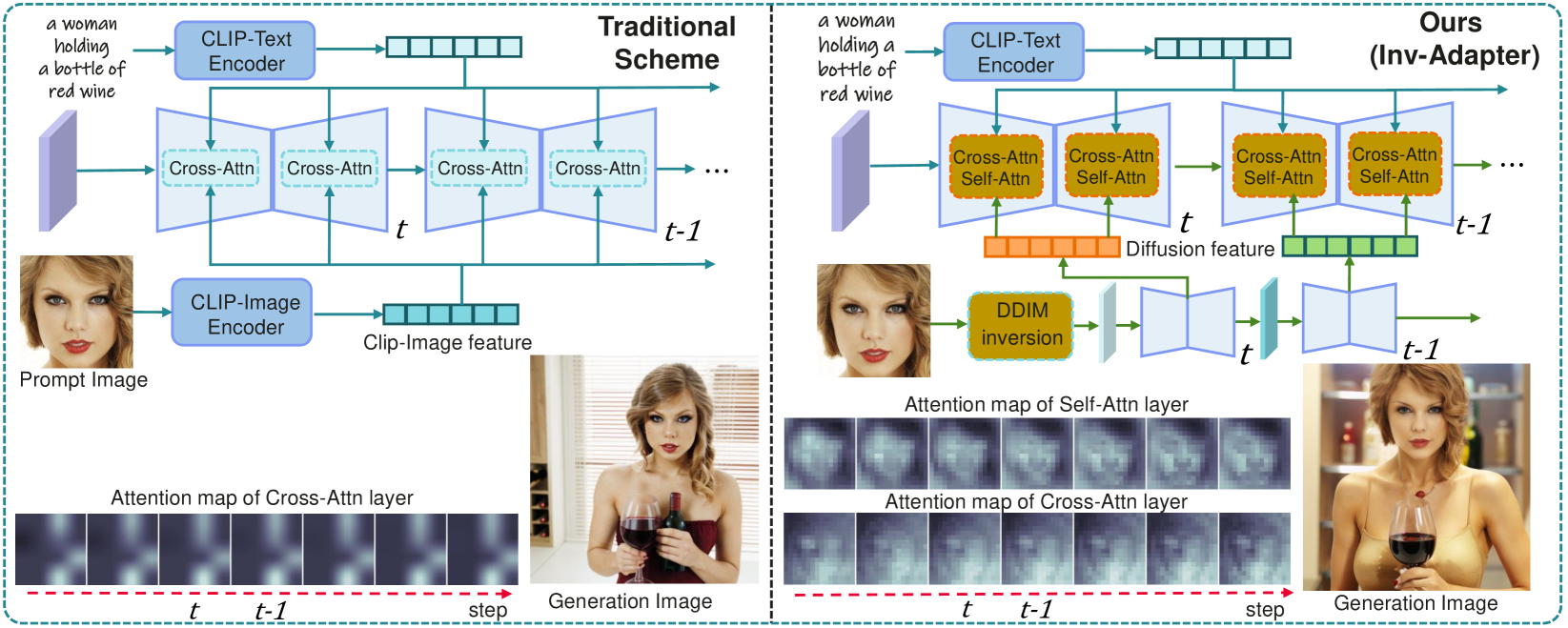
Inv-Adapter: ID Customization Generation via Image Inversion and Lightweight Adapter
Peng Xing, Ning Wang, Jianbo Ouyang, Zechao Li
0
0
The remarkable advancement in text-to-image generation models significantly boosts the research in ID customization generation. However, existing personalization methods cannot simultaneously satisfy high fidelity and high-efficiency requirements. Their main bottleneck lies in the prompt image encoder, which produces weak alignment signals with the text-to-image model and significantly increased model size. Towards this end, we propose a lightweight Inv-Adapter, which first extracts diffusion-domain representations of ID images utilizing a pre-trained text-to-image model via DDIM image inversion, without additional image encoder. Benefiting from the high alignment of the extracted ID prompt features and the intermediate features of the text-to-image model, we then embed them efficiently into the base text-to-image model by carefully designing a lightweight attention adapter. We conduct extensive experiments to assess ID fidelity, generation loyalty, speed, and training parameters, all of which show that the proposed Inv-Adapter is highly competitive in ID customization generation and model scale.
6/7/2024

Patch-enhanced Mask Encoder Prompt Image Generation
Shusong Xu, Peiye Liu
0
0
Artificial Intelligence Generated Content(AIGC), known for its superior visual results, represents a promising mitigation method for high-cost advertising applications. Numerous approaches have been developed to manipulate generated content under different conditions. However, a crucial limitation lies in the accurate description of products in advertising applications. Applying previous methods directly may lead to considerable distortion and deformation of advertised products, primarily due to oversimplified content control conditions. Hence, in this work, we propose a patch-enhanced mask encoder approach to ensure accurate product descriptions while preserving diverse backgrounds. Our approach consists of three components Patch Flexible Visibility, Mask Encoder Prompt Adapter and an image Foundation Model. Patch Flexible Visibility is used for generating a more reasonable background image. Mask Encoder Prompt Adapter enables region-controlled fusion. We also conduct an analysis of the structure and operational mechanisms of the Generation Module. Experimental results show our method can achieve the highest visual results and FID scores compared with other methods.
5/30/2024