Inv-Adapter: ID Customization Generation via Image Inversion and Lightweight Adapter

0
Sign in to get full access
Overview
- This paper introduces Inv-Adapter, a method for generating personalized ID images by inverting pre-trained image generation models and using lightweight adapters.
- The key innovation is the use of image inversion and lightweight adapter networks to enable ID customization without retraining the entire model.
- The authors demonstrate that Inv-Adapter can generate high-quality personalized ID images across different image generation models, including LocinV, Customization Assistant, and IterInv.
Plain English Explanation
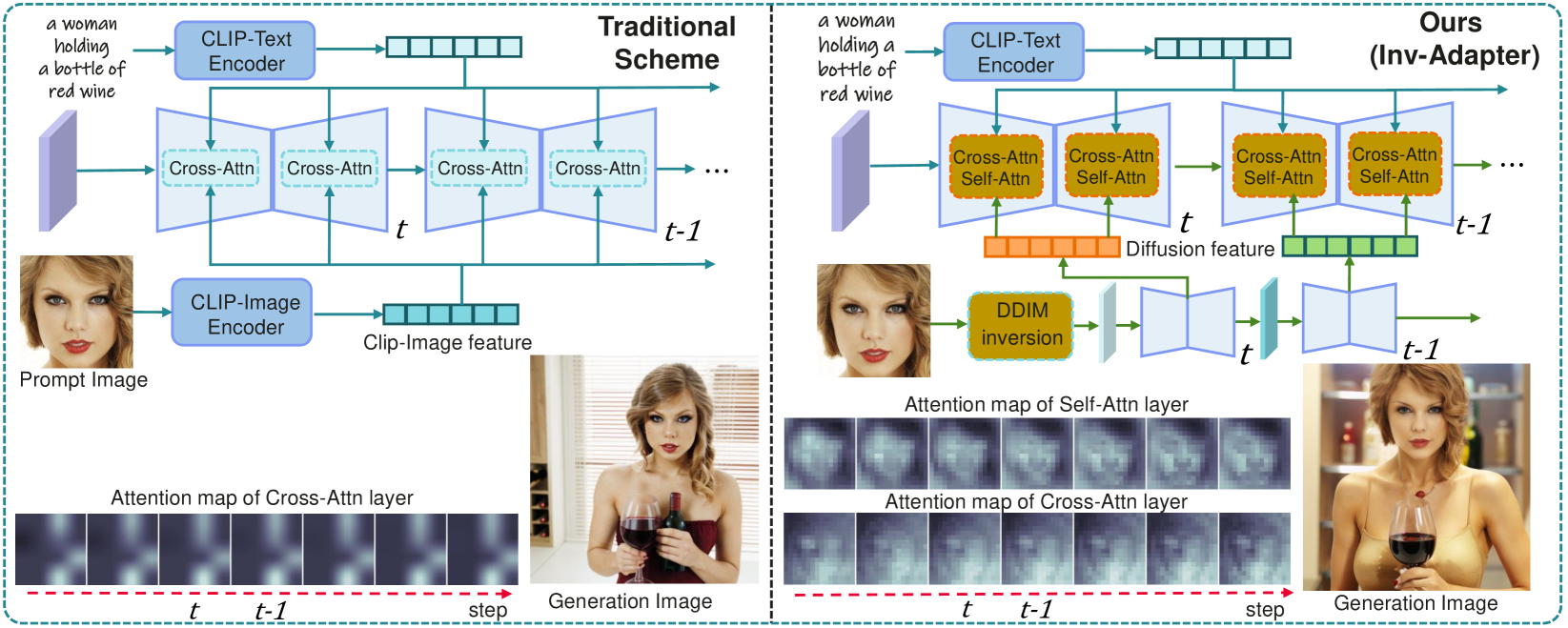
The paper presents a method called Inv-Adapter that allows you to customize ID images, like driver's licenses or ID cards, without having to retrain an entire image generation model from scratch. The key idea is to use a technique called "image inversion" to take a pre-trained image generation model and adapt it to produce personalized ID images.
Traditionally, if you wanted to generate customized ID images, you would need to retrain the entire image generation model with new data. This can be time-consuming and resource-intensive. Inv-Adapter offers a more efficient solution by using lightweight "adapter" networks that can be quickly trained on top of the pre-existing model.
The authors show that Inv-Adapter can work with a variety of different image generation models, including LocinV, Customization Assistant, and IterInv. This flexibility makes Inv-Adapter a versatile tool for personalizing ID images without the need for extensive retraining.
Technical Explanation
The Inv-Adapter method works by first inverting a pre-trained image generation model to obtain a personalized latent representation for a given input image. This latent representation is then used to train a lightweight "adapter" network that can generate customized ID images based on the user's preferences.
The key steps of the Inv-Adapter method are:
-
Image Inversion: The authors leverage techniques like I2V-Adapter and InvertAvatar to invert pre-trained image generation models and obtain personalized latent representations for input images.
-
Adapter Training: The personalized latent representations are used to train a lightweight adapter network that can generate customized ID images. This adapter network is much smaller and faster to train than retraining the entire image generation model.
-
Customization: Users can provide input images, and the Inv-Adapter method will generate personalized ID images based on the user's preferences, using the trained adapter network.
The authors evaluate Inv-Adapter on various image generation models and demonstrate its ability to generate high-quality, personalized ID images efficiently.
Critical Analysis
The Inv-Adapter method presents a promising approach for customizing ID images without the need for extensive retraining of large image generation models. However, the paper does not address some potential limitations and areas for further research:
-
Dataset and Bias: The paper does not provide details on the dataset used for training the Inv-Adapter models. It's essential to ensure that the training data is diverse and representative to avoid introducing biases into the generated ID images.
-
Security and Privacy Concerns: Generating personalized ID images raises potential security and privacy concerns, which the paper does not address. Further research is needed to ensure the robust and secure use of such technology.
-
Generalization to Other Applications: While the paper focuses on ID image customization, the Inv-Adapter approach could potentially be applied to other types of image customization tasks. Exploring the adaptability of this method to different domains could be an area of future research.
Overall, the Inv-Adapter method presents an interesting and efficient approach to ID image customization, but additional research is needed to address the potential limitations and expand the applications of this technology.
Conclusion
The Inv-Adapter method introduced in this paper offers a novel way to generate personalized ID images by leveraging image inversion and lightweight adapter networks. This approach allows for efficient customization of ID images without the need for retraining entire image generation models from scratch.
By demonstrating the versatility of Inv-Adapter across different image generation models, the authors have shown the potential of this method to be a valuable tool for various ID customization applications. However, further research is needed to address potential biases, security concerns, and explore the broader applicability of this approach beyond ID image generation.
Overall, the Inv-Adapter method represents an important step forward in personalized image generation, paving the way for more accessible and efficient customization solutions in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Inv-Adapter: ID Customization Generation via Image Inversion and Lightweight Adapter
Peng Xing, Ning Wang, Jianbo Ouyang, Zechao Li
The remarkable advancement in text-to-image generation models significantly boosts the research in ID customization generation. However, existing personalization methods cannot simultaneously satisfy high fidelity and high-efficiency requirements. Their main bottleneck lies in the prompt image encoder, which produces weak alignment signals with the text-to-image model and significantly increased model size. Towards this end, we propose a lightweight Inv-Adapter, which first extracts diffusion-domain representations of ID images utilizing a pre-trained text-to-image model via DDIM image inversion, without additional image encoder. Benefiting from the high alignment of the extracted ID prompt features and the intermediate features of the text-to-image model, we then embed them efficiently into the base text-to-image model by carefully designing a lightweight attention adapter. We conduct extensive experiments to assess ID fidelity, generation loyalty, speed, and training parameters, all of which show that the proposed Inv-Adapter is highly competitive in ID customization generation and model scale.
Read more6/7/2024

0
An Improved Method for Personalizing Diffusion Models
Yan Zeng, Masanori Suganuma, Takayuki Okatani
Diffusion models have demonstrated impressive image generation capabilities. Personalized approaches, such as textual inversion and Dreambooth, enhance model individualization using specific images. These methods enable generating images of specific objects based on diverse textual contexts. Our proposed approach aims to retain the model's original knowledge during new information integration, resulting in superior outcomes while necessitating less training time compared to Dreambooth and textual inversion.
Read more7/9/2024

0
LocInv: Localization-aware Inversion for Text-Guided Image Editing
Chuanming Tang, Kai Wang, Fei Yang, Joost van de Weijer
Large-scale Text-to-Image (T2I) diffusion models demonstrate significant generation capabilities based on textual prompts. Based on the T2I diffusion models, text-guided image editing research aims to empower users to manipulate generated images by altering the text prompts. However, existing image editing techniques are prone to editing over unintentional regions that are beyond the intended target area, primarily due to inaccuracies in cross-attention maps. To address this problem, we propose Localization-aware Inversion (LocInv), which exploits segmentation maps or bounding boxes as extra localization priors to refine the cross-attention maps in the denoising phases of the diffusion process. Through the dynamic updating of tokens corresponding to noun words in the textual input, we are compelling the cross-attention maps to closely align with the correct noun and adjective words in the text prompt. Based on this technique, we achieve fine-grained image editing over particular objects while preventing undesired changes to other regions. Our method LocInv, based on the publicly available Stable Diffusion, is extensively evaluated on a subset of the COCO dataset, and consistently obtains superior results both quantitatively and qualitatively.The code will be released at https://github.com/wangkai930418/DPL
Read more5/3/2024
0
SimInversion: A Simple Framework for Inversion-Based Text-to-Image Editing
Qi Qian, Haiyang Xu, Ming Yan, Juhua Hu
Diffusion models demonstrate impressive image generation performance with text guidance. Inspired by the learning process of diffusion, existing images can be edited according to text by DDIM inversion. However, the vanilla DDIM inversion is not optimized for classifier-free guidance and the accumulated error will result in the undesired performance. While many algorithms are developed to improve the framework of DDIM inversion for editing, in this work, we investigate the approximation error in DDIM inversion and propose to disentangle the guidance scale for the source and target branches to reduce the error while keeping the original framework. Moreover, a better guidance scale (i.e., 0.5) than default settings can be derived theoretically. Experiments on PIE-Bench show that our proposal can improve the performance of DDIM inversion dramatically without sacrificing efficiency.
Read more9/17/2024