Towards a Simultaneous and Granular Identity-Expression Control in Personalized Face Generation
2401.01207
0
0
🛸
Abstract
In human-centric content generation, the pre-trained text-to-image models struggle to produce user-wanted portrait images, which retain the identity of individuals while exhibiting diverse expressions. This paper introduces our efforts towards personalized face generation. To this end, we propose a novel multi-modal face generation framework, capable of simultaneous identity-expression control and more fine-grained expression synthesis. Our expression control is so sophisticated that it can be specialized by the fine-grained emotional vocabulary. We devise a novel diffusion model that can undertake the task of simultaneously face swapping and reenactment. Due to the entanglement of identity and expression, it's nontrivial to separately and precisely control them in one framework, thus has not been explored yet. To overcome this, we propose several innovative designs in the conditional diffusion model, including balancing identity and expression encoder, improved midpoint sampling, and explicitly background conditioning. Extensive experiments have demonstrated the controllability and scalability of the proposed framework, in comparison with state-of-the-art text-to-image, face swapping, and face reenactment methods.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Developing personalized face generation models that can control both identity and expression is a challenge in human-centric content generation.
- The paper introduces a novel multi-modal face generation framework that can simultaneously perform face swapping and reenactment while preserving identity and enabling fine-grained expression synthesis.
- The key innovations include a balanced identity-expression encoder, improved midpoint sampling, and explicit background conditioning in the conditional diffusion model.
Plain English Explanation
The paper tackles the problem of generating realistic portrait images that retain the identity of individuals while exhibiting diverse expressions. Existing text-to-image models often struggle with this task, as the identity and expression of a face are deeply intertwined.
The researchers propose a new framework that can simultaneously control both the identity and expression of a generated face. This allows for more personalized and expressive face generation, going beyond simple face swapping or reenactment. The framework can even capture fine-grained emotional states through its sophisticated expression control.
The key innovations include:
- Balanced identity-expression encoder: This helps the model separately and precisely control the identity and expression of the generated face.
- Improved midpoint sampling: This sampling technique improves the quality and controllability of the generated faces.
- Explicit background conditioning: This allows the model to generate faces with appropriate backgrounds, rather than just the face itself.
By incorporating these novel techniques, the researchers have developed a highly controllable and scalable face generation framework that outperforms state-of-the-art methods in text-to-image, face swapping, and face reenactment.
Technical Explanation
The paper introduces a multi-modal face generation framework that can simultaneously perform face swapping and face reenactment while preserving the identity of the individual and enabling fine-grained expression synthesis.
The key technical innovations include:
-
Balanced identity-expression encoder: To address the challenge of disentangling the entangled identity and expression, the researchers devised a balanced encoder that can separately and precisely control these two aspects of the generated face.
-
Improved midpoint sampling: The researchers developed an improved midpoint sampling technique in the conditional diffusion model, which enhances the quality and controllability of the generated faces.
-
Explicit background conditioning: The model is designed to generate faces with appropriate backgrounds, rather than just the face itself. This is achieved through explicit background conditioning in the diffusion model.
The researchers conducted extensive experiments to evaluate the proposed framework's controllability and scalability in comparison to state-of-the-art text-to-image, face swapping, and face reenactment methods. The results demonstrate the superiority of their approach in terms of both identity preservation and expressive face generation.
Critical Analysis
The paper presents a comprehensive and innovative solution to the challenge of generating personalized and expressive face images. The researchers have successfully addressed the key issue of disentangling identity and expression, which has been a long-standing problem in the field.
However, the paper does not discuss the potential ethical implications of such a powerful face generation system. There are concerns around the misuse of this technology for malicious purposes, such as creating fake identities or manipulating images for deception.
Additionally, the paper could have delved deeper into the limitations of the proposed framework, such as the computational resources required, the diversity of expressions it can handle, or the transferability of the model to different domains or demographics.
Overall, the research represents a significant advancement in the field of personalized face generation, but it also raises important ethical considerations that should be addressed in future work.
Conclusion
The paper introduces a novel multi-modal face generation framework that can simultaneously control both the identity and expression of generated faces. The key innovations, including a balanced identity-expression encoder, improved midpoint sampling, and explicit background conditioning, enable the framework to outperform state-of-the-art methods in terms of controllability and scalability.
This research represents a significant step forward in the development of personalized and expressive face generation models, with potential applications in areas such as digital content creation, virtual avatars, and image editing. However, the ethical implications of such powerful face generation technology must be carefully considered to ensure its responsible and beneficial use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
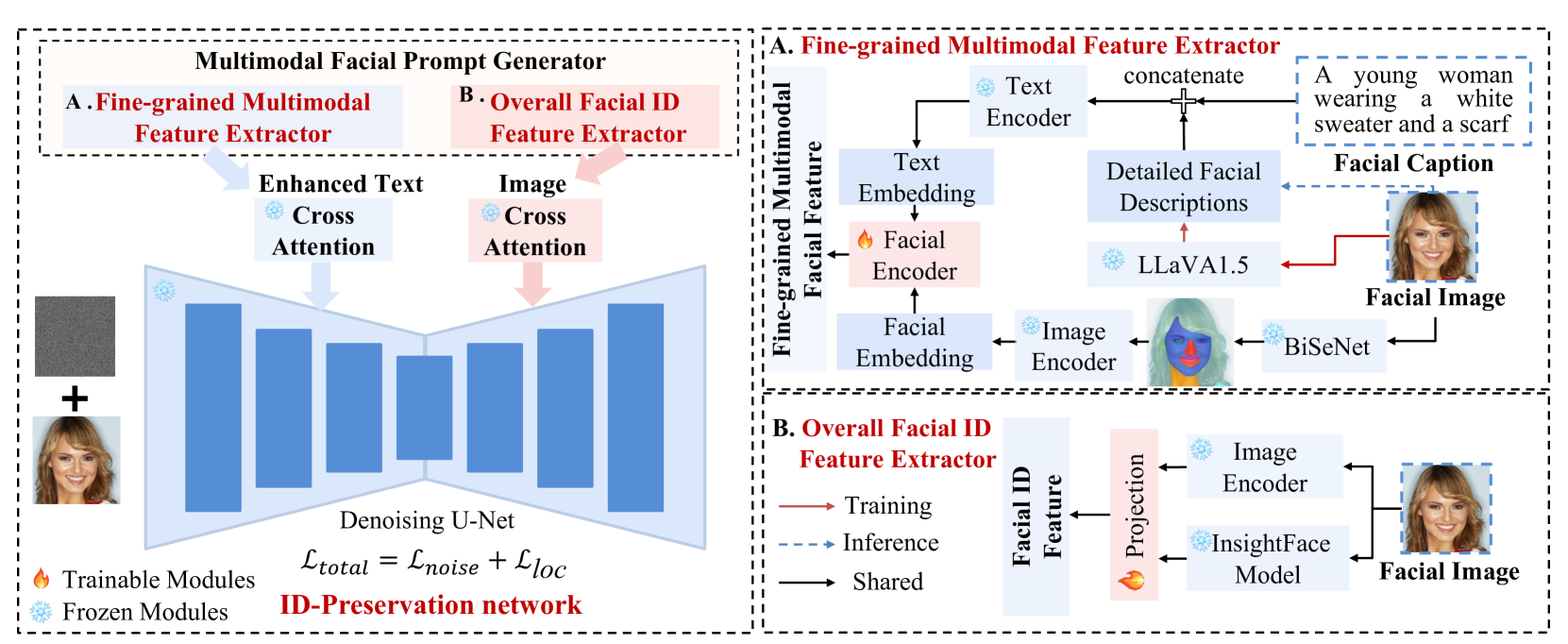
ConsistentID: Portrait Generation with Multimodal Fine-Grained Identity Preserving
Jiehui Huang, Xiao Dong, Wenhui Song, Hanhui Li, Jun Zhou, Yuhao Cheng, Shutao Liao, Long Chen, Yiqiang Yan, Shengcai Liao, Xiaodan Liang
0
0
Diffusion-based technologies have made significant strides, particularly in personalized and customized facialgeneration. However, existing methods face challenges in achieving high-fidelity and detailed identity (ID)consistency, primarily due to insufficient fine-grained control over facial areas and the lack of a comprehensive strategy for ID preservation by fully considering intricate facial details and the overall face. To address these limitations, we introduce ConsistentID, an innovative method crafted for diverseidentity-preserving portrait generation under fine-grained multimodal facial prompts, utilizing only a single reference image. ConsistentID comprises two key components: a multimodal facial prompt generator that combines facial features, corresponding facial descriptions and the overall facial context to enhance precision in facial details, and an ID-preservation network optimized through the facial attention localization strategy, aimed at preserving ID consistency in facial regions. Together, these components significantly enhance the accuracy of ID preservation by introducing fine-grained multimodal ID information from facial regions. To facilitate training of ConsistentID, we present a fine-grained portrait dataset, FGID, with over 500,000 facial images, offering greater diversity and comprehensiveness than existing public facial datasets. % such as LAION-Face, CelebA, FFHQ, and SFHQ. Experimental results substantiate that our ConsistentID achieves exceptional precision and diversity in personalized facial generation, surpassing existing methods in the MyStyle dataset. Furthermore, while ConsistentID introduces more multimodal ID information, it maintains a fast inference speed during generation.
4/26/2024
🛸
Listen, Disentangle, and Control: Controllable Speech-Driven Talking Head Generation
Changpeng Cai, Guinan Guo, Jiao Li, Junhao Su, Chenghao He, Jing Xiao, Yuanxu Chen, Lei Dai, Feiyu Zhu
0
0
Most earlier investigations on talking face generation have focused on the synchronization of lip motion and speech content. However, human head pose and facial emotions are equally important characteristics of natural human faces. While audio-driven talking face generation has seen notable advancements, existing methods either overlook facial emotions or are limited to specific individuals and cannot be applied to arbitrary subjects. In this paper, we propose a one-shot Talking Head Generation framework (SPEAK) that distinguishes itself from general Talking Face Generation by enabling emotional and postural control. Specifically, we introduce the Inter-Reconstructed Feature Disentanglement (IRFD) method to decouple human facial features into three latent spaces. We then design a face editing module that modifies speech content and facial latent codes into a single latent space. Subsequently, we present a novel generator that employs modified latent codes derived from the editing module to regulate emotional expression, head poses, and speech content in synthesizing facial animations. Extensive trials demonstrate that our method can generate realistic talking head with coordinated lip motions, authentic facial emotions, and smooth head movements. The demo video is available at the anonymous link: https://anonymous.4open.science/r/SPEAK-F56E
5/14/2024
🛸
TextGaze: Gaze-Controllable Face Generation with Natural Language
Hengfei Wang, Zhongqun Zhang, Yihua Cheng, Hyung Jin Chang
0
0
Generating face image with specific gaze information has attracted considerable attention. Existing approaches typically input gaze values directly for face generation, which is unnatural and requires annotated gaze datasets for training, thereby limiting its application. In this paper, we present a novel gaze-controllable face generation task. Our approach inputs textual descriptions that describe human gaze and head behavior and generates corresponding face images. Our work first introduces a text-of-gaze dataset containing over 90k text descriptions spanning a dense distribution of gaze and head poses. We further propose a gaze-controllable text-to-face method. Our method contains a sketch-conditioned face diffusion module and a model-based sketch diffusion module. We define a face sketch based on facial landmarks and eye segmentation map. The face diffusion module generates face images from the face sketch, and the sketch diffusion module employs a 3D face model to generate face sketch from text description. Experiments on the FFHQ dataset show the effectiveness of our method. We will release our dataset and code for future research.
4/29/2024
🖼️
From Parts to Whole: A Unified Reference Framework for Controllable Human Image Generation
Zehuan Huang, Hongxing Fan, Lipeng Wang, Lu Sheng
0
0
Recent advancements in controllable human image generation have led to zero-shot generation using structural signals (e.g., pose, depth) or facial appearance. Yet, generating human images conditioned on multiple parts of human appearance remains challenging. Addressing this, we introduce Parts2Whole, a novel framework designed for generating customized portraits from multiple reference images, including pose images and various aspects of human appearance. To achieve this, we first develop a semantic-aware appearance encoder to retain details of different human parts, which processes each image based on its textual label to a series of multi-scale feature maps rather than one image token, preserving the image dimension. Second, our framework supports multi-image conditioned generation through a shared self-attention mechanism that operates across reference and target features during the diffusion process. We enhance the vanilla attention mechanism by incorporating mask information from the reference human images, allowing for the precise selection of any part. Extensive experiments demonstrate the superiority of our approach over existing alternatives, offering advanced capabilities for multi-part controllable human image customization. See our project page at https://huanngzh.github.io/Parts2Whole/.
4/24/2024