Structure Matters: Tackling the Semantic Discrepancy in Diffusion Models for Image Inpainting
2403.19898
0
0

Abstract
Denoising diffusion probabilistic models for image inpainting aim to add the noise to the texture of image during the forward process and recover masked regions with unmasked ones of the texture via the reverse denoising process.Despite the meaningful semantics generation,the existing arts suffer from the semantic discrepancy between masked and unmasked regions, since the semantically dense unmasked texture fails to be completely degraded while the masked regions turn to the pure noise in diffusion process,leading to the large discrepancy between them.In this paper,we aim to answer how unmasked semantics guide texture denoising process;together with how to tackle the semantic discrepancy,to facilitate the consistent and meaningful semantics generation.To this end,we propose a novel structure-guided diffusion model named StrDiffusion,to reformulate the conventional texture denoising process under structure guidance to derive a simplified denoising objective for image inpainting,while revealing:1) the semantically sparse structure is beneficial to tackle semantic discrepancy in early stage, while dense texture generates reasonable semantics in late stage;2) the semantics from unmasked regions essentially offer the time-dependent structure guidance for the texture denoising process,benefiting from the time-dependent sparsity of the structure semantics.For the denoising process,a structure-guided neural network is trained to estimate the simplified denoising objective by exploiting the consistency of the denoised structure between masked and unmasked regions.Besides,we devise an adaptive resampling strategy as a formal criterion as whether structure is competent to guide the texture denoising process,while regulate their semantic correlations.Extensive experiments validate the merits of StrDiffusion over the state-of-the-arts.Our code is available at https://github.com/htyjers/StrDiffusion.
Create account to get full access
Overview
- This research paper proposes a new approach to image inpainting using diffusion models.
- The key insight is that existing diffusion models can struggle to capture the semantic structure of images, leading to suboptimal inpainting results.
- The paper introduces a "Structure-Guided Texture Diffusion" (SGTD) model that aims to better preserve the structural and semantic properties of images during the inpainting process.
Plain English Explanation
Image inpainting is the task of filling in missing or corrupted regions of an image in a visually plausible way. Diffusion models, a type of generative AI model, have shown promising results for this task. However, the paper argues that existing diffusion models can sometimes struggle to capture the high-level semantic structure of images, leading to inpainted regions that may look realistic in isolation but don't fit well with the overall image context.
The Structure-Guided Texture Diffusion (SGTD) model proposed in this paper aims to address this issue by incorporating additional guidance from a structural representation of the image. The key idea is to use a separate network to extract a semantic "structure map" from the image, and then use this map to guide the diffusion process and ensure that the inpainted regions are semantically consistent with the rest of the image.
The paper demonstrates that this structure-guided approach can lead to significant improvements in image inpainting quality compared to existing diffusion-based methods, particularly for challenging cases where the missing regions are large or involve complex semantic structures. This work highlights the importance of accounting for high-level image semantics when using generative models for tasks like inpainting.
Technical Explanation
The paper first provides background on diffusion models and their use for image inpainting. Diffusion models work by gradually adding noise to an image, then learning to reverse this noising process to generate new images. While effective, the paper argues that standard diffusion models can struggle to capture the semantic structure of images, leading to inconsistencies in the inpainted regions.
To address this, the Structure-Guided Texture Diffusion (SGTD) model introduces two key innovations:
-
Structure Encoder: A separate neural network is used to extract a semantic "structure map" from the input image. This map encodes information about the high-level objects, textures, and spatial relationships in the image.
-
Structure-Guided Diffusion: The structure map is then used to guide the diffusion process, ensuring that the inpainted regions are consistent with the overall semantic structure of the image. This is achieved by incorporating the structure map as additional input to the diffusion model.
The paper evaluates the SGTD model on several image inpainting benchmarks and shows that it outperforms existing diffusion-based methods, particularly for large, semantically complex inpainting tasks. The authors attribute these improvements to the model's ability to better preserve the structural integrity of the image during the inpainting process.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the SGTD model, with comparisons to several state-of-the-art baselines on both quantitative and qualitative metrics. The proposed approach seems to offer a meaningful improvement over existing diffusion-based inpainting methods, particularly for challenging cases.
One potential limitation is that the reliance on a separate structure encoder network adds additional complexity and computational cost to the model. The authors do not provide an in-depth analysis of the computational overhead or runtime requirements of their approach compared to simpler diffusion-only models.
Additionally, the paper focuses primarily on evaluating the SGTD model on standard image inpainting benchmarks, but does not explore its generalization to other related tasks, such as unsupervised zero-shot segmentation or localized shape editing. Exploring the broader applicability of the structure-guided diffusion approach could be a fruitful avenue for future research.
Conclusion
This paper presents an innovative approach to image inpainting using a "Structure-Guided Texture Diffusion" (SGTD) model. By incorporating a separate structure encoder to guide the diffusion process, the SGTD model is able to better preserve the semantic integrity of inpainted regions, leading to significant improvements in inpainting quality compared to existing diffusion-based methods.
The work highlights the importance of considering high-level image semantics when using generative models for tasks like inpainting, and provides a promising new direction for further research in this area. While the additional complexity introduced by the structure encoder may be a limitation, the paper demonstrates the potential benefits of this structure-guided approach, which could inspire future advancements in diffusion models and their applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Image Inpainting via Conditional Texture and Structure Dual Generation
Xiefan Guo, Hongyu Yang, Di Huang
0
0
Deep generative approaches have recently made considerable progress in image inpainting by introducing structure priors. Due to the lack of proper interaction with image texture during structure reconstruction, however, current solutions are incompetent in handling the cases with large corruptions, and they generally suffer from distorted results. In this paper, we propose a novel two-stream network for image inpainting, which models the structure-constrained texture synthesis and texture-guided structure reconstruction in a coupled manner so that they better leverage each other for more plausible generation. Furthermore, to enhance the global consistency, a Bi-directional Gated Feature Fusion (Bi-GFF) module is designed to exchange and combine the structure and texture information and a Contextual Feature Aggregation (CFA) module is developed to refine the generated contents by region affinity learning and multi-scale feature aggregation. Qualitative and quantitative experiments on the CelebA, Paris StreetView and Places2 datasets demonstrate the superiority of the proposed method. Our code is available at https://github.com/Xiefan-Guo/CTSDG.
4/9/2024
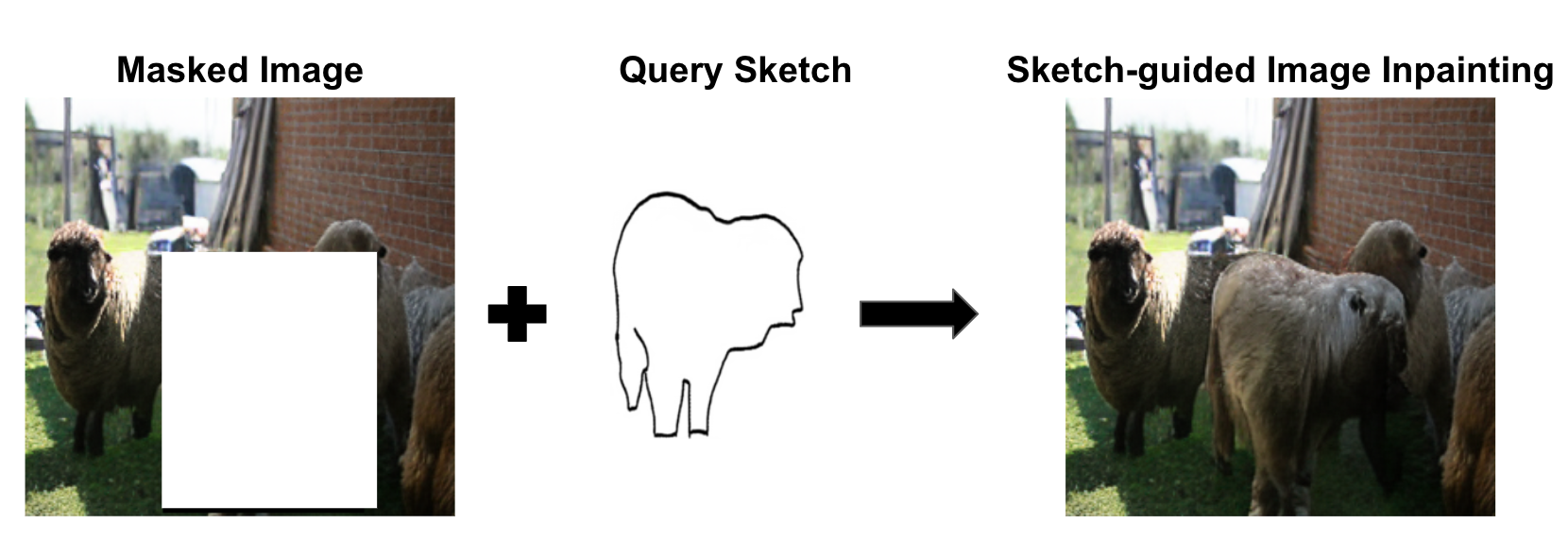
Sketch-guided Image Inpainting with Partial Discrete Diffusion Process
Nakul Sharma, Aditay Tripathi, Anirban Chakraborty, Anand Mishra
0
0
In this work, we study the task of sketch-guided image inpainting. Unlike the well-explored natural language-guided image inpainting, which excels in capturing semantic details, the relatively less-studied sketch-guided inpainting offers greater user control in specifying the object's shape and pose to be inpainted. As one of the early solutions to this task, we introduce a novel partial discrete diffusion process (PDDP). The forward pass of the PDDP corrupts the masked regions of the image and the backward pass reconstructs these masked regions conditioned on hand-drawn sketches using our proposed sketch-guided bi-directional transformer. The proposed novel transformer module accepts two inputs -- the image containing the masked region to be inpainted and the query sketch to model the reverse diffusion process. This strategy effectively addresses the domain gap between sketches and natural images, thereby, enhancing the quality of inpainting results. In the absence of a large-scale dataset specific to this task, we synthesize a dataset from the MS-COCO to train and extensively evaluate our proposed framework against various competent approaches in the literature. The qualitative and quantitative results and user studies establish that the proposed method inpaints realistic objects that fit the context in terms of the visual appearance of the provided sketch. To aid further research, we have made our code publicly available at https://github.com/vl2g/Sketch-Inpainting .
4/19/2024

New!Using diffusion model as constraint: Empower Image Restoration Network Training with Diffusion Model
Jiangtong Tan, Feng Zhao
0
0
Image restoration has made marvelous progress with the advent of deep learning. Previous methods usually rely on designing powerful network architecture to elevate performance, however, the natural visual effect of the restored results is limited by color and texture distortions. Besides the visual perceptual quality, the semantic perception recovery is an important but often overlooked perspective of restored image, which is crucial for the deployment in high-level tasks. In this paper, we propose a new perspective to resort these issues by introducing a naturalness-oriented and semantic-aware optimization mechanism, dubbed DiffLoss. Specifically, inspired by the powerful distribution coverage capability of the diffusion model for natural image generation, we exploit the Markov chain sampling property of diffusion model and project the restored results of existing networks into the sampling space. Besides, we reveal that the bottleneck feature of diffusion models, also dubbed h-space feature, is a natural high-level semantic space. We delve into this property and propose a semantic-aware loss to further unlock its potential of semantic perception recovery, which paves the way to connect image restoration task and downstream high-level recognition task. With these two strategies, the DiffLoss can endow existing restoration methods with both more natural and semantic-aware results. We verify the effectiveness of our method on substantial common image restoration tasks and benchmarks. Code will be available at https://github.com/JosephTiTan/DiffLoss.
6/28/2024
📶
Semantically Consistent Video Inpainting with Conditional Diffusion Models
Dylan Green, William Harvey, Saeid Naderiparizi, Matthew Niedoba, Yunpeng Liu, Xiaoxuan Liang, Jonathan Lavington, Ke Zhang, Vasileios Lioutas, Setareh Dabiri, Adam Scibior, Berend Zwartsenberg, Frank Wood
0
0
Current state-of-the-art methods for video inpainting typically rely on optical flow or attention-based approaches to inpaint masked regions by propagating visual information across frames. While such approaches have led to significant progress on standard benchmarks, they struggle with tasks that require the synthesis of novel content that is not present in other frames. In this paper we reframe video inpainting as a conditional generative modeling problem and present a framework for solving such problems with conditional video diffusion models. We highlight the advantages of using a generative approach for this task, showing that our method is capable of generating diverse, high-quality inpaintings and synthesizing new content that is spatially, temporally, and semantically consistent with the provided context.
5/2/2024