Structured Pruning for Efficient Visual Place Recognition

0

Sign in to get full access
Overview
- Structured pruning for efficient visual place recognition
- Improves performance of visual place recognition models while reducing model size and inference time
- Leverages structured pruning to selectively remove less important parameters from the model
Plain English Explanation
The paper presents a technique called structured pruning to make visual place recognition models more efficient. Visual place recognition is the task of identifying a specific location or place based on visual information, such as images or video. This is an important capability for applications like robot navigation and autonomous driving.
The key idea behind structured pruning is to
The researchers show that by applying structured pruning, they can reduce the model size and inference time of visual place recognition models
Technical Explanation
The paper proposes a structured pruning approach to improve the efficiency of visual place recognition models. Structured pruning involves
The authors first train a baseline visual place recognition model using a large dataset of images. They then apply structured pruning to this model,
The researchers evaluate their approach on several popular visual place recognition benchmarks, including Oxford RobotCar and Nordland. Their results show that the pruned models
Critical Analysis
The paper provides a valuable contribution to the field of visual place recognition by demonstrating the effectiveness of structured pruning in improving model efficiency. The authors' key insight is that
However, the paper does not address some potential limitations of their approach. For example, the authors do not explore how the structured pruning technique might perform on
Furthermore, the paper does not
Conclusion
The paper presents a structured pruning approach to improve the efficiency of visual place recognition models. By
This work has important implications for the deployment of visual place recognition models in real-world applications, such as robot navigation and autonomous driving, where model size and inference speed are critical factors. The proposed technique could help make these models more practical and accessible for a wider range of use cases.
Overall, the paper provides a compelling demonstration of the potential of structured pruning to enhance the efficiency of visual place recognition models, and it opens up avenues for further research in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Structured Pruning for Efficient Visual Place Recognition
Oliver Grainge, Michael Milford, Indu Bodala, Sarvapali D. Ramchurn, Shoaib Ehsan
Visual Place Recognition (VPR) is fundamental for the global re-localization of robots and devices, enabling them to recognize previously visited locations based on visual inputs. This capability is crucial for maintaining accurate mapping and localization over large areas. Given that VPR methods need to operate in real-time on embedded systems, it is critical to optimize these systems for minimal resource consumption. While the most efficient VPR approaches employ standard convolutional backbones with fixed descriptor dimensions, these often lead to redundancy in the embedding space as well as in the network architecture. Our work introduces a novel structured pruning method, to not only streamline common VPR architectures but also to strategically remove redundancies within the feature embedding space. This dual focus significantly enhances the efficiency of the system, reducing both map and model memory requirements and decreasing feature extraction and retrieval latencies. Our approach has reduced memory usage and latency by 21% and 16%, respectively, across models, while minimally impacting recall@1 accuracy by less than 1%. This significant improvement enhances real-time applications on edge devices with negligible accuracy loss.
Read more9/14/2024

0
Register assisted aggregation for Visual Place Recognition
Xuan Yu, Zhenyong Fu
Visual Place Recognition (VPR) refers to the process of using computer vision to recognize the position of the current query image. Due to the significant changes in appearance caused by season, lighting, and time spans between query images and database images for retrieval, these differences increase the difficulty of place recognition. Previous methods often discarded useless features (such as sky, road, vehicles) while uncontrolled discarding features that help improve recognition accuracy (such as buildings, trees). To preserve these useful features, we propose a new feature aggregation method to address this issue. Specifically, in order to obtain global and local features that contain discriminative place information, we added some registers on top of the original image tokens to assist in model training. After reallocating attention weights, these registers were discarded. The experimental results show that these registers surprisingly separate unstable features from the original image representation and outperform state-of-the-art methods.
Read more5/21/2024

0
BEV$^2$PR: BEV-Enhanced Visual Place Recognition with Structural Cues
Fudong Ge, Yiwei Zhang, Shuhan Shen, Yue Wang, Weiming Hu, Jin Gao
In this paper, we propose a new image-based visual place recognition (VPR) framework by exploiting the structural cues in bird's-eye view (BEV) from a single monocular camera. The motivation arises from two key observations about place recognition methods based on both appearance and structure: 1) For the methods relying on LiDAR sensors, the integration of LiDAR in robotic systems has led to increased expenses, while the alignment of data between different sensors is also a major challenge. 2) Other image-/camera-based methods, involving integrating RGB images and their derived variants (eg, pseudo depth images, pseudo 3D point clouds), exhibit several limitations, such as the failure to effectively exploit the explicit spatial relationships between different objects. To tackle the above issues, we design a new BEV-enhanced VPR framework, namely BEV$^2$PR, generating a composite descriptor with both visual cues and spatial awareness based on a single camera. The key points lie in: 1) We use BEV features as an explicit source of structural knowledge in constructing global features. 2) The lower layers of the pre-trained backbone from BEV generation are shared for visual and structural streams in VPR, facilitating the learning of fine-grained local features in the visual stream. 3) The complementary visual and structural features can jointly enhance VPR performance. Our BEV$^2$PR framework enables consistent performance improvements over several popular aggregation modules for RGB global features. The experiments on our collected VPR-NuScenes dataset demonstrate an absolute gain of 2.47% on Recall@1 for the strong Conv-AP baseline to achieve the best performance in our setting, and notably, a 18.06% gain on the hard set. The code and dataset will be available at https://github.com/FudongGe/BEV2PR.
Read more7/24/2024
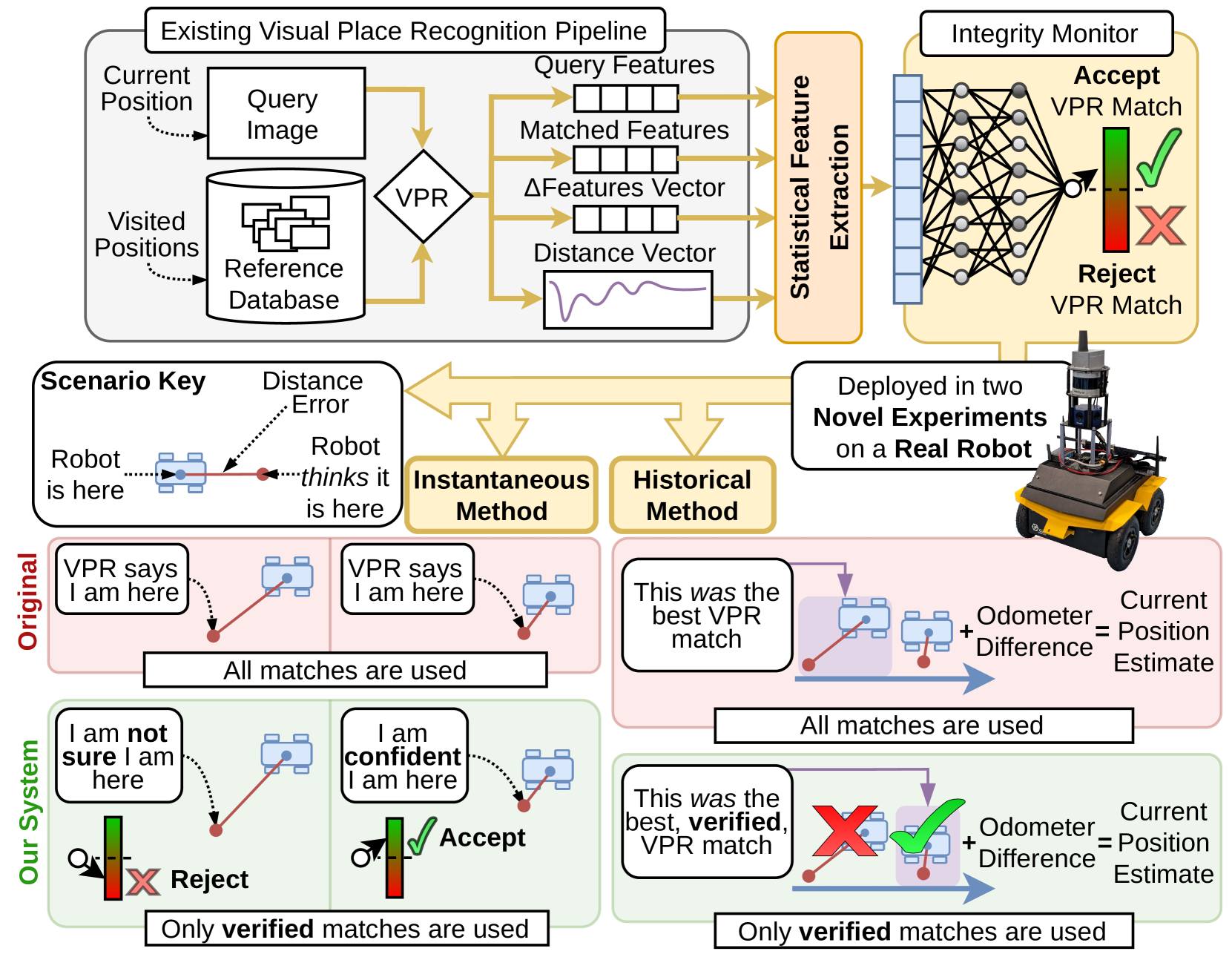
0
Improving Visual Place Recognition Based Robot Navigation Through Verification of Localization Estimates
Owen Claxton, Connor Malone, Helen Carson, Jason Ford, Gabe Bolton, Iman Shames, Michael Milford
Visual Place Recognition (VPR) systems often have imperfect performance, which affects robot navigation decisions. This research introduces a novel Multi-Layer Perceptron (MLP) integrity monitor for VPR which demonstrates improved performance and generalizability over the previous state-of-the-art SVM approach, removing per-environment training and reducing manual tuning requirements. We test our proposed system in extensive real-world experiments, where we also present two real-time integrity-based VPR verification methods: an instantaneous rejection method for a robot navigating to a goal zone (Experiment 1); and a historical method that takes a best, verified, match from its recent trajectory and uses an odometer to extrapolate forwards to a current position estimate (Experiment 2). Noteworthy results for Experiment 1 include a decrease in aggregate mean along-track goal error from ~9.8m to ~3.1m in missions the robot pursued to completion, and an increase in the aggregate rate of successful mission completion from ~41% to ~55%. Experiment 2 showed a decrease in aggregate mean along-track localization error from ~2.0m to ~0.5m, and an increase in the aggregate precision of localization attempts from ~97% to ~99%. Overall, our results demonstrate the practical usefulness of a VPR integrity monitor in real-world robotics to improve VPR localization and consequent navigation performance.
Read more7/12/2024